 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Stress Detection Reproducibility to Consumer Wearable Sensors
May 09, 2025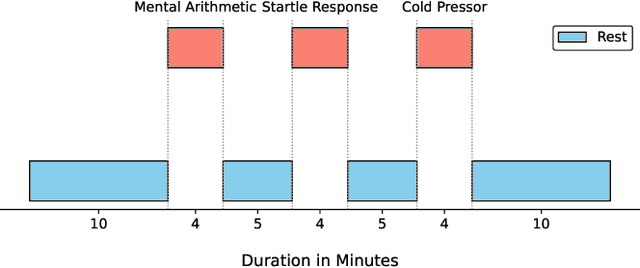
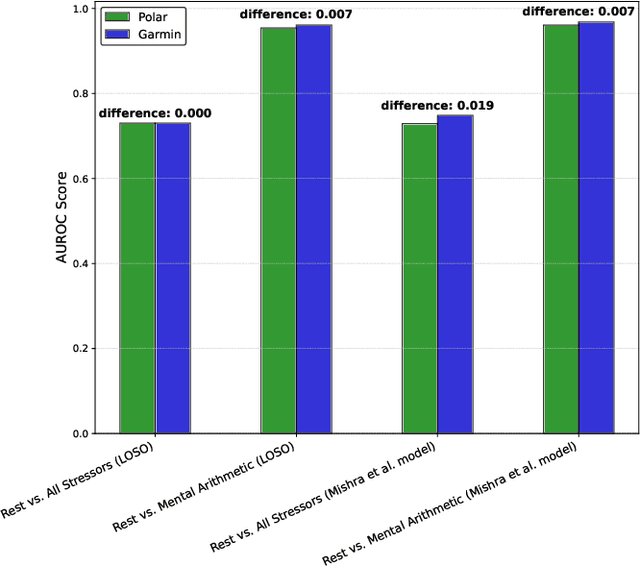
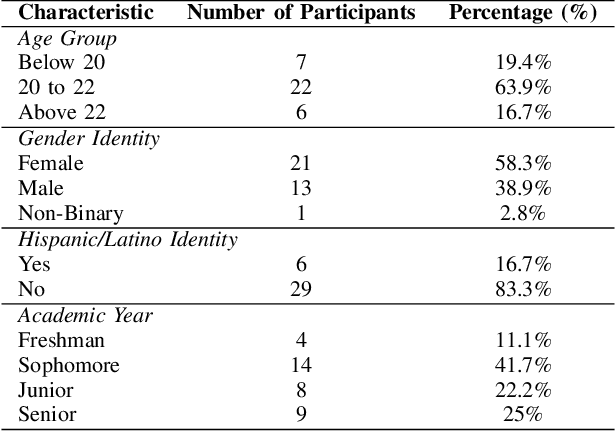
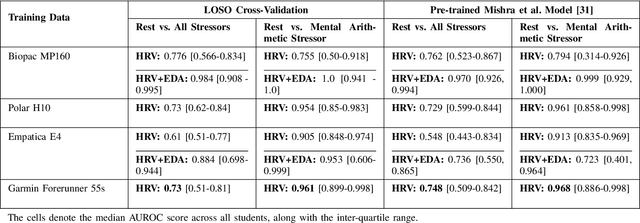
Wearable sensors are widely used to collect physiological data and develop stress detection models. However, most studies focus on a single dataset, rarely evaluating model reproducibility across devices, populations, or study conditions. We previously assessed the reproducibility of stress detection models across multiple studies, testing models trained on one dataset against others using heart rate (with R-R interval) and electrodermal activity (EDA). In this study, we extended our stress detection reproducibility to consumer wearable sensors. We compared validated research-grade devices, to consumer wearables - Biopac MP160, Polar H10, Empatica E4, to the Garmin Forerunner 55s, assessing device-specific stress detection performance by conducting a new stress study on undergraduate students. Thirty-five students completed three standardized stress-induction tasks in a lab setting. Biopac MP160 performed the best, being consistent with our expectations of it as the gold standard, though performance varied across devices and models. Combining heart rate variability (HRV) and EDA enhanced stress prediction across most scenarios. However, Empatica E4 showed variability; while HRV and EDA improved stress detection in leave-one-subject-out (LOSO) evaluations (AUROC up to 0.953), device-specific limitations led to underperformance when tested with our pre-trained stress detection tool (AUROC 0.723), highlighting generalizability challenges related to hardware-model compatibility. Garmin Forerunner 55s demonstrated strong potential for real-world stress monitoring, achieving the best mental arithmetic stress detection performance in LOSO (AUROC up to 0.961) comparable to research-grade devices like Polar H10 (AUROC 0.954), and Empatica E4 (AUROC 0.905 with HRV-only model and AUROC 0.953 with HRV+EDA model), with the added advantage of consumer-friendly wearability for free-living contexts.
Imputation Matters: A Deeper Look into an Overlooked Step in Longitudinal Health and Behavior Sensing Research
Dec 08, 2024Longitudinal passive sensing studies for health and behavior outcomes often have missing and incomplete data. Handling missing data effectively is thus a critical data processing and modeling step. Our formative interviews with researchers working in longitudinal health and behavior passive sensing revealed a recurring theme: most researchers consider imputation a low-priority step in their analysis and inference pipeline, opting to use simple and off-the-shelf imputation strategies without comprehensively evaluating its impact on study outcomes. Through this paper, we call attention to the importance of imputation. Using publicly available passive sensing datasets for depression, we show that prioritizing imputation can significantly impact the study outcomes -- with our proposed imputation strategies resulting in up to 31% improvement in AUROC to predict depression over the original imputation strategy. We conclude by discussing the challenges and opportunities with effective imputation in longitudinal sensing studies.
