 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio and Multiscale Visual Cues Driven Cross-modal Transformer for Idling Vehicle Detection
Apr 15, 2025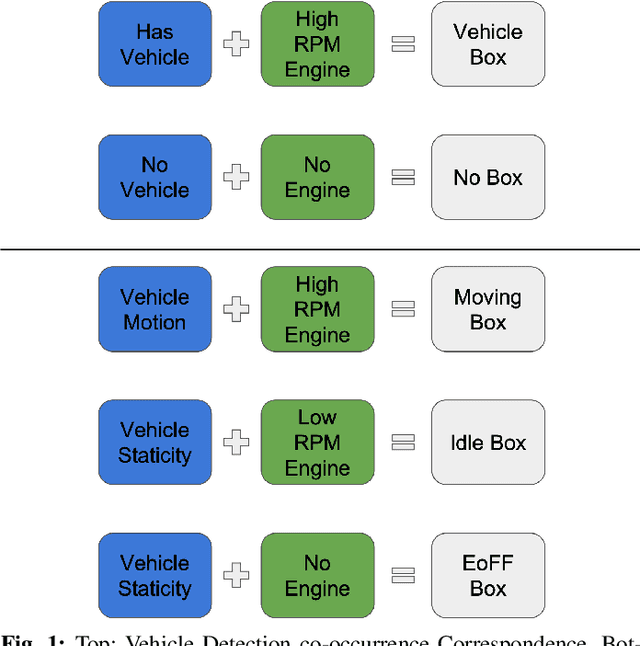

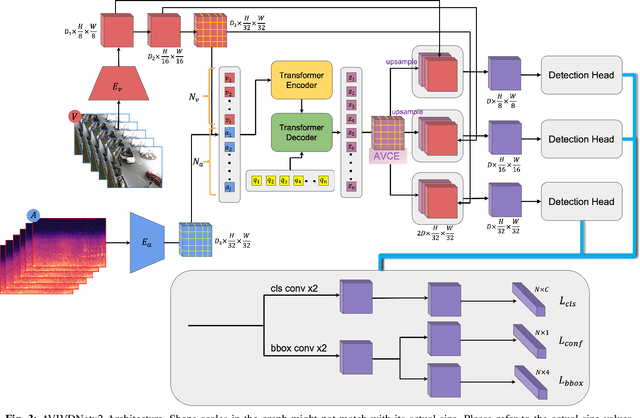
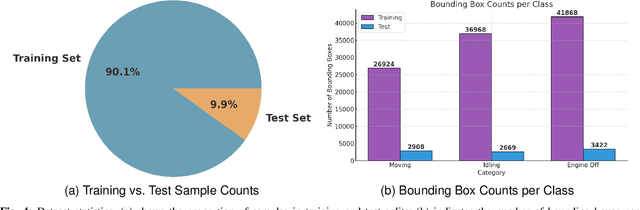
Idling vehicle detection (IVD) supports real-time systems that reduce pollution and emissions by dynamically messaging drivers to curb excess idling behavior. In computer vision, IVD has become an emerging task that leverages video from surveillance cameras and audio from remote microphones to localize and classify vehicles in each frame as moving, idling, or engine-off. As with other cross-modal tasks, the key challenge lies in modeling the correspondence between audio and visual modalities, which differ in representation but provide complementary cues -- video offers spatial and motion context, while audio conveys engine activity beyond the visual field. The previous end-to-end model, which uses a basic attention mechanism, struggles to align these modalities effectively, often missing vehicle detections. To address this issue, we propose AVIVDNetv2, a transformer-based end-to-end detection network. It incorporates a cross-modal transformer with global patch-level learning, a multiscale visual feature fusion module, and decoupled detection heads. Extensive experiments show that AVIVDNetv2 improves mAP by 7.66 over the disjoint baseline and 9.42 over the E2E baseline, with consistent AP gains across all vehicle categories. Furthermore, AVIVDNetv2 outperforms the state-of-the-art method for sounding object localization, establishing a new performance benchmark on the AVIVD dataset.
