 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAG-MoE: From Simple Mixture to Structural Aggregation in Mixture-of-Experts
May 31, 2026Mixture-of-Experts (MoE) models have become a leading approach for decoupling parameter count from computational cost in large language models, yet effectively scaling MoE performance remains a challenge. Prior work shows that fine-grained experts enlarge the space of expert combinations and improve flexibility, but they also impose substantial routing overhead, creating a new scalability bottleneck. In this paper, we explore a complementary axis for scaling -- how expert outputs are aggregated. We theoretically show that replacing the standard weighted-summation aggregation with structural aggregation expands the expert-combination space without altering the experts or router, and enables possible multi-step reasoning within a single MoE layer. To this end, we propose DAG-MoE, a sparse MoE framework that employs a lightweight module to automatically learn the optimal aggregation structure among the selected experts. Extensive experiments under standard language modeling settings show that DAG-MoE consistently improves performance in both pretraining and fine-tuning, surpassing traditional MoE baselines.
ReMix: Reinforcement routing for mixtures of LoRAs in LLM finetuning
Mar 10, 2026Low-rank adapters (LoRAs) are a parameter-efficient finetuning technique that injects trainable low-rank matrices into pretrained models to adapt them to new tasks. Mixture-of-LoRAs models expand neural networks efficiently by routing each layer input to a small subset of specialized LoRAs of the layer. Existing Mixture-of-LoRAs routers assign a learned routing weight to each LoRA to enable end-to-end training of the router. Despite their empirical promise, we observe that the routing weights are typically extremely imbalanced across LoRAs in practice, where only one or two LoRAs often dominate the routing weights. This essentially limits the number of effective LoRAs and thus severely hinders the expressive power of existing Mixture-of-LoRAs models. In this work, we attribute this weakness to the nature of learnable routing weights and rethink the fundamental design of the router. To address this critical issue, we propose a new router designed that we call Reinforcement Routing for Mixture-of-LoRAs (ReMix). Our key idea is using non-learnable routing weights to ensure all active LoRAs to be equally effective, with no LoRA dominating the routing weights. However, our routers cannot be trained directly via gradient descent due to our non-learnable routing weights. Hence, we further propose an unbiased gradient estimator for the router by employing the reinforce leave-one-out (RLOO) technique, where we regard the supervision loss as the reward and the router as the policy in reinforcement learning. Our gradient estimator also enables to scale up training compute to boost the predictive performance of our ReMix. Extensive experiments demonstrate that our proposed ReMix significantly outperform state-of-the-art parameter-efficient finetuning methods under a comparable number of activated parameters.
TabDLM: Free-Form Tabular Data Generation via Joint Numerical-Language Diffusion
Feb 26, 2026Synthetic tabular data generation has attracted growing attention due to its importance for data augmentation, foundation models, and privacy. However, real-world tabular datasets increasingly contain free-form text fields (e.g., reviews or clinical notes) alongside structured numerical and categorical attributes. Generating such heterogeneous tables with joint modeling of different modalities remains challenging. Existing approaches broadly fall into two categories: diffusion-based methods and LLM-based methods. Diffusion models can capture complex dependencies over numerical and categorical features in continuous or discrete spaces, but extending them to open-ended text is nontrivial and often leads to degraded text quality. In contrast, LLM-based generators naturally produce fluent text, yet their discrete tokenization can distort precise or wide-range numerical values, hindering accurate modeling of both numbers and language. In this work, we propose TabDLM, a unified framework for free-form tabular data generation via a joint numerical--language diffusion model built on masked diffusion language models (MDLMs). TabDLM models textual and categorical features through masked diffusion, while modeling numerical features with a continuous diffusion process through learned specialized numeric tokens embedding; bidirectional attention then captures cross-modality interactions within a single model. Extensive experiments on diverse benchmarks demonstrate the effectiveness of TabDLM compared to strong diffusion- and LLM-based baselines.
