 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Grounded Motion Forecasting via Equation Discovery for Trajectory-Guided Image-to-Video Generation
Jul 09, 2025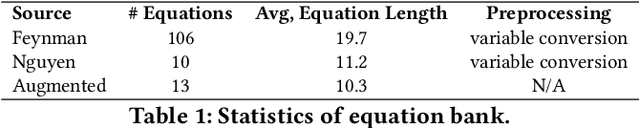
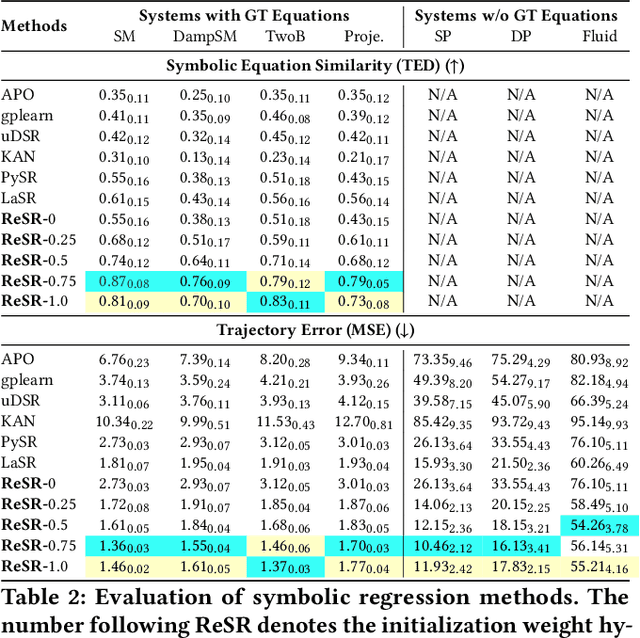
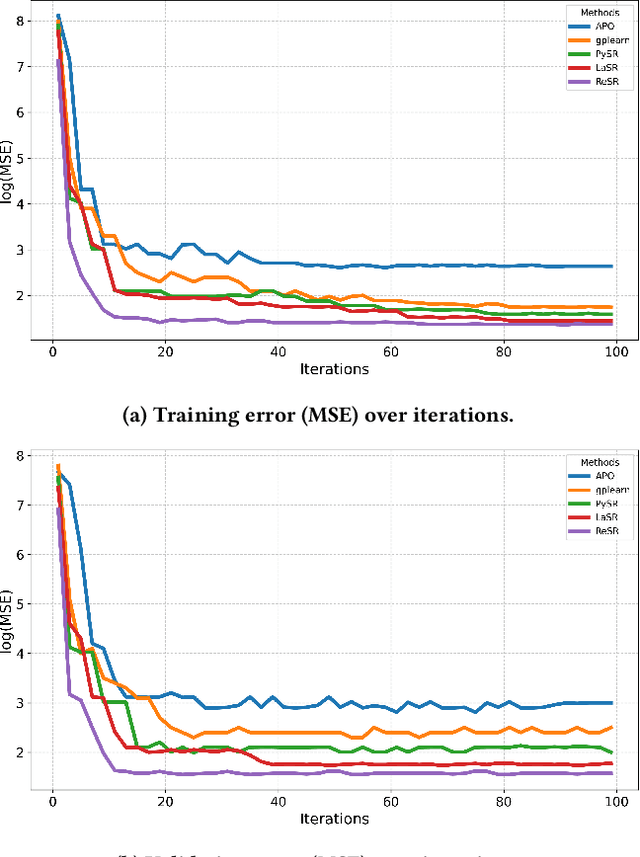
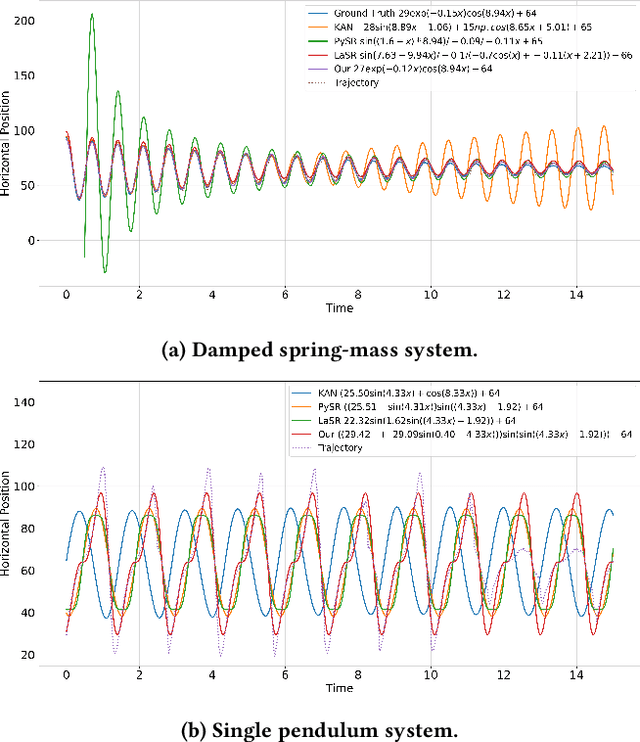
Recent advances in diffusion-based and autoregressive video generation models have achieved remarkable visual realism. However, these models typically lack accurate physical alignment, failing to replicate real-world dynamics in object motion. This limitation arises primarily from their reliance on learned statistical correlations rather than capturing mechanisms adhering to physical laws. To address this issue, we introduce a novel framework that integrates symbolic regression (SR) and trajectory-guided image-to-video (I2V) models for physics-grounded video forecasting. Our approach extracts motion trajectories from input videos, uses a retrieval-based pre-training mechanism to enhance symbolic regression, and discovers equations of motion to forecast physically accurate future trajectories. These trajectories then guide video generation without requiring fine-tuning of existing models. Evaluated on