 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIKIWISI: An Interactive Visual Pattern Generator for Evaluating the Reliability of Vision-Language Models Without Ground Truth
May 28, 2025We present IKIWISI ("I Know It When I See It"), an interactive visual pattern generator for assessing vision-language models in video object recognition when ground truth is unavailable. IKIWISI transforms model outputs into a binary heatmap where green cells indicate object presence and red cells indicate object absence. This visualization leverages humans' innate pattern recognition abilities to evaluate model reliability. IKIWISI introduces "spy objects": adversarial instances users know are absent, to discern models hallucinating on nonexistent items. The tool functions as a cognitive audit mechanism, surfacing mismatches between human and machine perception by visualizing where models diverge from human understanding. Our study with 15 participants found that users considered IKIWISI easy to use, made assessments that correlated with objective metrics when available, and reached informed conclusions by examining only a small fraction of heatmap cells. This approach not only complements traditional evaluation methods through visual assessment of model behavior with custom object sets, but also reveals opportunities for improving alignment between human perception and machine understanding in vision-language systems.
Logic-RAG: Augmenting Large Multimodal Models with Visual-Spatial Knowledge for Road Scene Understanding
Mar 16, 2025Large multimodal models (LMMs) are increasingly integrated into autonomous driving systems for user interaction. However, their limitations in fine-grained spatial reasoning pose challenges for system interpretability and user trust. We introduce Logic-RAG, a novel Retrieval-Augmented Generation (RAG) framework that improves LMMs' spatial understanding in driving scenarios. Logic-RAG constructs a dynamic knowledge base (KB) about object-object relationships in first-order logic (FOL) using a perception module, a query-to-logic embedder, and a logical inference engine. We evaluated Logic-RAG on visual-spatial queries using both synthetic and real-world driving videos. When using popular LMMs (GPT-4V, Claude 3.5) as proxies for an autonomous driving system, these models achieved only 55% accuracy on synthetic driving scenes and under 75% on real-world driving scenes. Augmenting them with Logic-RAG increased their accuracies to over 80% and 90%, respectively. An ablation study showed that even without logical inference, the fact-based context constructed by Logic-RAG alone improved accuracy by 15%. Logic-RAG is extensible: it allows seamless replacement of individual components with improved versions and enables domain experts to compose new knowledge in both FOL and natural language. In sum, Logic-RAG addresses critical spatial reasoning deficiencies in LMMs for autonomous driving applications. Code and data are available at https://github.com/Imran2205/LogicRAG.
Identifying Crucial Objects in Blind and Low-Vision Individuals' Navigation
Aug 23, 2024This paper presents a curated list of 90 objects essential for the navigation of blind and low-vision (BLV) individuals, encompassing road, sidewalk, and indoor environments. We develop the initial list by analyzing 21 publicly available videos featuring BLV individuals navigating various settings. Then, we refine the list through feedback from a focus group study involving blind, low-vision, and sighted companions of BLV individuals. A subsequent analysis reveals that most contemporary datasets used to train recent computer vision models contain only a small subset of the objects in our proposed list. Furthermore, we provide detailed object labeling for these 90 objects across 31 video segments derived from the original 21 videos. Finally, we make the object list, the 21 videos, and object labeling in the 31 video segments publicly available. This paper aims to fill the existing gap and foster the development of more inclusive and effective navigation aids for the BLV community.
A Dataset for Crucial Object Recognition in Blind and Low-Vision Individuals' Navigation
Jul 23, 2024This paper introduces a dataset for improving real-time object recognition systems to aid blind and low-vision (BLV) individuals in navigation tasks. The dataset comprises 21 videos of BLV individuals navigating outdoor spaces, and a taxonomy of 90 objects crucial for BLV navigation, refined through a focus group study. We also provide object labeling for the 90 objects across 31 video segments created from the 21 videos. A deeper analysis reveals that most contemporary datasets used in training computer vision models contain only a small subset of the taxonomy in our dataset. Preliminary evaluation of state-of-the-art computer vision models on our dataset highlights shortcomings in accurately detecting key objects relevant to BLV navigation, emphasizing the need for specialized datasets. We make our dataset publicly available, offering valuable resources for developing more inclusive navigation systems for BLV individuals.
