 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Actively on the Fly: Relevance-Guided Online Meta-Learning with Latent Concepts for Geospatial Discovery
Feb 19, 2026In many real-world settings, such as environmental monitoring, disaster response, or public health, with costly and difficult data collection and dynamic environments, strategically sampling from unobserved regions is essential for efficiently uncovering hidden targets under tight resource constraints. Yet, sparse and biased geospatial ground truth limits the applicability of existing learning-based methods, such as reinforcement learning. To address this, we propose a unified geospatial discovery framework that integrates active learning, online meta-learning, and concept-guided reasoning. Our approach introduces two key innovations built on a shared notion of *concept relevance*, which captures how domain-specific factors influence target presence: a *concept-weighted uncertainty sampling strategy*, where uncertainty is modulated by learned relevance based on readily-available domain-specific concepts (e.g., land cover, source proximity); and a *relevance-aware meta-batch formation strategy* that promotes semantic diversity during online-meta updates, improving generalization in dynamic environments. Our experiments include testing on a real-world dataset of cancer-causing PFAS (Per- and polyfluoroalkyl substances) contamination, showcasing our method's reliability at uncovering targets with limited data and a varying environment.
Online Feedback Efficient Active Target Discovery in Partially Observable Environments
May 10, 2025In various scientific and engineering domains, where data acquisition is costly, such as in medical imaging, environmental monitoring, or remote sensing, strategic sampling from unobserved regions, guided by prior observations, is essential to maximize target discovery within a limited sampling budget. In this work, we introduce Diffusion-guided Active Target Discovery (DiffATD), a novel method that leverages diffusion dynamics for active target discovery. DiffATD maintains a belief distribution over each unobserved state in the environment, using this distribution to dynamically balance exploration-exploitation. Exploration reduces uncertainty by sampling regions with the highest expected entropy, while exploitation targets areas with the highest likelihood of discovering the target, indicated by the belief distribution and an incrementally trained reward model designed to learn the characteristics of the target. DiffATD enables efficient target discovery in a partially observable environment within a fixed sampling budget, all without relying on any prior supervised training. Furthermore, DiffATD offers interpretability, unlike existing black-box policies that require extensive supervised training. Through extensive experiments and ablation studies across diverse domains, including medical imaging and remote sensing, we show that DiffATD performs significantly better than baselines and competitively with supervised methods that operate under full environmental observability.
An Advanced Ensemble Deep Learning Framework for Stock Price Prediction Using VAE, Transformer, and LSTM Model
Mar 28, 2025


This research proposes a cutting-edge ensemble deep learning framework for stock price prediction by combining three advanced neural network architectures: The particular areas of interest for the research include but are not limited to: Variational Autoencoder (VAE), Transformer, and Long Short-Term Memory (LSTM) networks. The presented framework is aimed to substantially utilize the advantages of each model which would allow for achieving the identification of both linear and non-linear relations in stock price movements. To improve the accuracy of its predictions it uses rich set of technical indicators and it scales its predictors based on the current market situation. By trying out the framework on several stock data sets, and benchmarking the results against single models and conventional forecasting, the ensemble method exhibits consistently high accuracy and reliability. The VAE is able to learn linear representation on high-dimensional data while the Transformer outstandingly perform in recognizing long-term patterns on the stock price data. LSTM, based on its characteristics of being a model that can deal with sequences, brings additional improvements to the given framework, especially regarding temporal dynamics and fluctuations. Combined, these components provide exceptional directional performance and a very small disparity in the predicted results. The present solution has given a probable concept that can handle the inherent problem of stock price prediction with high reliability and scalability. Compared to the performance of individual proposals based on the neural network, as well as classical methods, the proposed ensemble framework demonstrates the advantages of combining different architectures. It has a very important application in algorithmic trading, risk analysis, and control and decision-making for finance professions and scholars.
Active Geospatial Search for Efficient Tenant Eviction Outreach
Dec 19, 2024Tenant evictions threaten housing stability and are a major concern for many cities. An open question concerns whether data-driven methods enhance outreach programs that target at-risk tenants to mitigate their risk of eviction. We propose a novel active geospatial search (AGS) modeling framework for this problem. AGS integrates property-level information in a search policy that identifies a sequence of rental units to canvas to both determine their eviction risk and provide support if needed. We propose a hierarchical reinforcement learning approach to learn a search policy for AGS that scales to large urban areas containing thousands of parcels, balancing exploration and exploitation and accounting for travel costs and a budget constraint. Crucially, the search policy adapts online to newly discovered information about evictions. Evaluation using eviction data for a large urban area demonstrates that the proposed framework and algorithmic approach are considerably more effective at sequentially identifying eviction cases than baseline methods.