Joint Audio-Visual Idling Vehicle Detection with Streamlined Input Dependencies
Oct 28, 2024

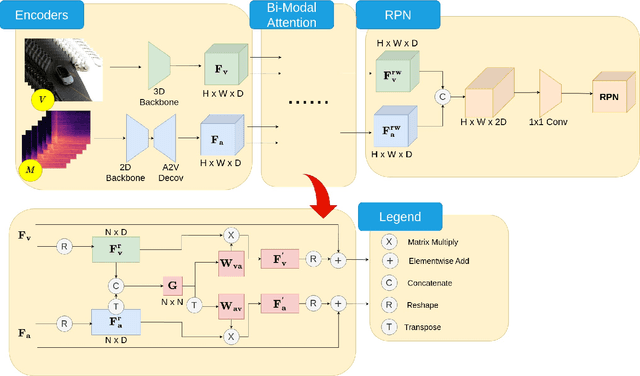

Idling vehicle detection (IVD) can be helpful in monitoring and reducing unnecessary idling and can be integrated into real-time systems to address the resulting pollution and harmful products. The previous approach [13], a non-end-to-end model, requires extra user clicks to specify a part of the input, making system deployment more error-prone or even not feasible. In contrast, we introduce an end-to-end joint audio-visual IVD task designed to detect vehicles visually under three states: moving, idling and engine off. Unlike feature co-occurrence task such as audio-visual vehicle tracking, our IVD task addresses complementary features, where labels cannot be determined by a single modality alone. To this end, we propose AVIVD-Net, a novel network that integrates audio and visual features through a bidirectional attention mechanism. AVIVD-Net streamlines the input process by learning a joint feature space, reducing the deployment complexity of previous methods. Additionally, we introduce the AVIVD dataset, which is seven times larger than previous datasets, offering significantly more annotated samples to study the IVD problem. Our model achieves performance comparable to prior approaches, making it suitable for automated deployment. Furthermore, by evaluating AVIVDNet on the feature co-occurrence public dataset MAVD [23], we demonstrate its potential for extension to self-driving vehicle video-camera setups.
Vital Insight: Assisting Experts' Sensemaking Process of Multi-modal Personal Tracking Data Using Visualization and LLM
Oct 18, 2024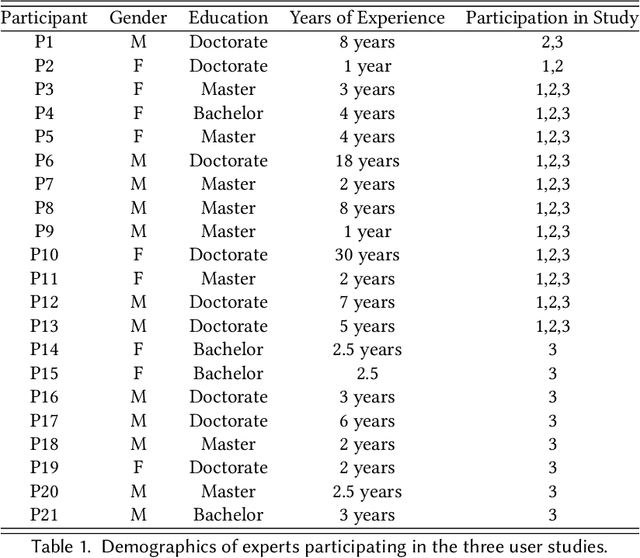
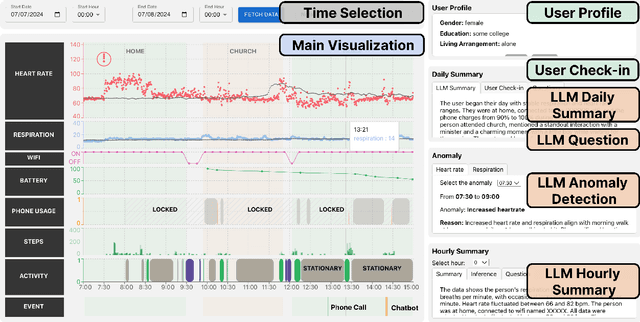
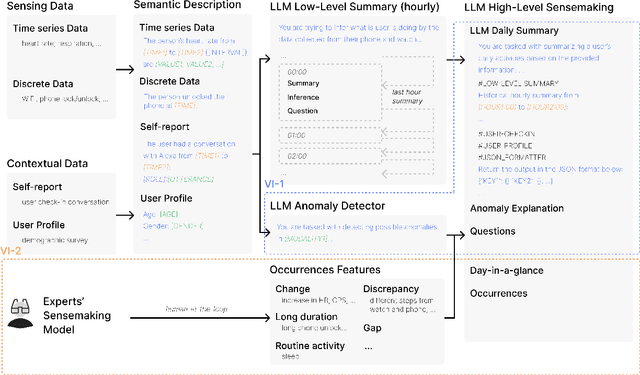

Researchers have long recognized the socio-technical gaps in personal tracking research, where machines can never fully model the complexity of human behavior, making it only able to produce basic rule-based outputs or "black-box" results that lack clear explanations. Real-world deployments rely on experts for this complex translation from sparse data to meaningful insights. In this study, we consider this translation process from data to insights by experts as "sensemaking" and explore how HCI researchers can support it through Vital Insight, an evidence-based 'sensemaking' system that combines direct representation and indirect inference through visualization and Large Language Models. We evaluate Vital Insight in user testing sessions with 14 experts in multi-modal tracking, synthesize design implications, and develop an expert sensemaking model where they iteratively move between direct data representations and AI-supported inferences to explore, retrieve, question, and validate insights.
