 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROFUSEme: PROstate Cancer Biochemical Recurrence Prediction via FUSEd Multi-modal Embeddings
Sep 17, 2025

Almost 30% of prostate cancer (PCa) patients undergoing radical prostatectomy (RP) experience biochemical recurrence (BCR), characterized by increased prostate specific antigen (PSA) and associated with increased mortality. Accurate early prediction of BCR, at the time of RP, would contribute to prompt adaptive clinical decision-making and improved patient outcomes. In this work, we propose prostate cancer BCR prediction via fused multi-modal embeddings (PROFUSEme), which learns cross-modal interactions of clinical, radiology, and pathology data, following an intermediate fusion configuration in combination with Cox Proportional Hazard regressors. Quantitative evaluation of our proposed approach reveals superior performance, when compared with late fusion configurations, yielding a mean C-index of 0.861 ($\sigma=0.112$) on the internal 5-fold nested cross-validation framework, and a C-index of 0.7103 on the hold out data of CHIMERA 2025 challenge validation leaderboard.
Blending 3D Geometry and Machine Learning for Multi-View Stereopsis
May 06, 2025Traditional multi-view stereo (MVS) methods primarily depend on photometric and geometric consistency constraints. In contrast, modern learning-based algorithms often rely on the plane sweep algorithm to infer 3D geometry, applying explicit geometric consistency (GC) checks only as a post-processing step, with no impact on the learning process itself. In this work, we introduce GC MVSNet plus plus, a novel approach that actively enforces geometric consistency of reference view depth maps across multiple source views (multi view) and at various scales (multi scale) during the learning phase (see Fig. 1). This integrated GC check significantly accelerates the learning process by directly penalizing geometrically inconsistent pixels, effectively halving the number of training iterations compared to other MVS methods. Furthermore, we introduce a densely connected cost regularization network with two distinct block designs simple and feature dense optimized to harness dense feature connections for enhanced regularization. Extensive experiments demonstrate that our approach achieves a new state of the art on the DTU and BlendedMVS datasets and secures second place on the Tanks and Temples benchmark. To our knowledge, GC MVSNet plus plus is the first method to enforce multi-view, multi-scale supervised geometric consistency during learning. Our code is available.
What Changed and What Could Have Changed? State-Change Counterfactuals for Procedure-Aware Video Representation Learning
Mar 27, 2025



Understanding a procedural activity requires modeling both how action steps transform the scene, and how evolving scene transformations can influence the sequence of action steps, even those that are accidental or erroneous. Existing work has studied procedure-aware video representations by proposing novel approaches such as modeling the temporal order of actions and has not explicitly learned the state changes (scene transformations). In this work, we study procedure-aware video representation learning by incorporating state-change descriptions generated by Large Language Models (LLMs) as supervision signals for video encoders. Moreover, we generate state-change counterfactuals that simulate hypothesized failure outcomes, allowing models to learn by imagining the unseen ``What if'' scenarios. This counterfactual reasoning facilitates the model's ability to understand the cause and effect of each step in an activity. To verify the procedure awareness of our model, we conduct extensive experiments on procedure-aware tasks, including temporal action segmentation and error detection. Our results demonstrate the effectiveness of the proposed state-change descriptions and their counterfactuals and achieve significant improvements on multiple tasks. We will make our source code and data publicly available soon.
TimeRefine: Temporal Grounding with Time Refining Video LLM
Dec 12, 2024



Video temporal grounding aims to localize relevant temporal boundaries in a video given a textual prompt. Recent work has focused on enabling Video LLMs to perform video temporal grounding via next-token prediction of temporal timestamps. However, accurately localizing timestamps in videos remains challenging for Video LLMs when relying solely on temporal token prediction. Our proposed TimeRefine addresses this challenge in two ways. First, instead of directly predicting the start and end timestamps, we reformulate the temporal grounding task as a temporal refining task: the model first makes rough predictions and then refines them by predicting offsets to the target segment. This refining process is repeated multiple times, through which the model progressively self-improves its temporal localization accuracy. Second, to enhance the model's temporal perception capabilities, we incorporate an auxiliary prediction head that penalizes the model more if a predicted segment deviates further from the ground truth, thus encouraging the model to make closer and more accurate predictions. Our plug-and-play method can be integrated into most LLM-based temporal grounding approaches. The experimental results demonstrate that TimeRefine achieves 3.6% and 5.0% mIoU improvements on the ActivityNet and Charades-STA datasets, respectively. Code and pretrained models will be released.
Multi-resolution Guided 3D GANs for Medical Image Translation
Nov 30, 2024



Medical image translation is the process of converting from one imaging modality to another, in order to reduce the need for multiple image acquisitions from the same patient. This can enhance the efficiency of treatment by reducing the time, equipment, and labor needed. In this paper, we introduce a multi-resolution guided Generative Adversarial Network (GAN)-based framework for 3D medical image translation. Our framework uses a 3D multi-resolution Dense-Attention UNet (3D-mDAUNet) as the generator and a 3D multi-resolution UNet as the discriminator, optimized with a unique combination of loss functions including voxel-wise GAN loss and 2.5D perception loss. Our approach yields promising results in volumetric image quality assessment (IQA) across a variety of imaging modalities, body regions, and age groups, demonstrating its robustness. Furthermore, we propose a synthetic-to-real applicability assessment as an additional evaluation to assess the effectiveness of synthetic data in downstream applications such as segmentation. This comprehensive evaluation shows that our method produces synthetic medical images not only of high-quality but also potentially useful in clinical applications. Our code is available at github.com/juhha/3D-mADUNet.
Case-Enhanced Vision Transformer: Improving Explanations of Image Similarity with a ViT-based Similarity Metric
Jul 24, 2024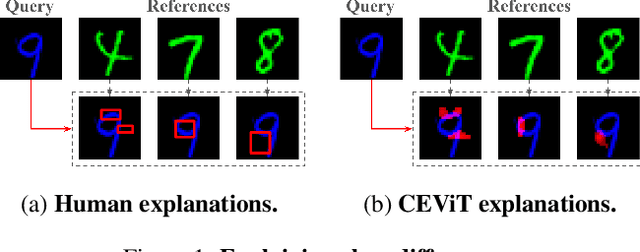