scenarios in Classical Mechanics, including spring-mass, pendulums, and projectile motions, our method successfully recovers ground-truth analytical equations and improves the physical alignment of generated videos over baseline methods.
A Tensor-based Convolutional Neural Network for Small Dataset Classification
Mar 29, 2023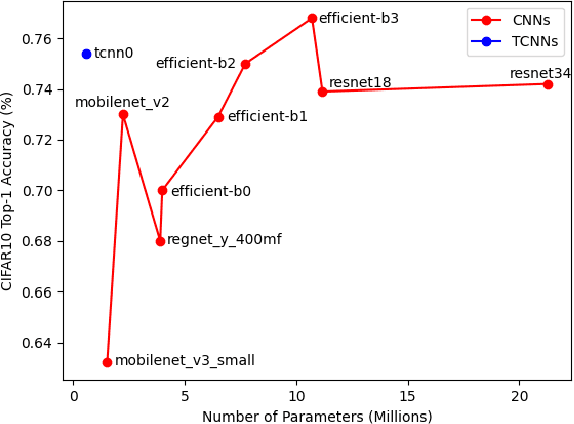

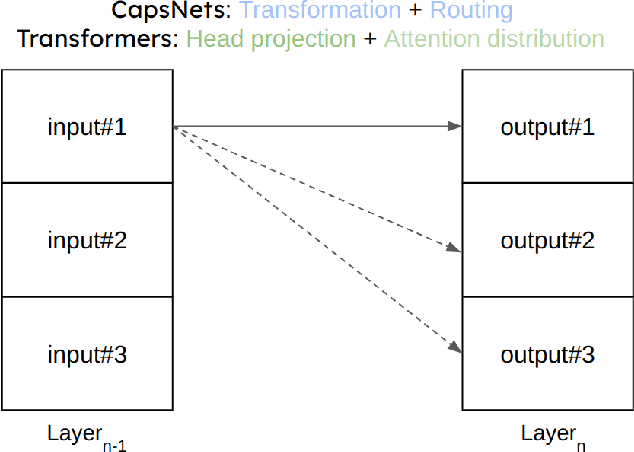

Inspired by the ConvNets with structured hidden representations, we propose a Tensor-based Neural Network, TCNN. Different from ConvNets, TCNNs are composed of structured neurons rather than scalar neurons, and the basic operation is neuron tensor transformation. Unlike other structured ConvNets, where the part-whole relationships are modeled explicitly, the relationships are learned implicitly in TCNNs. Also, the structured neurons in TCNNs are high-rank tensors rather than vectors or matrices. We compare TCNNs with current popular ConvNets, including ResNets, MobileNets, EfficientNets, RegNets, etc., on CIFAR10, CIFAR100, and Tiny ImageNet. The experiment shows that TCNNs have higher efficiency in terms of parameters. TCNNs also show higher robustness against white-box adversarial attacks on MNIST compared to ConvNets.
