 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimally Auditing Adversarial Agents
Apr 28, 2026Fraud can pose a challenge in many resource allocation domains, including social service delivery and credit provision. For example, agents may misreport private information in order to gain benefits or access to credit. To mitigate this, a principal can design strategic audits to verify claims and penalize misreporting. In this paper, we introduce a general model of audit policy design as a principal-agent game with multiple agents, where the principal commits to an audit policy, and agents collectively choose an equilibrium that minimizes the principal's utility. We examine both adaptive and non-adaptive settings, depending on whether the principal's policy can be responsive to the distribution of agent reports. Our work provides efficient algorithms for computing optimal audit policies in both settings and extends these results to a setting with limited audit budgets.
* Published in Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2026, pages 16787-16794
Who pays the RENT? Implications of Spatial Inequality for Prediction-Based Allocation Policies
Aug 12, 2025AI-powered scarce resource allocation policies rely on predictions to target either specific individuals (e.g., high-risk) or settings (e.g., neighborhoods). Recent research on individual-level targeting demonstrates conflicting results; some models show that targeting is not useful when inequality is high, while other work demonstrates potential benefits. To study and reconcile this apparent discrepancy, we develop a stylized framework based on the Mallows model to understand how the spatial distribution of inequality affects the effectiveness of door-to-door outreach policies. We introduce the RENT (Relative Efficiency of Non-Targeting) metric, which we use to assess the effectiveness of targeting approaches compared with neighborhood-based approaches in preventing tenant eviction when high-risk households are more versus less spatially concentrated. We then calibrate the model parameters to eviction court records collected in a medium-sized city in the USA. Results demonstrate considerable gains in the number of high-risk households canvassed through individually targeted policies, even in a highly segregated metro area with concentrated risks of eviction. We conclude that apparent discrepancies in the prior literature can be reconciled by considering 1) the source of deployment costs and 2) the observed versus modeled concentrations of risk. Our results inform the deployment of AI-based solutions in social service provision that account for particular applications and geographies.
Street-Level AI: Are Large Language Models Ready for Real-World Judgments?
Aug 11, 2025A surge of recent work explores the ethical and societal implications of large-scale AI models that make "moral" judgments. Much of this literature focuses either on alignment with human judgments through various thought experiments or on the group fairness implications of AI judgments. However, the most immediate and likely use of AI is to help or fully replace the so-called street-level bureaucrats, the individuals deciding to allocate scarce social resources or approve benefits. There is a rich history underlying how principles of local justice determine how society decides on prioritization mechanisms in such domains. In this paper, we examine how well LLM judgments align with human judgments, as well as with socially and politically determined vulnerability scoring systems currently used in the domain of homelessness resource allocation. Crucially, we use real data on those needing services (maintaining strict confidentiality by only using local large models) to perform our analyses. We find that LLM prioritizations are extremely inconsistent in several ways: internally on different runs, between different LLMs, and between LLMs and the vulnerability scoring systems. At the same time, LLMs demonstrate qualitative consistency with lay human judgments in pairwise testing. Findings call into question the readiness of current generation AI systems for naive integration in high-stakes societal decision-making.
Active Geospatial Search for Efficient Tenant Eviction Outreach
Dec 19, 2024Tenant evictions threaten housing stability and are a major concern for many cities. An open question concerns whether data-driven methods enhance outreach programs that target at-risk tenants to mitigate their risk of eviction. We propose a novel active geospatial search (AGS) modeling framework for this problem. AGS integrates property-level information in a search policy that identifies a sequence of rental units to canvas to both determine their eviction risk and provide support if needed. We propose a hierarchical reinforcement learning approach to learn a search policy for AGS that scales to large urban areas containing thousands of parcels, balancing exploration and exploitation and accounting for travel costs and a budget constraint. Crucially, the search policy adapts online to newly discovered information about evictions. Evaluation using eviction data for a large urban area demonstrates that the proposed framework and algorithmic approach are considerably more effective at sequentially identifying eviction cases than baseline methods.
Beyond Eviction Prediction: Leveraging Local Spatiotemporal Public Records to Inform Action
Jan 27, 2024



