 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Delay Attacks on Deep Reinforcement Learning
Sep 08, 2022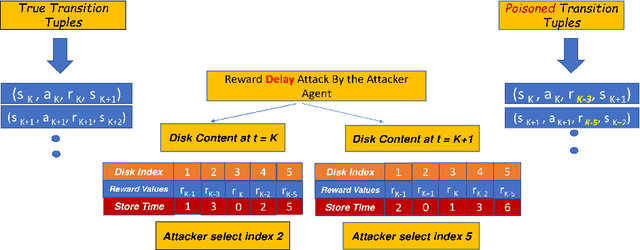
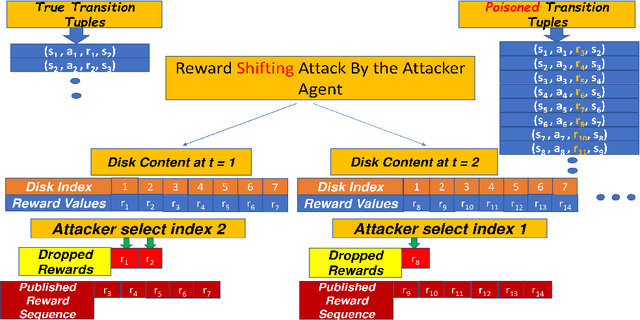
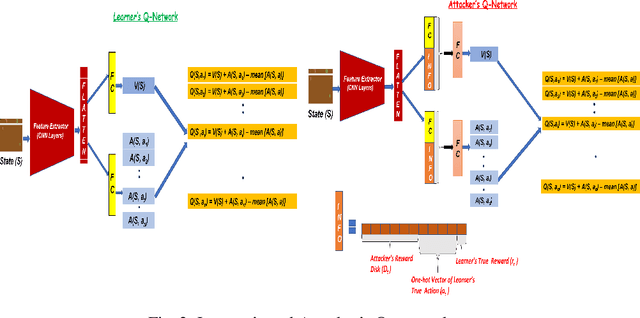
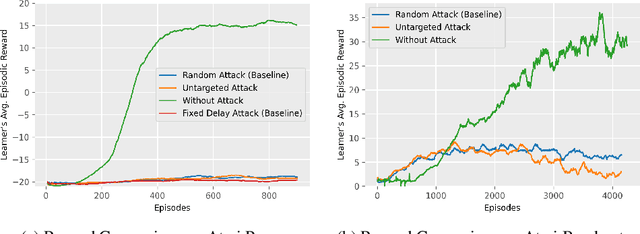
Most reinforcement learning algorithms implicitly assume strong synchrony. We present novel attacks targeting Q-learning that exploit a vulnerability entailed by this assumption by delaying the reward signal for a limited time period. We consider two types of attack goals: targeted attacks, which aim to cause a target policy to be learned, and untargeted attacks, which simply aim to induce a policy with a low reward. We evaluate the efficacy of the proposed attacks through a series of experiments. Our first observation is that reward-delay attacks are extremely effective when the goal is simply to minimize reward. Indeed, we find that even naive baseline reward-delay attacks are also highly successful in minimizing the reward. Targeted attacks, on the other hand, are more challenging, although we nevertheless demonstrate that the proposed approaches remain highly effective at achieving the attacker's targets. In addition, we introduce a second threat model that captures a minimal mitigation that ensures that rewards cannot be used out of sequence. We find that this mitigation remains insufficient to ensure robustness to attacks that delay, but preserve the order, of rewards.