GOMAA-Geo: GOal Modality Agnostic Active Geo-localization
Jun 04, 2024



We consider the task of active geo-localization (AGL) in which an agent uses a sequence of visual cues observed during aerial navigation to find a target specified through multiple possible modalities. This could emulate a UAV involved in a search-and-rescue operation navigating through an area, observing a stream of aerial images as it goes. The AGL task is associated with two important challenges. Firstly, an agent must deal with a goal specification in one of multiple modalities (e.g., through a natural language description) while the search cues are provided in other modalities (aerial imagery). The second challenge is limited localization time (e.g., limited battery life, urgency) so that the goal must be localized as efficiently as possible, i.e. the agent must effectively leverage its sequentially observed aerial views when searching for the goal. To address these challenges, we propose GOMAA-Geo - a goal modality agnostic active geo-localization agent - for zero-shot generalization between different goal modalities. Our approach combines cross-modality contrastive learning to align representations across modalities with supervised foundation model pretraining and reinforcement learning to obtain highly effective navigation and localization policies. Through extensive evaluations, we show that GOMAA-Geo outperforms alternative learnable approaches and that it generalizes across datasets - e.g., to disaster-hit areas without seeing a single disaster scenario during training - and goal modalities - e.g., to ground-level imagery or textual descriptions, despite only being trained with goals specified as aerial views. Code and models are publicly available at https://github.com/mvrl/GOMAA-Geo/tree/main.
Amortized nonmyopic active search via deep imitation learning
May 23, 2024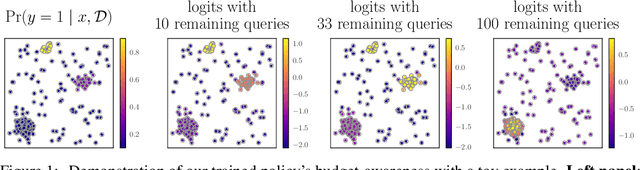

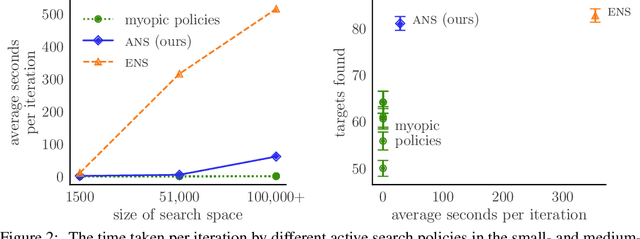

Active search formalizes a specialized active learning setting where the goal is to collect members of a rare, valuable class. The state-of-the-art algorithm approximates the optimal Bayesian policy in a budget-aware manner, and has been shown to achieve impressive empirical performance in previous work. However, even this approximate policy has a superlinear computational complexity with respect to the size of the search problem, rendering its application impractical in large spaces or in real-time systems where decisions must be made quickly. We study the amortization of this policy by training a neural network to learn to search. To circumvent the difficulty of learning from scratch, we appeal to imitation learning techniques to mimic the behavior of the expert, expensive-to-compute policy. Our policy network, trained on synthetic data, learns a beneficial search strategy that yields nonmyopic decisions carefully balancing exploration and exploitation. Extensive experiments demonstrate our policy achieves competitive performance at real-world tasks that closely approximates the expert's at a fraction of the cost, while outperforming cheaper baselines.
Attacks on Node Attributes in Graph Neural Networks
Feb 19, 2024



Graphs are commonly used to model complex networks prevalent in modern social media and literacy applications. Our research investigates the vulnerability of these graphs through the application of feature based adversarial attacks, focusing on both decision-time attacks and poisoning attacks. In contrast to state-of-the-art models like Net Attack and Meta Attack, which target node attributes and graph structure, our study specifically targets node attributes. For our analysis, we utilized the text dataset Hellaswag and graph datasets Cora and CiteSeer, providing a diverse basis for evaluation. Our findings indicate that decision-time attacks using Projected Gradient Descent (PGD) are more potent compared to poisoning attacks that employ Mean Node Embeddings and Graph Contrastive Learning strategies. This provides insights for graph data security, pinpointing where graph-based models are most vulnerable and thereby informing the development of stronger defense mechanisms against such attacks.
