 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmortized nonmyopic active search via deep imitation learning
Paper and Code
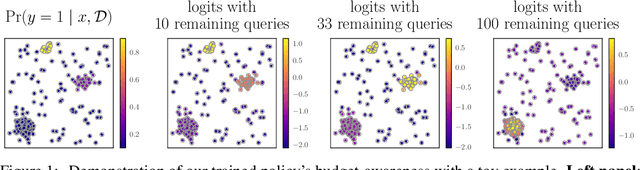

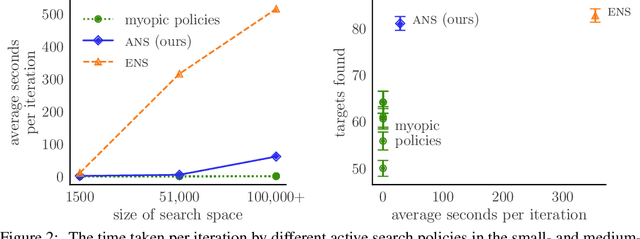

Active search formalizes a specialized active learning setting where the goal is to collect members of a rare, valuable class. The state-of-the-art algorithm approximates the optimal Bayesian policy in a budget-aware manner, and has been shown to achieve impressive empirical performance in previous work. However, even this approximate policy has a superlinear computational complexity with respect to the size of the search problem, rendering its application impractical in large spaces or in real-time systems where decisions must be made quickly. We study the amortization of this policy by training a neural network to learn to search. To circumvent the difficulty of learning from scratch, we appeal to imitation learning techniques to mimic the behavior of the expert, expensive-to-compute policy. Our policy network, trained on synthetic data, learns a beneficial search strategy that yields nonmyopic decisions carefully balancing exploration and exploitation. Extensive experiments demonstrate our policy achieves competitive performance at real-world tasks that closely approximates the expert's at a fraction of the cost, while outperforming cheaper baselines.