 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical Risk Prediction Using Language Models: Benefits And Considerations
Nov 29, 2023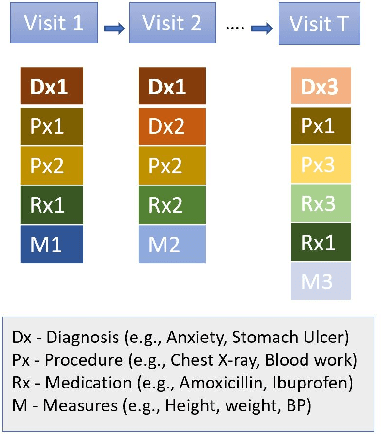

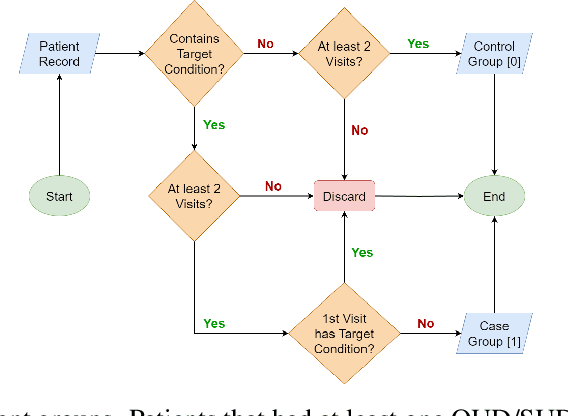
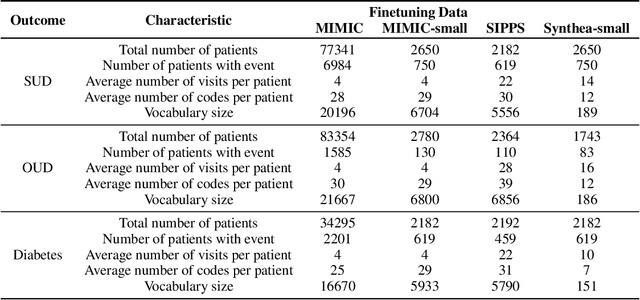
The utilization of Electronic Health Records (EHRs) for clinical risk prediction is on the rise. However, strict privacy regulations limit access to comprehensive health records, making it challenging to apply standard machine learning algorithms in practical real-world scenarios. Previous research has addressed this data limitation by incorporating medical ontologies and employing transfer learning methods. In this study, we investigate the potential of leveraging language models (LMs) as a means to incorporate supplementary domain knowledge for improving the performance of various EHR-based risk prediction tasks. Unlike applying LMs to unstructured EHR data such as clinical notes, this study focuses on using textual descriptions within structured EHR to make predictions exclusively based on that information. We extensively compare against previous approaches across various data types and sizes. We find that employing LMs to represent structured EHRs, such as diagnostic histories, leads to improved or at least comparable performance in diverse risk prediction tasks. Furthermore, LM-based approaches offer numerous advantages, including few-shot learning, the capability to handle previously unseen medical concepts, and adaptability to various medical vocabularies. Nevertheless, we underscore, through various experiments, the importance of being cautious when employing such models, as concerns regarding the reliability of LMs persist.
GenSyn: A Multi-stage Framework for Generating Synthetic Microdata using Macro Data Sources
Dec 08, 2022



Individual-level data (microdata) that characterizes a population, is essential for studying many real-world problems. However, acquiring such data is not straightforward due to cost and privacy constraints, and access is often limited to aggregated data (macro data) sources. In this study, we examine synthetic data generation as a tool to extrapolate difficult-to-obtain high-resolution data by combining information from multiple easier-to-obtain lower-resolution data sources. In particular, we introduce a framework that uses a combination of univariate and multivariate frequency tables from a given target geographical location in combination with frequency tables from other auxiliary locations to generate synthetic microdata for individuals in the target location. Our method combines the estimation of a dependency graph and conditional probabilities from the target location with the use of a Gaussian copula to leverage the available information from the auxiliary locations. We perform extensive testing on two real-world datasets and demonstrate that our approach outperforms prior approaches in preserving the overall dependency structure of the data while also satisfying the constraints defined on the different variables.