GRIP: In-Parameter Graph Reasoning through Fine-Tuning Large Language Models
Nov 06, 2025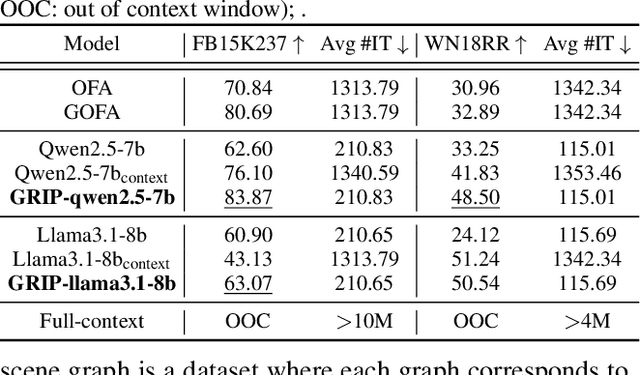
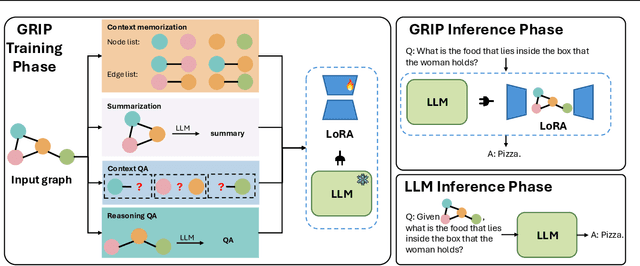
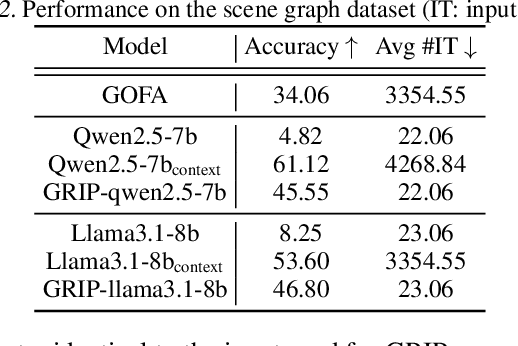
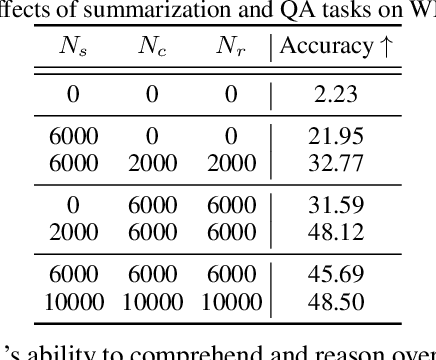
Large Language Models (LLMs) have demonstrated remarkable capabilities in modeling sequential textual data and generalizing across diverse tasks. However, adapting LLMs to effectively handle structural data, such as knowledge graphs or web data, remains a challenging problem. Some approaches adopt complex strategies to convert graphs into text sequences, resulting in significant token overhead and rendering them impractical for large-scale graphs. Others introduce additional modules to encode graphs into fixed-size token representations for LLMs. However, these methods typically require large-scale post-training on graph-text corpus and complex alignment procedures, yet often yield sub-optimal results due to poor modality alignment. Inspired by in-parameter knowledge injection for test-time adaptation of LLMs, we propose GRIP, a novel framework that equips LLMs with the ability to internalize complex relational information from graphs through carefully designed fine-tuning tasks. This knowledge is efficiently stored within lightweight LoRA parameters, enabling the fine-tuned LLM to perform a wide range of graph-related tasks without requiring access to the original graph at inference time. Extensive experiments across multiple benchmarks validate the effectiveness and efficiency of our approach.