Real-Time Idling Vehicles Detection Using Combined Audio-Visual Deep Learning
May 23, 2023Combustion vehicle emissions contribute to poor air quality and release greenhouse gases into the atmosphere, and vehicle pollution has been associated with numerous adverse health effects. Roadways with extensive waiting and/or passenger drop off, such as schools and hospital drop-off zones, can result in high incidence and density of idling vehicles. This can produce micro-climates of increased vehicle pollution. Thus, the detection of idling vehicles can be helpful in monitoring and responding to unnecessary idling and be integrated into real-time or off-line systems to address the resulting pollution. In this paper we present a real-time, dynamic vehicle idling detection algorithm. The proposed idle detection algorithm and notification rely on an algorithm to detect these idling vehicles. The proposed method relies on a multi-sensor, audio-visual, machine-learning workflow to detect idling vehicles visually under three conditions: moving, static with the engine on, and static with the engine off. The visual vehicle motion detector is built in the first stage, and then a contrastive-learning-based latent space is trained for classifying static vehicle engine sound. We test our system in real-time at a hospital drop-off point in Salt Lake City. This in-situ dataset was collected and annotated, and it includes vehicles of varying models and types. The experiments show that the method can detect engine switching on or off instantly and achieves 71.01 mean average precision (mAP).
How to Accelerate Capsule Convolutions in Capsule Networks
Apr 06, 2021
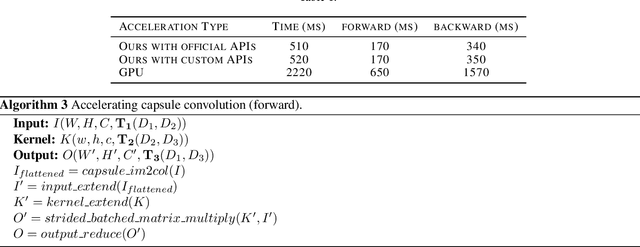
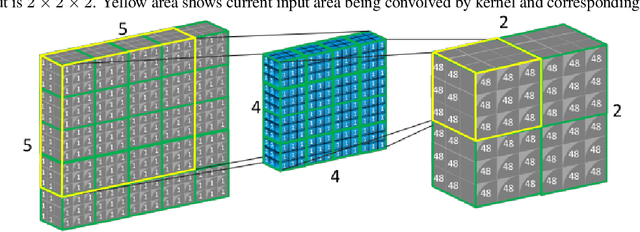
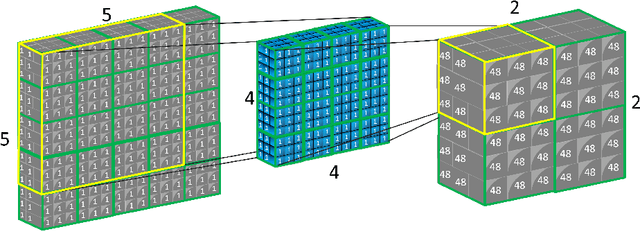
How to improve the efficiency of routing procedures in CapsNets has been studied a lot. However, the efficiency of capsule convolutions has largely been neglected. Capsule convolution, which uses capsules rather than neurons as the basic computation unit, makes it incompatible with current deep learning frameworks' optimization solution. As a result, capsule convolutions are usually very slow with these frameworks. We observe that capsule convolutions can be considered as the operations of `multiplication of multiple small matrics' plus tensor-based combination. Based on this observation, we develop two acceleration schemes with CUDA APIs and test them on a custom CapsNet. The result shows that our solution achieves a 4X acceleration.
