 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical Risk Prediction Using Language Models: Benefits And Considerations
Nov 29, 2023

The utilization of Electronic Health Records (EHRs) for clinical risk prediction is on the rise. However, strict privacy regulations limit access to comprehensive health records, making it challenging to apply standard machine learning algorithms in practical real-world scenarios. Previous research has addressed this data limitation by incorporating medical ontologies and employing transfer learning methods. In this study, we investigate the potential of leveraging language models (LMs) as a means to incorporate supplementary domain knowledge for improving the performance of various EHR-based risk prediction tasks. Unlike applying LMs to unstructured EHR data such as clinical notes, this study focuses on using textual descriptions within structured EHR to make predictions exclusively based on that information. We extensively compare against previous approaches across various data types and sizes. We find that employing LMs to represent structured EHRs, such as diagnostic histories, leads to improved or at least comparable performance in diverse risk prediction tasks. Furthermore, LM-based approaches offer numerous advantages, including few-shot learning, the capability to handle previously unseen medical concepts, and adaptability to various medical vocabularies. Nevertheless, we underscore, through various experiments, the importance of being cautious when employing such models, as concerns regarding the reliability of LMs persist.
Labeling Indoor Scenes with Fusion of Out-of-the-Box Perception Models
Nov 17, 2023The image annotation stage is a critical and often the most time-consuming part required for training and evaluating object detection and semantic segmentation models. Deployment of the existing models in novel environments often requires detecting novel semantic classes not present in the training data. Furthermore, indoor scenes contain significant viewpoint variations, which need to be handled properly by trained perception models. We propose to leverage the recent advancements in state-of-the-art models for bottom-up segmentation (SAM), object detection (Detic), and semantic segmentation (MaskFormer), all trained on large-scale datasets. We aim to develop a cost-effective labeling approach to obtain pseudo-labels for semantic segmentation and object instance detection in indoor environments, with the ultimate goal of facilitating the training of lightweight models for various downstream tasks. We also propose a multi-view labeling fusion stage, which considers the setting where multiple views of the scenes are available and can be used to identify and rectify single-view inconsistencies. We demonstrate the effectiveness of the proposed approach on the Active Vision dataset and the ADE20K dataset. We evaluate the quality of our labeling process by comparing it with human annotations. Also, we demonstrate the effectiveness of the obtained labels in downstream tasks such as object goal navigation and part discovery. In the context of object goal navigation, we depict enhanced performance using this fusion approach compared to a zero-shot baseline that utilizes large monolithic vision-language pre-trained models.
Self-supervised Pre-training for Semantic Segmentation in an Indoor Scene
Oct 04, 2022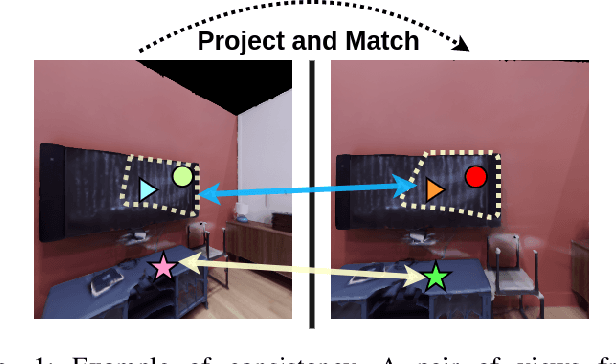
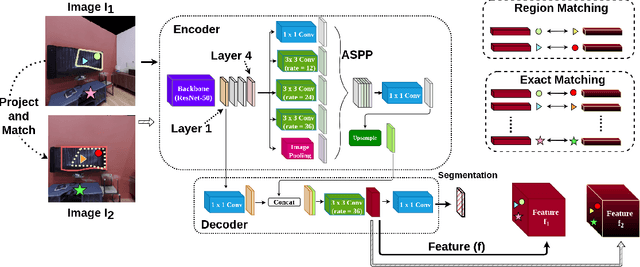

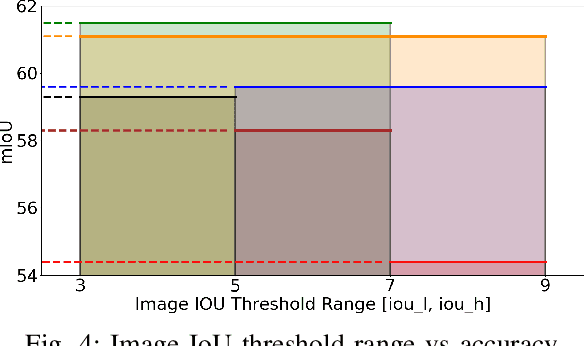
The ability to endow maps of indoor scenes with semantic information is an integral part of robotic agents which perform different tasks such as target driven navigation, object search or object rearrangement. The state-of-the-art methods use Deep Convolutional Neural Networks (DCNNs) for predicting semantic segmentation of an image as useful representation for these tasks. The accuracy of semantic segmentation depends on the availability and the amount of labeled data from the target environment or the ability to bridge the domain gap between test and training environment. We propose RegConsist, a method for self-supervised pre-training of a semantic segmentation model, exploiting the ability of the agent to move and register multiple views in the novel environment. Given the spatial and temporal consistency cues used for pixel level data association, we use a variant of contrastive learning to train a DCNN model for predicting semantic segmentation from RGB views in the target environment. The proposed method outperforms models pre-trained on ImageNet and achieves competitive performance when using models that are trained for exactly the same task but on a different dataset. We also perform various ablation studies to analyze and demonstrate the efficacy of our proposed method.