This short paper presents preliminary research on the Case-Enhanced Vision Transformer (CEViT), a similarity measurement method aimed at improving the explainability of similarity assessments for image data. Initial experimental results suggest that integrating CEViT into k-Nearest Neighbor (k-NN) classification yields classification accuracy comparable to state-of-the-art computer vision models, while adding capabilities for illustrating differences between classes. CEViT explanations can be influenced by prior cases, to illustrate aspects of similarity relevant to those cases.
Transformer for Object Re-Identification: A Survey
Jan 13, 2024Object Re-Identification (Re-ID) aims to identify and retrieve specific objects from varying viewpoints. For a prolonged period, this field has been predominantly driven by deep convolutional neural networks. In recent years, the Transformer has witnessed remarkable advancements in computer vision, prompting an increasing body of research to delve into the application of Transformer in Re-ID. This paper provides a comprehensive review and in-depth analysis of the Transformer-based Re-ID. In categorizing existing works into Image/Video-Based Re-ID, Re-ID with limited data/annotations, Cross-Modal Re-ID, and Special Re-ID Scenarios, we thoroughly elucidate the advantages demonstrated by the Transformer in addressing a multitude of challenges across these domains. Considering the trending unsupervised Re-ID, we propose a new Transformer baseline, UntransReID, achieving state-of-the-art performance on both single-/cross modal tasks. Besides, this survey also covers a wide range of Re-ID research objects, including progress in animal Re-ID. Given the diversity of species in animal Re-ID, we devise a standardized experimental benchmark and conduct extensive experiments to explore the applicability of Transformer for this task to facilitate future research. Finally, we discuss some important yet under-investigated open issues in the big foundation model era, we believe it will serve as a new handbook for researchers in this field.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Situated Cameras, Situated Knowledges: Towards an Egocentric Epistemology for Computer Vision
Jun 30, 2023In her influential 1988 paper, Situated Knowledges, Donna Haraway uses vision and perspective as a metaphor to discuss scientific knowledge. Today, egocentric computer vision discusses many of the same issues, except in a literal vision context. In this short position paper, we collapse that metaphor, and explore the interactions between feminist epistemology and egocentric CV as "Egocentric Epistemology." Using this framework, we argue for the use of qualitative, human-centric methods as a complement to performance benchmarks, to center both the literal and metaphorical perspective of human crowd workers in CV.
A Tensor-based Convolutional Neural Network for Small Dataset Classification
Mar 29, 2023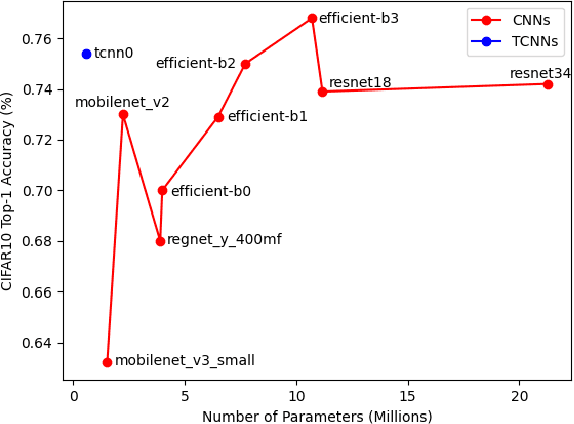

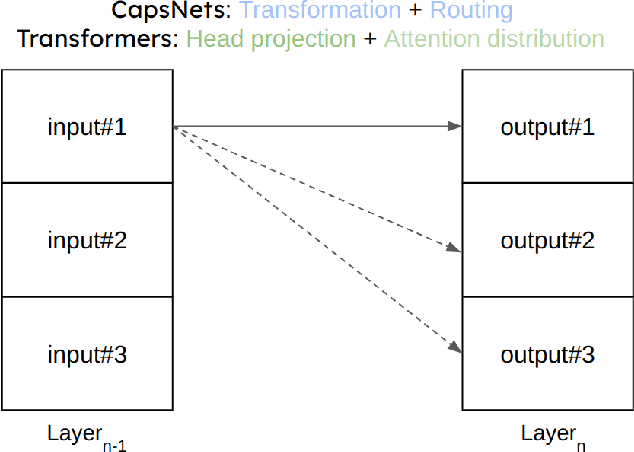

Inspired by the ConvNets with structured hidden representations, we propose a Tensor-based Neural Network, TCNN. Different from ConvNets, TCNNs are composed of structured neurons rather than scalar neurons, and the basic operation is neuron tensor transformation. Unlike other structured ConvNets, where the part-whole relationships are modeled explicitly, the relationships are learned implicitly in TCNNs. Also, the structured neurons in TCNNs are high-rank tensors rather than vectors or matrices. We compare TCNNs with current popular ConvNets, including ResNets, MobileNets, EfficientNets, RegNets, etc., on CIFAR10, CIFAR100, and Tiny ImageNet. The experiment shows that TCNNs have higher efficiency in terms of parameters. TCNNs also show higher robustness against white-box adversarial attacks on MNIST compared to ConvNets.