How to Accelerate Capsule Convolutions in Capsule Networks
Apr 06, 2021
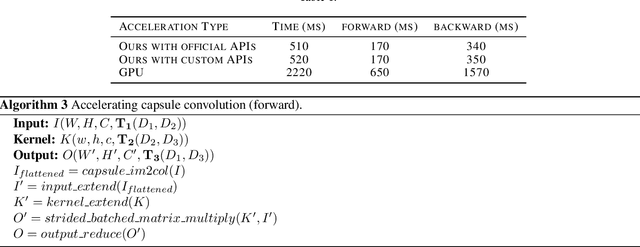
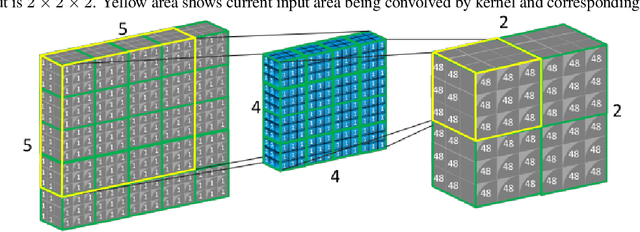
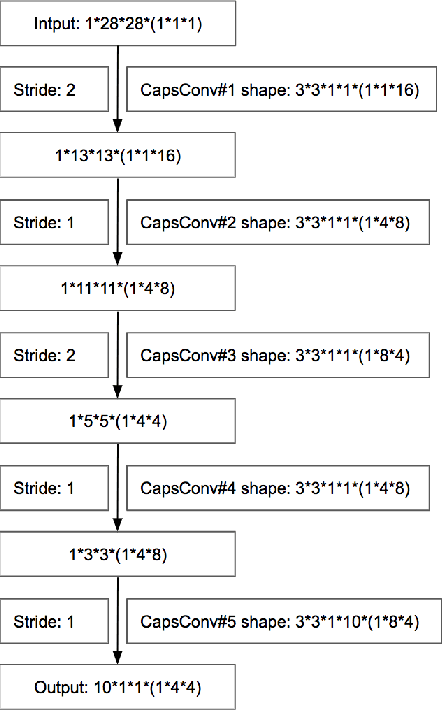
How to improve the efficiency of routing procedures in CapsNets has been studied a lot. However, the efficiency of capsule convolutions has largely been neglected. Capsule convolution, which uses capsules rather than neurons as the basic computation unit, makes it incompatible with current deep learning frameworks' optimization solution. As a result, capsule convolutions are usually very slow with these frameworks. We observe that capsule convolutions can be considered as the operations of `multiplication of multiple small matrics' plus tensor-based combination. Based on this observation, we develop two acceleration schemes with CUDA APIs and test them on a custom CapsNet. The result shows that our solution achieves a 4X acceleration.