Addressing accuracy and hallucination of LLMs in Alzheimer's disease research through knowledge graphs
Aug 28, 2025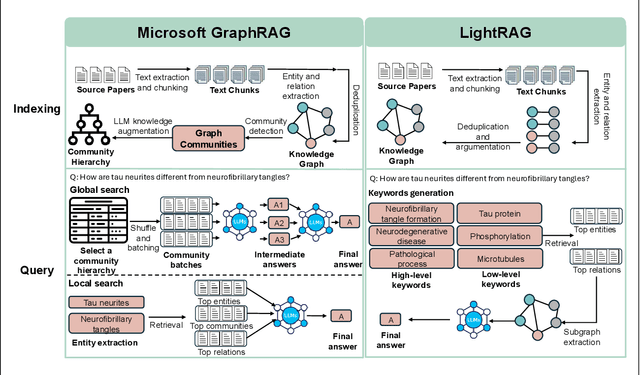
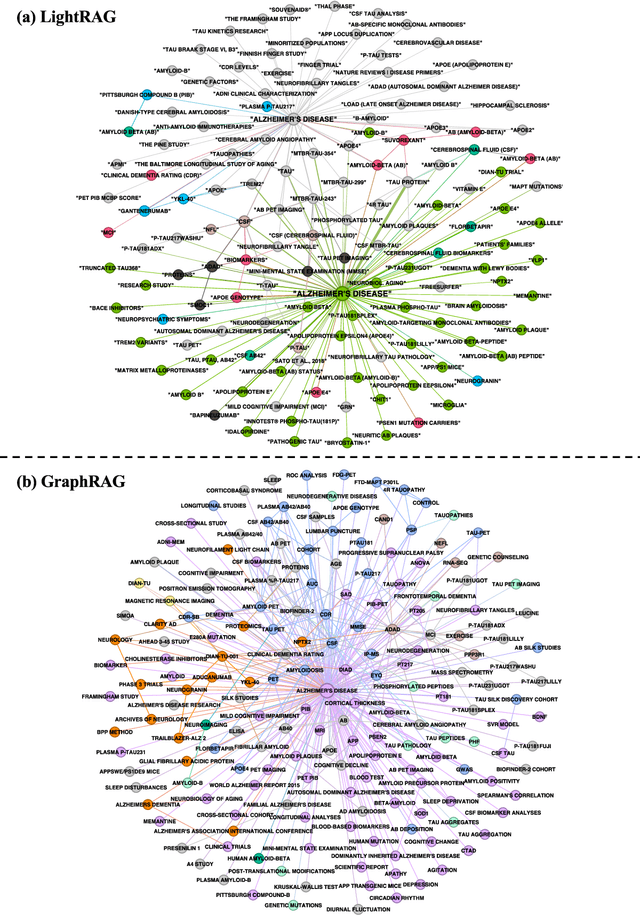


In the past two years, large language model (LLM)-based chatbots, such as ChatGPT, have revolutionized various domains by enabling diverse task completion and question-answering capabilities. However, their application in scientific research remains constrained by challenges such as hallucinations, limited domain-specific knowledge, and lack of explainability or traceability for the response. Graph-based Retrieval-Augmented Generation (GraphRAG) has emerged as a promising approach to improving chatbot reliability by integrating domain-specific contextual information before response generation, addressing some limitations of standard LLMs. Despite its potential, there are only limited studies that evaluate GraphRAG on specific domains that require intensive knowledge, like Alzheimer's disease or other biomedical domains. In this paper, we assess the quality and traceability of two popular GraphRAG systems. We compile a database of 50 papers and 70 expert questions related to Alzheimer's disease, construct a GraphRAG knowledge base, and employ GPT-4o as the LLM for answering queries. We then compare the quality of responses generated by GraphRAG with those from a standard GPT-4o model. Additionally, we discuss and evaluate the traceability of several Retrieval-Augmented Generation (RAG) and GraphRAG systems. Finally, we provide an easy-to-use interface with a pre-built Alzheimer's disease database for researchers to test the performance of both standard RAG and GraphRAG.