There has been considerable recent interest in scoring properties on the basis of eviction risk. The success of methods for eviction prediction is typically evaluated using different measures of predictive accuracy. However, the underlying goal of such prediction is to direct appropriate assistance to households that may be at greater risk so they remain stably housed. Thus, we must ask the question of how useful such predictions are in targeting outreach efforts - informing action. In this paper, we investigate this question using a novel dataset that matches information on properties, evictions, and owners. We perform an eviction prediction task to produce risk scores and then use these risk scores to plan targeted outreach policies. We show that the risk scores are, in fact, useful, enabling a theoretical team of caseworkers to reach more eviction-prone properties in the same amount of time, compared to outreach policies that are either neighborhood-based or focus on buildings with a recent history of evictions. We also discuss the importance of neighborhood and ownership features in both risk prediction and targeted outreach.
Discretionary Trees: Understanding Street-Level Bureaucracy via Machine Learning
Dec 17, 2023
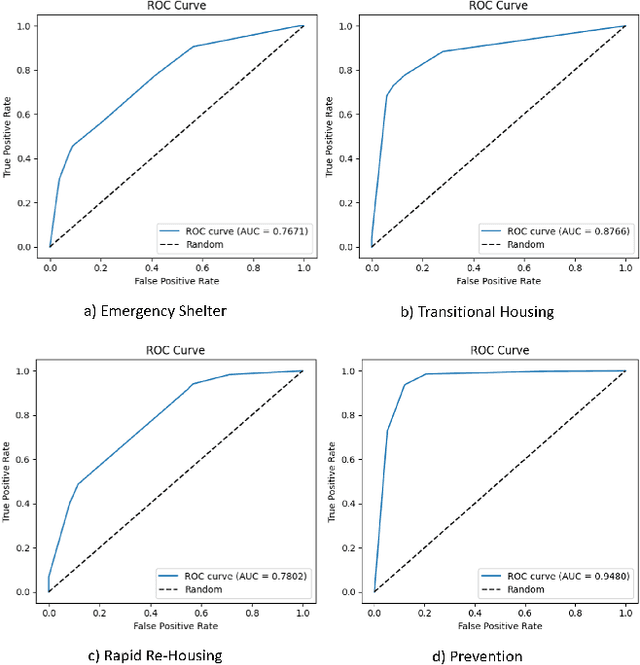

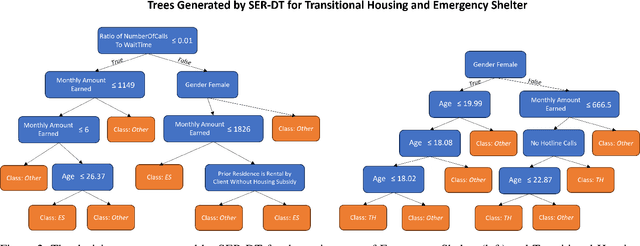
Street-level bureaucrats interact directly with people on behalf of government agencies to perform a wide range of functions, including, for example, administering social services and policing. A key feature of street-level bureaucracy is that the civil servants, while tasked with implementing agency policy, are also granted significant discretion in how they choose to apply that policy in individual cases. Using that discretion could be beneficial, as it allows for exceptions to policies based on human interactions and evaluations, but it could also allow biases and inequities to seep into important domains of societal resource allocation. In this paper, we use machine learning techniques to understand street-level bureaucrats' behavior. We leverage a rich dataset that combines demographic and other information on households with information on which homelessness interventions they were assigned during a period when assignments were not formulaic. We find that caseworker decisions in this time are highly predictable overall, and some, but not all of this predictivity can be captured by simple decision rules. We theorize that the decisions not captured by the simple decision rules can be considered applications of caseworker discretion. These discretionary decisions are far from random in both the characteristics of such households and in terms of the outcomes of the decisions. Caseworkers typically only apply discretion to households that would be considered less vulnerable. When they do apply discretion to assign households to more intensive interventions, the marginal benefits to those households are significantly higher than would be expected if the households were chosen at random; there is no similar reduction in marginal benefit to households that are discretionarily allocated less intensive interventions, suggesting that caseworkers are improving outcomes using their knowledge.
Clinical Risk Prediction Using Language Models: Benefits And Considerations
Nov 29, 2023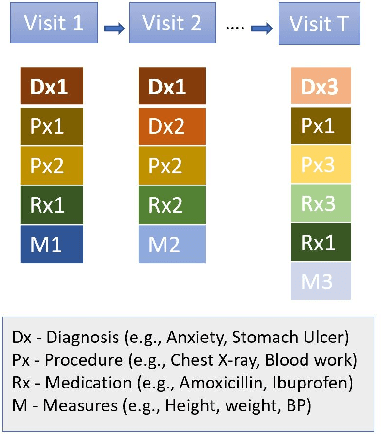