Attacking Vision-based Perception in End-to-End Autonomous Driving Models
Oct 02, 2019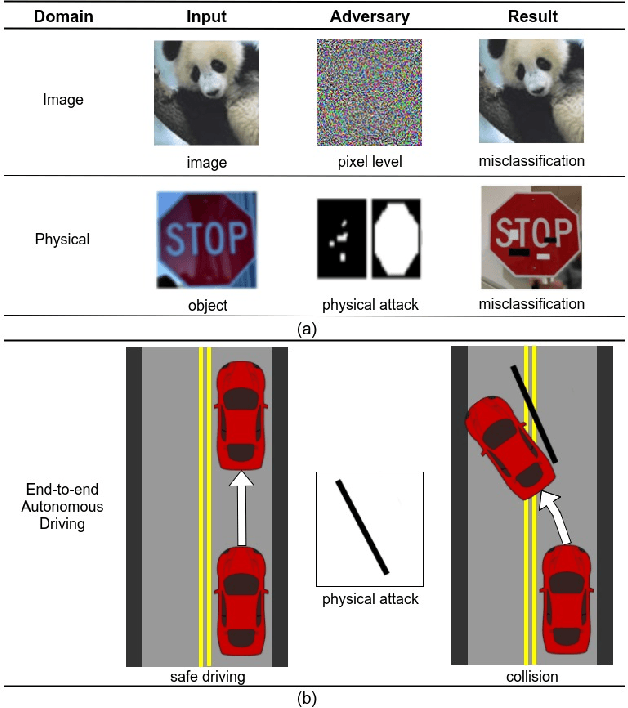

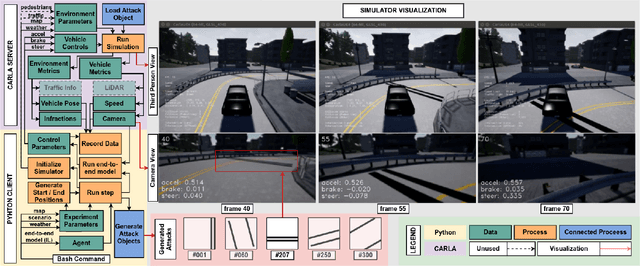
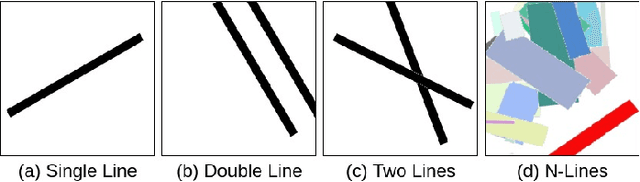
Recent advances in machine learning, especially techniques such as deep neural networks, are enabling a range of emerging applications. One such example is autonomous driving, which often relies on deep learning for perception. However, deep learning-based perception has been shown to be vulnerable to a host of subtle adversarial manipulations of images. Nevertheless, the vast majority of such demonstrations focus on perception that is disembodied from end-to-end control. We present novel end-to-end attacks on autonomous driving in simulation, using simple physically realizable attacks: the painting of black lines on the road. These attacks target deep neural network models for end-to-end autonomous driving control. A systematic investigation shows that such attacks are easy to engineer, and we describe scenarios (e.g., right turns) in which they are highly effective. We define several objective functions that quantify the success of an attack and develop techniques based on Bayesian Optimization to efficiently traverse the search space of higher dimensional attacks. Additionally, we define a novel class of hijacking attacks, where painted lines on the road cause the driver-less car to follow a target path. Through the use of network deconvolution, we provide insights into the successful attacks, which appear to work by mimicking activations of entirely different scenarios. Our code is available at https://github.com/xz-group/AdverseDrive
Simple Physical Adversarial Examples against End-to-End Autonomous Driving Models
Mar 12, 2019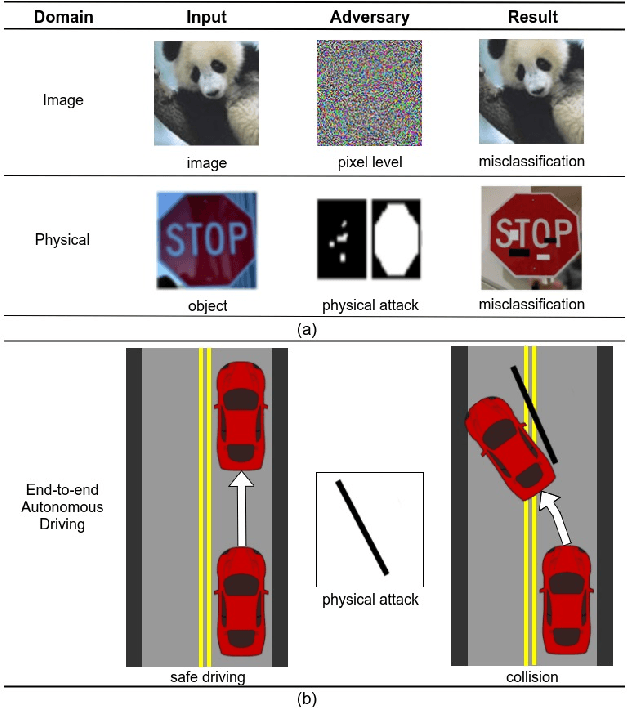
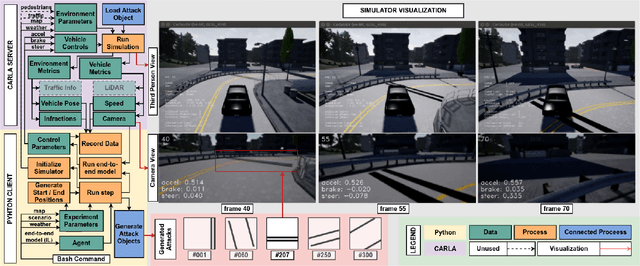
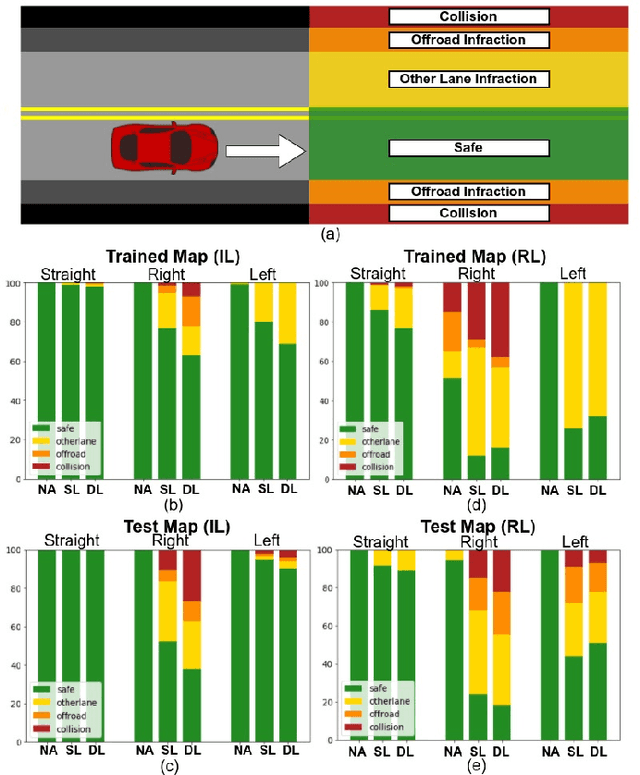
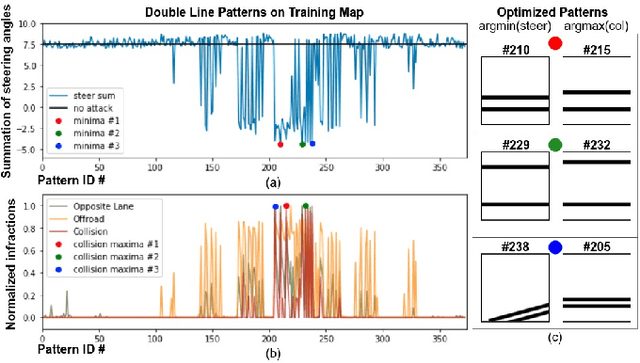