GOFA: A Generative One-For-All Model for Joint Graph Language Modeling
Jul 12, 2024



Foundation models, such as Large Language Models (LLMs) or Large Vision Models (LVMs), have emerged as one of the most powerful tools in the respective fields. However, unlike text and image data, graph data do not have a definitive structure, posing great challenges to developing a Graph Foundation Model (GFM). For example, current attempts at designing general graph models either transform graph data into a language format for LLM-based prediction or still train a GNN model with LLM as an assistant. The former can handle unlimited tasks, while the latter captures graph structure much better -- yet, no existing work can achieve both simultaneously. In this paper, we identify three key desirable properties of a GFM: self-supervised pretraining, fluidity in tasks, and graph awareness. To account for these properties, we extend the conventional language modeling to the graph domain and propose a novel generative graph language model GOFA to solve the problem. The model interleaves randomly initialized GNN layers into a frozen pre-trained LLM so that the semantic and structural modeling abilities are organically combined. GOFA is pre-trained on newly proposed graph-level next-word prediction, question-answering, and structural tasks to obtain the above GFM properties. The pre-trained model is further fine-tuned on downstream tasks to obtain task-solving ability. The fine-tuned model is evaluated on various downstream tasks, demonstrating a strong ability to solve structural and contextual problems in zero-shot scenarios. The code is available at https://github.com/JiaruiFeng/GOFA.
TAGLAS: An atlas of text-attributed graph datasets in the era of large graph and language models
Jun 20, 2024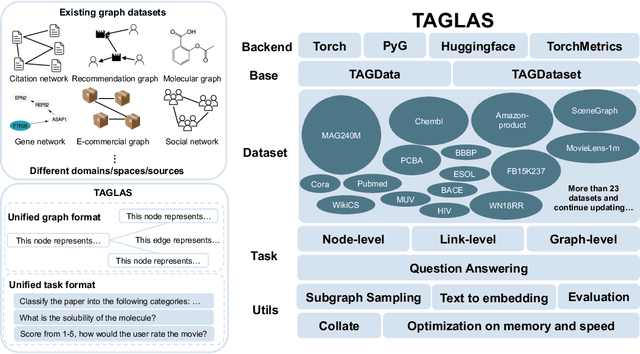
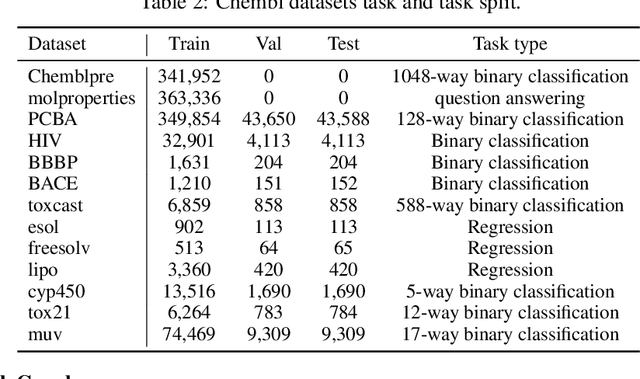
In this report, we present TAGLAS, an atlas of text-attributed graph (TAG) datasets and benchmarks. TAGs are graphs with node and edge features represented in text, which have recently gained wide applicability in training graph-language or graph foundation models. In TAGLAS, we collect and integrate more than 23 TAG datasets with domains ranging from citation graphs to molecule graphs and tasks from node classification to graph question-answering. Unlike previous graph datasets and benchmarks, all datasets in TAGLAS have a unified node and edge text feature format, which allows a graph model to be simultaneously trained and evaluated on multiple datasets from various domains. Further, we provide a standardized, efficient, and simplified way to load all datasets and tasks. We also provide useful utils like text-to-embedding conversion, and graph-to-text conversion, which can facilitate different evaluation scenarios. Finally, we also provide standard and easy-to-use evaluation utils. The project is open-sourced at https://github.com/JiaruiFeng/TAGLAS and is still under construction. Please expect more datasets/features in the future.