Labeling Indoor Scenes with Fusion of Out-of-the-Box Perception Models
Nov 17, 2023The image annotation stage is a critical and often the most time-consuming part required for training and evaluating object detection and semantic segmentation models. Deployment of the existing models in novel environments often requires detecting novel semantic classes not present in the training data. Furthermore, indoor scenes contain significant viewpoint variations, which need to be handled properly by trained perception models. We propose to leverage the recent advancements in state-of-the-art models for bottom-up segmentation (SAM), object detection (Detic), and semantic segmentation (MaskFormer), all trained on large-scale datasets. We aim to develop a cost-effective labeling approach to obtain pseudo-labels for semantic segmentation and object instance detection in indoor environments, with the ultimate goal of facilitating the training of lightweight models for various downstream tasks. We also propose a multi-view labeling fusion stage, which considers the setting where multiple views of the scenes are available and can be used to identify and rectify single-view inconsistencies. We demonstrate the effectiveness of the proposed approach on the Active Vision dataset and the ADE20K dataset. We evaluate the quality of our labeling process by comparing it with human annotations. Also, we demonstrate the effectiveness of the obtained labels in downstream tasks such as object goal navigation and part discovery. In the context of object goal navigation, we depict enhanced performance using this fusion approach compared to a zero-shot baseline that utilizes large monolithic vision-language pre-trained models.
A Computational Model of Early Word Learning from the Infant's Point of View
Jun 04, 2020
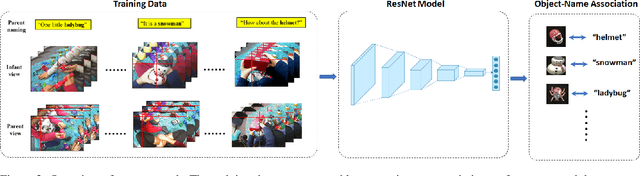


Human infants have the remarkable ability to learn the associations between object names and visual objects from inherently ambiguous experiences. Researchers in cognitive science and developmental psychology have built formal models that implement in-principle learning algorithms, and then used pre-selected and pre-cleaned datasets to test the abilities of the models to find statistical regularities in the input data. In contrast to previous modeling approaches, the present study used egocentric video and gaze data collected from infant learners during natural toy play with their parents. This allowed us to capture the learning environment from the perspective of the learner's own point of view. We then used a Convolutional Neural Network (CNN) model to process sensory data from the infant's point of view and learn name-object associations from scratch. As the first model that takes raw egocentric video to simulate infant word learning, the present study provides a proof of principle that the problem of early word learning can be solved, using actual visual data perceived by infant learners. Moreover, we conducted simulation experiments to systematically determine how visual, perceptual, and attentional properties of infants' sensory experiences may affect word learning.
Active Object Manipulation Facilitates Visual Object Learning: An Egocentric Vision Study
Jun 04, 2019Inspired by the remarkable ability of the infant visual learning system, a recent study collected first-person images from children to analyze the `training data' that they receive. We conduct a follow-up study that investigates two additional directions. First, given that infants can quickly learn to recognize a new object without much supervision (i.e. few-shot learning), we limit the number of training images. Second, we investigate how children control the supervision signals they receive during learning based on hand manipulation of objects. Our experimental results suggest that supervision with hand manipulation is better than without hands, and the trend is consistent even when a small number of images is available.
Multiview RGB-D Dataset for Object Instance Detection
Sep 26, 2016



This paper presents a new multi-view RGB-D dataset of nine kitchen scenes, each containing several objects in realistic cluttered environments including a subset of objects from the BigBird dataset. The viewpoints of the scenes are densely sampled and objects in the scenes are annotated with bounding boxes and in the 3D point cloud. Also, an approach for detection and recognition is presented, which is comprised of two parts: i) a new multi-view 3D proposal generation method and ii) the development of several recognition baselines using AlexNet to score our proposals, which is trained either on crops of the dataset or on synthetically composited training images. Finally, we compare the performance of the object proposals and a detection baseline to the Washington RGB-D Scenes (WRGB-D) dataset and demonstrate that our Kitchen scenes dataset is more challenging for object detection and recognition. The dataset is available at: http://cs.gmu.edu/~robot/gmu-kitchens.html.