Recent advances in machine learning, especially techniques such as deep neural networks, are promoting a range of high-stakes applications, including autonomous driving, which often relies on deep learning for perception. While deep learning for perception has been shown to be vulnerable to a host of subtle adversarial manipulations of images, end-to-end demonstrations of successful attacks, which manipulate the physical environment and result in physical consequences, are scarce. Moreover, attacks typically involve carefully constructed adversarial examples at the level of pixels. We demonstrate the first end-to-end attacks on autonomous driving in simulation, using simple physically realizable attacks: the painting of black lines on the road. These attacks target deep neural network models for end-to-end autonomous driving control. A systematic investigation shows that such attacks are surprisingly easy to engineer, and we describe scenarios (e.g., right turns) in which they are highly effective, and others that are less vulnerable (e.g., driving straight). Further, we use network deconvolution to demonstrate that the attacks succeed by inducing activation patterns similar to entirely different scenarios used in training.
Real-Time Scheduling via Reinforcement Learning
Mar 15, 2012
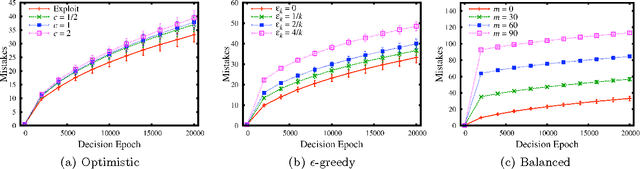
Cyber-physical systems, such as mobile robots, must respond adaptively to dynamic operating conditions. Effective operation of these systems requires that sensing and actuation tasks are performed in a timely manner. Additionally, execution of mission specific tasks such as imaging a room must be balanced against the need to perform more general tasks such as obstacle avoidance. This problem has been addressed by maintaining relative utilization of shared resources among tasks near a user-specified target level. Producing optimal scheduling strategies requires complete prior knowledge of task behavior, which is unlikely to be available in practice. Instead, suitable scheduling strategies must be learned online through interaction with the system. We consider the sample complexity of reinforcement learning in this domain, and demonstrate that while the problem state space is countably infinite, we may leverage the problem's structure to guarantee efficient learning.