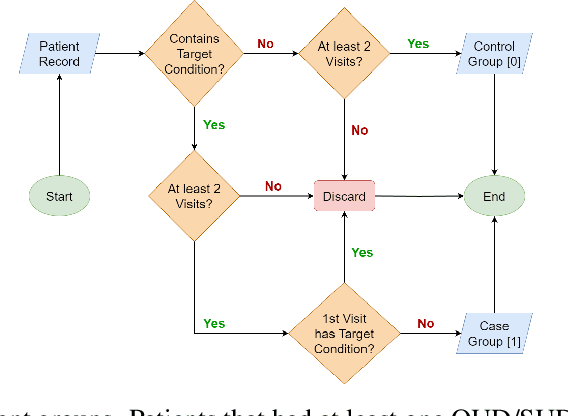
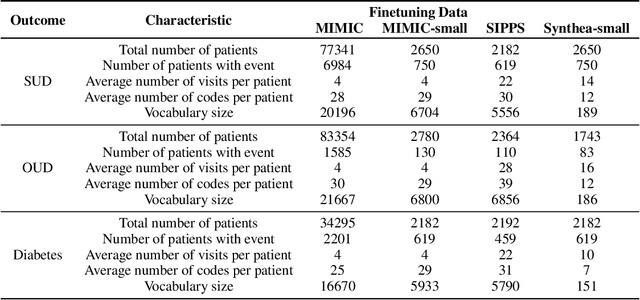
The utilization of Electronic Health Records (EHRs) for clinical risk prediction is on the rise. However, strict privacy regulations limit access to comprehensive health records, making it challenging to apply standard machine learning algorithms in practical real-world scenarios. Previous research has addressed this data limitation by incorporating medical ontologies and employing transfer learning methods. In this study, we investigate the potential of leveraging language models (LMs) as a means to incorporate supplementary domain knowledge for improving the performance of various EHR-based risk prediction tasks. Unlike applying LMs to unstructured EHR data such as clinical notes, this study focuses on using textual descriptions within structured EHR to make predictions exclusively based on that information. We extensively compare against previous approaches across various data types and sizes. We find that employing LMs to represent structured EHRs, such as diagnostic histories, leads to improved or at least comparable performance in diverse risk prediction tasks. Furthermore, LM-based approaches offer numerous advantages, including few-shot learning, the capability to handle previously unseen medical concepts, and adaptability to various medical vocabularies. Nevertheless, we underscore, through various experiments, the importance of being cautious when employing such models, as concerns regarding the reliability of LMs persist.
GenSyn: A Multi-stage Framework for Generating Synthetic Microdata using Macro Data Sources
Dec 08, 2022



Individual-level data (microdata) that characterizes a population, is essential for studying many real-world problems. However, acquiring such data is not straightforward due to cost and privacy constraints, and access is often limited to aggregated data (macro data) sources. In this study, we examine synthetic data generation as a tool to extrapolate difficult-to-obtain high-resolution data by combining information from multiple easier-to-obtain lower-resolution data sources. In particular, we introduce a framework that uses a combination of univariate and multivariate frequency tables from a given target geographical location in combination with frequency tables from other auxiliary locations to generate synthetic microdata for individuals in the target location. Our method combines the estimation of a dependency graph and conditional probabilities from the target location with the use of a Gaussian copula to leverage the available information from the auxiliary locations. We perform extensive testing on two real-world datasets and demonstrate that our approach outperforms prior approaches in preserving the overall dependency structure of the data while also satisfying the constraints defined on the different variables.
Unfairness Despite Awareness: Group-Fair Classification with Strategic Agents
Dec 06, 2021



The use of algorithmic decision making systems in domains which impact the financial, social, and political well-being of people has created a demand for these decision making systems to be "fair" under some accepted notion of equity. This demand has in turn inspired a large body of work focused on the development of fair learning algorithms which are then used in lieu of their conventional counterparts. Most analysis of such fair algorithms proceeds from the assumption that the people affected by the algorithmic decisions are represented as immutable feature vectors. However, strategic agents may possess both the ability and the incentive to manipulate this observed feature vector in order to attain a more favorable outcome. We explore the impact that strategic agent behavior could have on fair classifiers and derive conditions under which this behavior leads to fair classifiers becoming less fair than their conventional counterparts under the same measure of fairness that the fair classifier takes into account. These conditions are related to the the way in which the fair classifier remedies unfairness on the original unmanipulated data: fair classifiers which remedy unfairness by becoming more selective than their conventional counterparts are the ones that become less fair than their counterparts when agents are strategic. We further demonstrate that both the increased selectiveness of the fair classifier, and consequently the loss of fairness, arises when performing fair learning on domains in which the advantaged group is overrepresented in the region near (and on the beneficial side of) the decision boundary of conventional classifiers. Finally, we observe experimentally, using several datasets and learning methods, that this fairness reversal is common, and that our theoretical characterization of the fairness reversal conditions indeed holds in most such cases.
Local Justice and the Algorithmic Allocation of Societal Resources
Nov 10, 2021AI is increasingly used to aid decision-making about the allocation of scarce societal resources, for example housing for homeless people, organs for transplantation, and food donations. Recently, there have been several proposals for how to design objectives for these systems that attempt to achieve some combination of fairness, efficiency, incentive compatibility, and satisfactory aggregation of stakeholder preferences. This paper lays out possible roles and opportunities for AI in this domain, arguing for a closer engagement with the political philosophy literature on local justice, which provides a framework for thinking about how societies have over time framed objectives for such allocation problems. It also discusses how we may be able to integrate into this framework the opportunities and risks opened up by the ubiquity of data and the availability of algorithms that can use them to make accurate predictions about the future.