Adversarial Attack in the Context of Self-driving
Apr 05, 2021
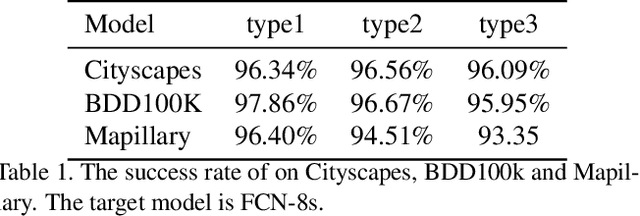
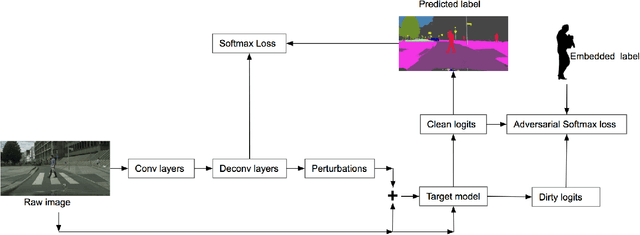
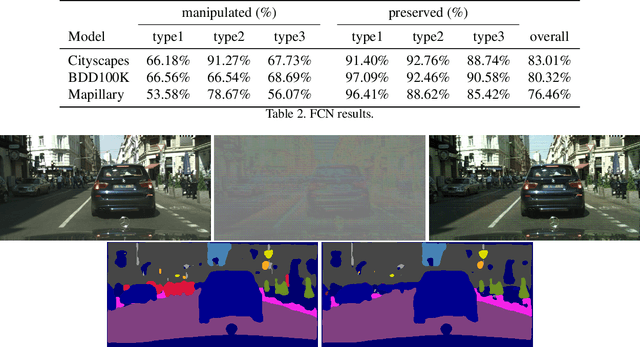
In this paper, we propose a model that can attack segmentation models with semantic and dynamic targets in the context of self-driving. Specifically, our model is designed to map an input image as well as its corresponding label to perturbations. After adding the perturbation to the input image, the adversarial example can manipulate the labels of the pixels in a semantically meaningful way on dynamic targets. In this way, we can make a potential attack subtle and stealthy. To evaluate the stealthiness of our attacking model, we design three types of tasks, including hiding true labels in the context, generating fake labels, and displacing labels that belong to some category. The experiments show that our model can attack segmentation models efficiently with a relatively high success rate on Cityscapes, Mapillary, and BDD100K. We also evaluate the generalization of our model across different datasets. Finally, we propose a new metric to evaluate the parameter-wise efficiency of attacking models by comparing the number of parameters used by both the attacking models and the target models.
P-CapsNets: a General Form of Convolutional Neural Networks
Dec 18, 2019
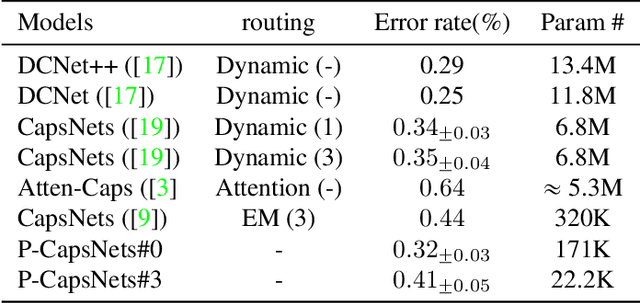
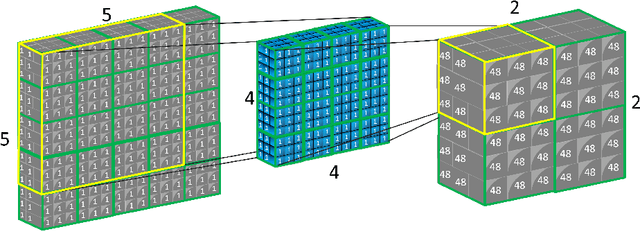
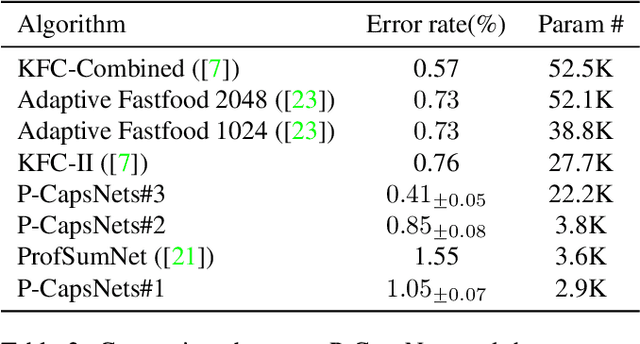
We propose Pure CapsNets (P-CapsNets) which is a generation of normal CNNs structurally. Specifically, we make three modifications to current CapsNets. First, we remove routing procedures from CapsNets based on the observation that the coupling coefficients can be learned implicitly. Second, we replace the convolutional layers in CapsNets to improve efficiency. Third, we package the capsules into rank-3 tensors to further improve efficiency. The experiment shows that P-CapsNets achieve better performance than CapsNets with varied routing procedures by using significantly fewer parameters on MNIST\&CIFAR10. The high efficiency of P-CapsNets is even comparable to some deep compressing models. For example, we achieve more than 99\% percent accuracy on MNIST by using only 3888 parameters. We visualize the capsules as well as the corresponding correlation matrix to show a possible way of initializing CapsNets in the future. We also explore the adversarial robustness of P-CapsNets compared to CNNs.