P-CapsNets: a General Form of Convolutional Neural Networks
Dec 18, 2019
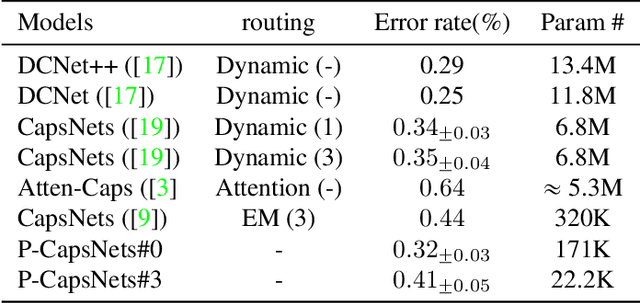
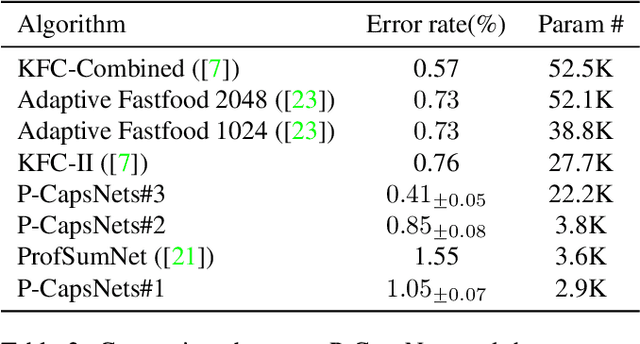
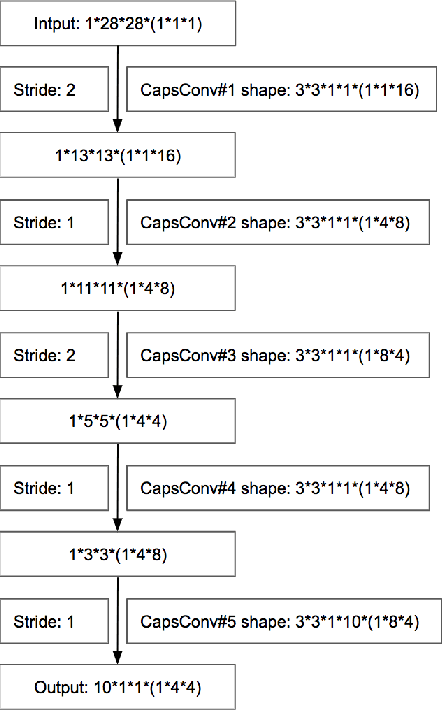
We propose Pure CapsNets (P-CapsNets) which is a generation of normal CNNs structurally. Specifically, we make three modifications to current CapsNets. First, we remove routing procedures from CapsNets based on the observation that the coupling coefficients can be learned implicitly. Second, we replace the convolutional layers in CapsNets to improve efficiency. Third, we package the capsules into rank-3 tensors to further improve efficiency. The experiment shows that P-CapsNets achieve better performance than CapsNets with varied routing procedures by using significantly fewer parameters on MNIST\&CIFAR10. The high efficiency of P-CapsNets is even comparable to some deep compressing models. For example, we achieve more than 99\% percent accuracy on MNIST by using only 3888 parameters. We visualize the capsules as well as the corresponding correlation matrix to show a possible way of initializing CapsNets in the future. We also explore the adversarial robustness of P-CapsNets compared to CNNs.