Can Graph Learning Improve Task Planning?
May 29, 2024Task planning is emerging as an important research topic alongside the development of large language models (LLMs). It aims to break down complex user requests into solvable sub-tasks, thereby fulfilling the original requests. In this context, the sub-tasks can be naturally viewed as a graph, where the nodes represent the sub-tasks, and the edges denote the dependencies among them. Consequently, task planning is a decision-making problem that involves selecting a connected path or subgraph within the corresponding graph and invoking it. In this paper, we explore graph learning-based methods for task planning, a direction that is orthogonal to the prevalent focus on prompt design. Our interest in graph learning stems from a theoretical discovery: the biases of attention and auto-regressive loss impede LLMs' ability to effectively navigate decision-making on graphs, which is adeptly addressed by graph neural networks (GNNs). This theoretical insight led us to integrate GNNs with LLMs to enhance overall performance. Extensive experiments demonstrate that GNN-based methods surpass existing solutions even without training, and minimal training can further enhance their performance. Additionally, our approach complements prompt engineering and fine-tuning techniques, with performance further enhanced by improved prompts or a fine-tuned model.
MAG-GNN: Reinforcement Learning Boosted Graph Neural Network
Oct 29, 2023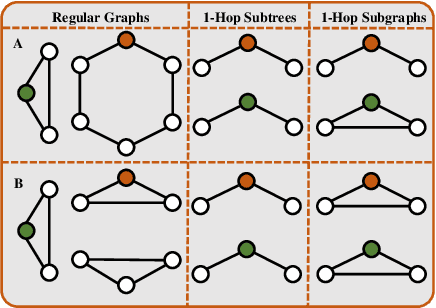
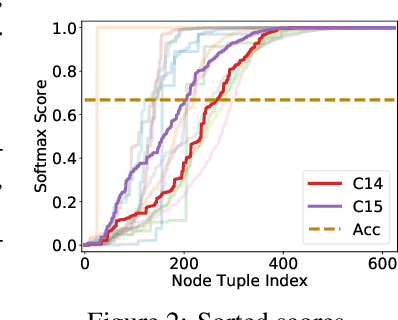
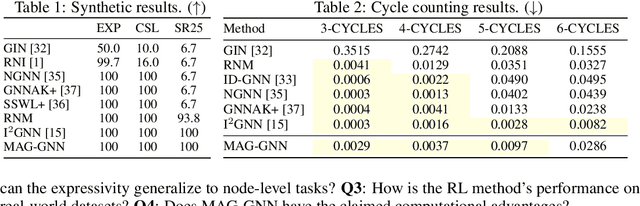
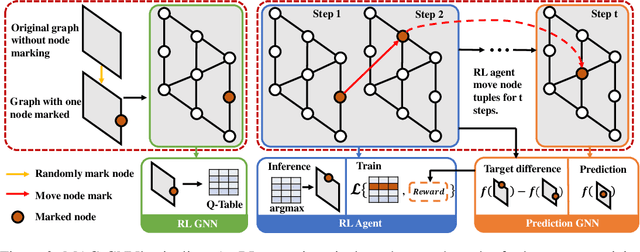
While Graph Neural Networks (GNNs) recently became powerful tools in graph learning tasks, considerable efforts have been spent on improving GNNs' structural encoding ability. A particular line of work proposed subgraph GNNs that use subgraph information to improve GNNs' expressivity and achieved great success. However, such effectivity sacrifices the efficiency of GNNs by enumerating all possible subgraphs. In this paper, we analyze the necessity of complete subgraph enumeration and show that a model can achieve a comparable level of expressivity by considering a small subset of the subgraphs. We then formulate the identification of the optimal subset as a combinatorial optimization problem and propose Magnetic Graph Neural Network (MAG-GNN), a reinforcement learning (RL) boosted GNN, to solve the problem. Starting with a candidate subgraph set, MAG-GNN employs an RL agent to iteratively update the subgraphs to locate the most expressive set for prediction. This reduces the exponential complexity of subgraph enumeration to the constant complexity of a subgraph search algorithm while keeping good expressivity. We conduct extensive experiments on many datasets, showing that MAG-GNN achieves competitive performance to state-of-the-art methods and even outperforms many subgraph GNNs. We also demonstrate that MAG-GNN effectively reduces the running time of subgraph GNNs.