Generalized Capsule Networks with Trainable Routing Procedure
Aug 27, 2018

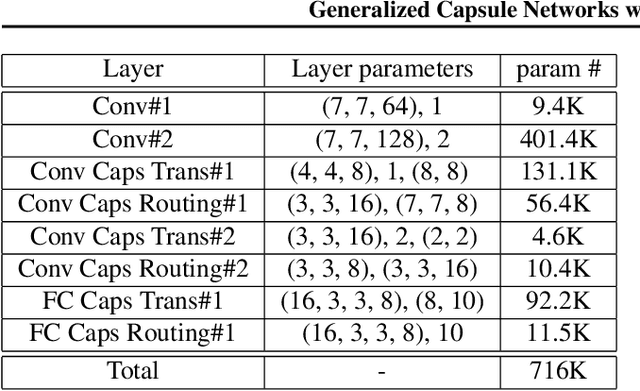
CapsNet (Capsule Network) was first proposed by~\citet{capsule} and later another version of CapsNet was proposed by~\citet{emrouting}. CapsNet has been proved effective in modeling spatial features with much fewer parameters. However, the routing procedures in both papers are not well incorporated into the whole training process. The optimal number of routing procedure is misery which has to be found manually. To overcome this disadvantages of current routing procedures in CapsNet, we embed the routing procedure into the optimization procedure with all other parameters in neural networks, namely, make coupling coefficients in the routing procedure become completely trainable. We call it Generalized CapsNet (G-CapsNet). We implement both "full-connected" version of G-CapsNet and "convolutional" version of G-CapsNet. G-CapsNet achieves a similar performance in the dataset MNIST as in the original papers. We also test two capsule packing method (cross feature maps or with feature maps) from previous convolutional layers and see no evident difference. Besides, we also explored possibility of stacking multiple capsule layers. The code is shared on \hyperlink{https://github.com/chenzhenhua986/CAFFE-CapsNet}{CAFFE-CapsNet}.
Detecting Small, Densely Distributed Objects with Filter-Amplifier Networks and Loss Boosting
May 07, 2018



Detecting small, densely distributed objects is a significant challenge: small objects often contain less distinctive information compared to larger ones, and finer-grained precision of bounding box boundaries are required. In this paper, we propose two techniques for addressing this problem. First, we estimate the likelihood that each pixel belongs to an object boundary rather than predicting coordinates of bounding boxes (as YOLO, Faster-RCNN and SSD do), by proposing a new architecture called Filter-Amplifier Networks (FANs). Second, we introduce a technique called Loss Boosting (LB) which attempts to soften the loss imbalance problem on each image. We test our algorithm on the problem of detecting electrical components on a new, realistic, diverse dataset of printed circuit boards (PCBs), as well as the problem of detecting vehicles in the Vehicle Detection in Aerial Imagery (VEDAI) dataset. Experiments show that our method works significantly better than current state-of-the-art algorithms with respect to accuracy, recall and average IoU.