A Partially Supervised Reinforcement Learning Framework for Visual Active Search
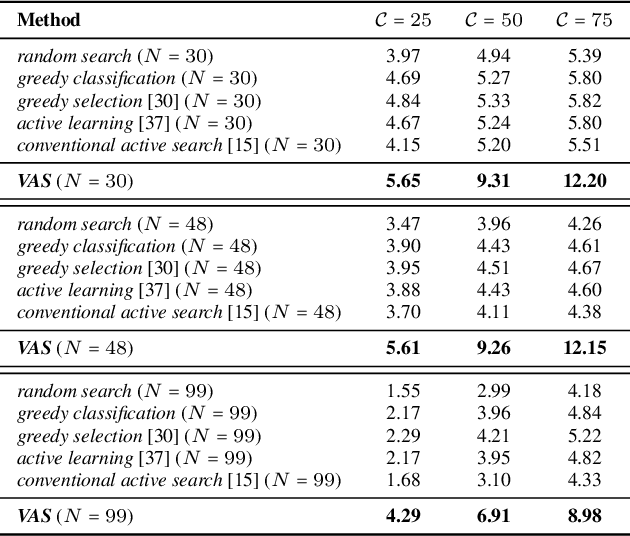
Oct 15, 2023Visual active search (VAS) has been proposed as a modeling framework in which visual cues are used to guide exploration, with the goal of identifying regions of interest in a large geospatial area. Its potential applications include identifying hot spots of rare wildlife poaching activity, search-and-rescue scenarios, identifying illegal trafficking of weapons, drugs, or people, and many others. State of the art approaches to VAS include applications of deep reinforcement learning (DRL), which yield end-to-end search policies, and traditional active search, which combines predictions with custom algorithmic approaches. While the DRL framework has been shown to greatly outperform traditional active search in such domains, its end-to-end nature does not make full use of supervised information attained either during training, or during actual search, a significant limitation if search tasks differ significantly from those in the training distribution. We propose an approach that combines the strength of both DRL and conventional active search by decomposing the search policy into a prediction module, which produces a geospatial distribution of regions of interest based on task embedding and search history, and a search module, which takes the predictions and search history as input and outputs the search distribution. We develop a novel meta-learning approach for jointly learning the resulting combined policy that can make effective use of supervised information obtained both at training and decision time. Our extensive experiments demonstrate that the proposed representation and meta-learning frameworks significantly outperform state of the art in visual active search on several problem domains.
A Visual Active Search Framework for Geospatial Exploration
Nov 28, 2022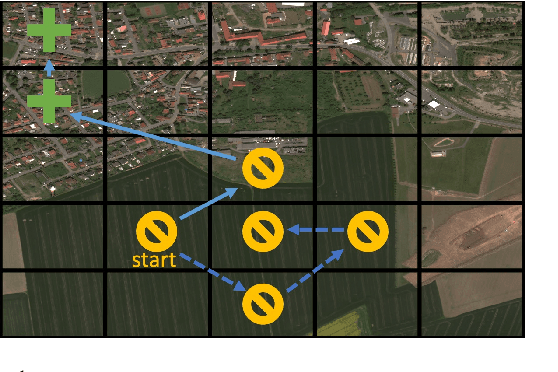
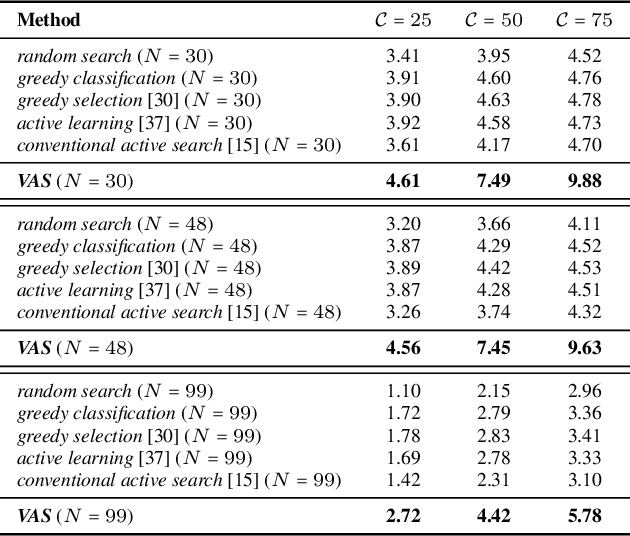
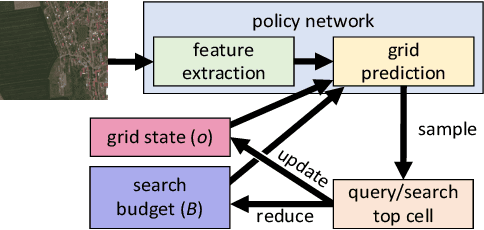
Many problems can be viewed as forms of geospatial search aided by aerial imagery, with examples ranging from detecting poaching activity to human trafficking. We model this class of problems in a visual active search (VAS) framework, which takes as input an image of a broad area, and aims to identify as many examples of a target object as possible. It does this through a limited sequence of queries, each of which verifies whether an example is present in a given region. We propose a reinforcement learning approach for VAS that leverages a collection of fully annotated search tasks as training data to learn a search policy, and combines features of the input image with a natural representation of active search state. Additionally, we propose domain adaptation techniques to improve the policy at decision time when training data is not fully reflective of the test-time distribution of VAS tasks. Through extensive experiments on several satellite imagery datasets, we show that the proposed approach significantly outperforms several strong baselines. Code and data will be made public.