One for All: Towards Training One Graph Model for All Classification Tasks
Sep 29, 2023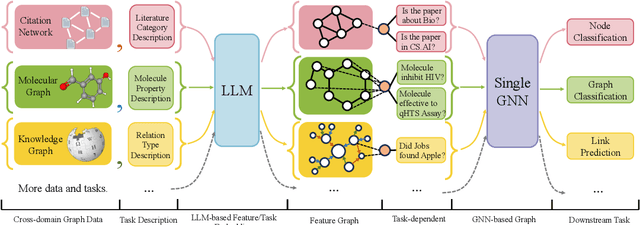
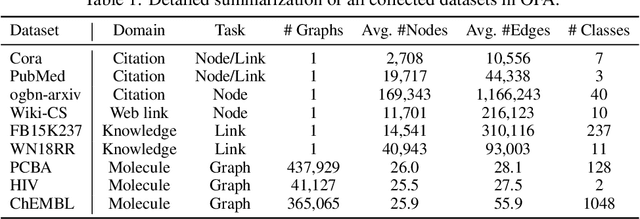
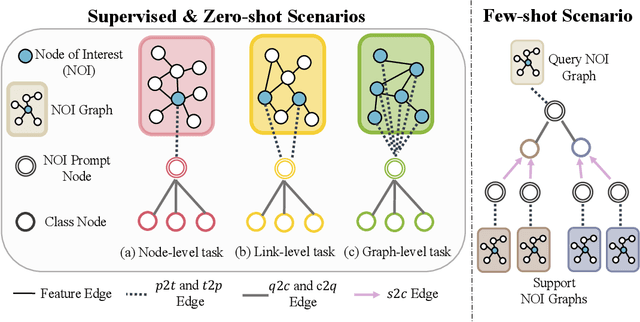

Designing a single model that addresses multiple tasks has been a long-standing objective in artificial intelligence. Recently, large language models have demonstrated exceptional capability in integrating and solving different tasks within the language domain. However, a unified model for various tasks on graphs remains underexplored, primarily due to the challenges unique to the graph learning domain. First, graph data from different areas carry distinct attributes and follow different distributions. Such discrepancy makes it hard to represent graphs in a single representation space. Second, tasks on graphs diversify into node, link, and graph tasks, requiring distinct embedding strategies. Finally, an appropriate graph prompting paradigm for in-context learning is unclear. Striving to handle all the aforementioned challenges, we propose One for All (OFA), the first general framework that can use a single graph model to address the above challenges. Specifically, OFA proposes text-attributed graphs to unify different graph data by describing nodes and edges with natural language and uses language models to encode the diverse and possibly cross-domain text attributes to feature vectors in the same embedding space. Furthermore, OFA introduces the concept of nodes-of-interest to standardize different tasks with a single task representation. For in-context learning on graphs, OFA introduces a novel graph prompting paradigm that appends prompting substructures to the input graph, which enables it to address varied tasks without fine-tuning. We train the OFA model using graph data from multiple domains (including citation networks, molecular graphs, knowledge graphs, etc.) simultaneously and evaluate its ability in supervised, few-shot, and zero-shot learning scenarios. OFA performs well across different tasks, making it the first general-purpose graph classification model across domains.