Reward Delay Attacks on Deep Reinforcement Learning
Sep 08, 2022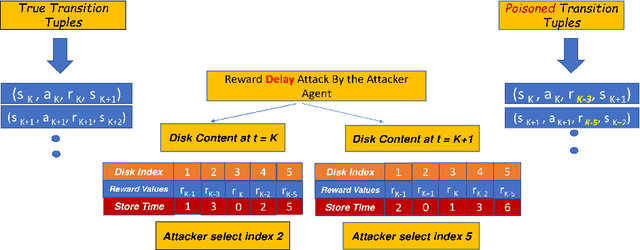
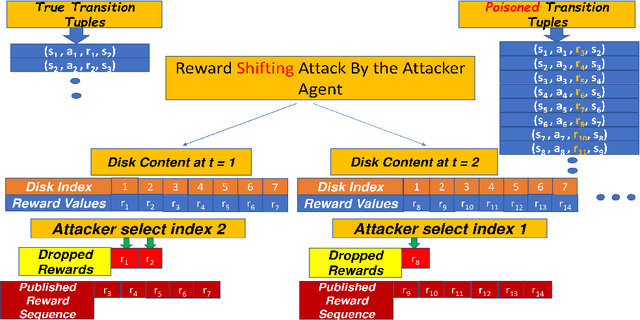
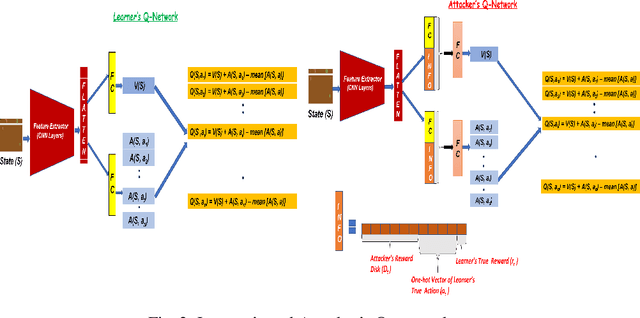
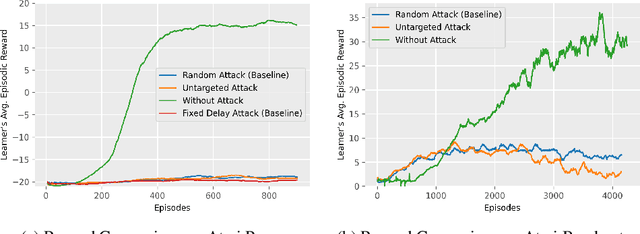
Most reinforcement learning algorithms implicitly assume strong synchrony. We present novel attacks targeting Q-learning that exploit a vulnerability entailed by this assumption by delaying the reward signal for a limited time period. We consider two types of attack goals: targeted attacks, which aim to cause a target policy to be learned, and untargeted attacks, which simply aim to induce a policy with a low reward. We evaluate the efficacy of the proposed attacks through a series of experiments. Our first observation is that reward-delay attacks are extremely effective when the goal is simply to minimize reward. Indeed, we find that even naive baseline reward-delay attacks are also highly successful in minimizing the reward. Targeted attacks, on the other hand, are more challenging, although we nevertheless demonstrate that the proposed approaches remain highly effective at achieving the attacker's targets. In addition, we introduce a second threat model that captures a minimal mitigation that ensures that rewards cannot be used out of sequence. We find that this mitigation remains insufficient to ensure robustness to attacks that delay, but preserve the order, of rewards.