Vital Insight: Assisting Experts' Sensemaking Process of Multi-modal Personal Tracking Data Using Visualization and LLM
Oct 18, 2024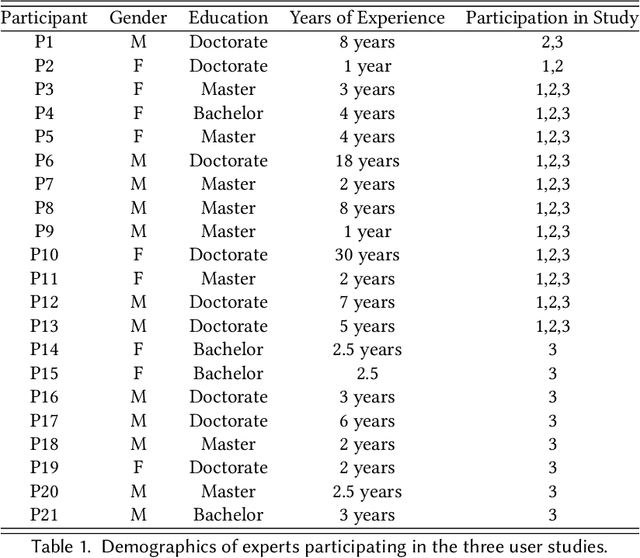
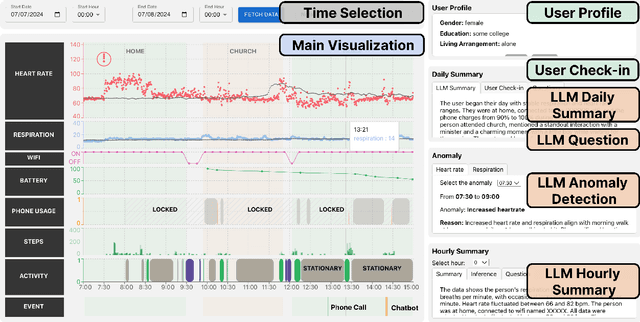
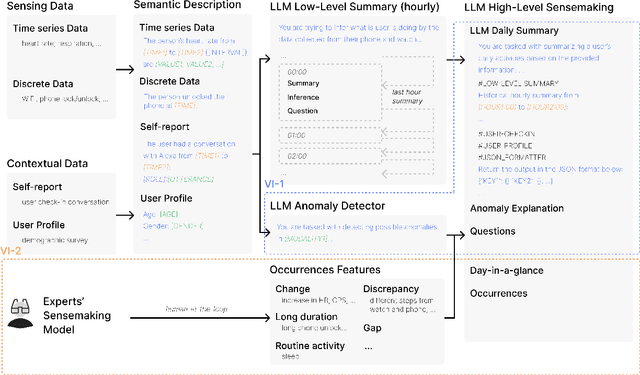

Researchers have long recognized the socio-technical gaps in personal tracking research, where machines can never fully model the complexity of human behavior, making it only able to produce basic rule-based outputs or "black-box" results that lack clear explanations. Real-world deployments rely on experts for this complex translation from sparse data to meaningful insights. In this study, we consider this translation process from data to insights by experts as "sensemaking" and explore how HCI researchers can support it through Vital Insight, an evidence-based 'sensemaking' system that combines direct representation and indirect inference through visualization and Large Language Models. We evaluate Vital Insight in user testing sessions with 14 experts in multi-modal tracking, synthesize design implications, and develop an expert sensemaking model where they iteratively move between direct data representations and AI-supported inferences to explore, retrieve, question, and validate insights.
SeSaMe: A Framework to Simulate Self-Reported Ground Truth for Mental Health Sensing Studies
Mar 27, 2024
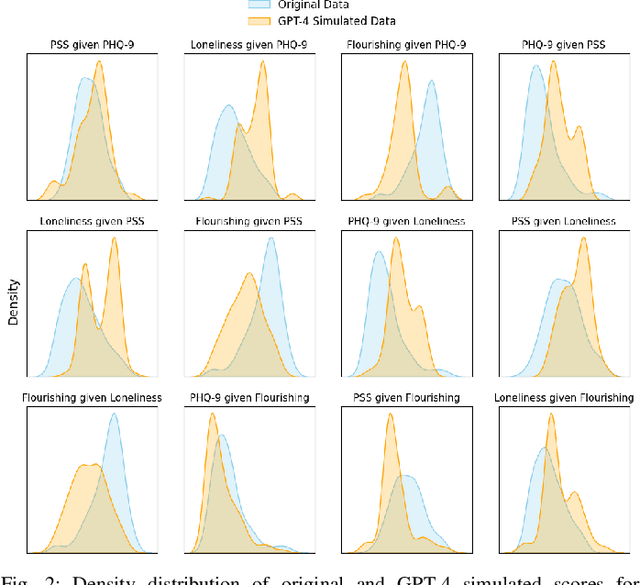
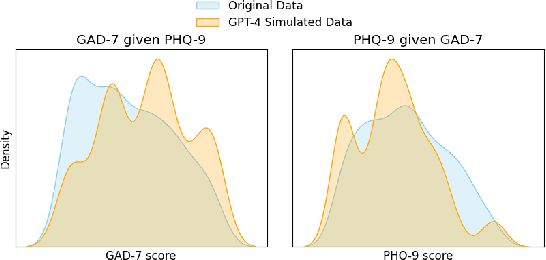
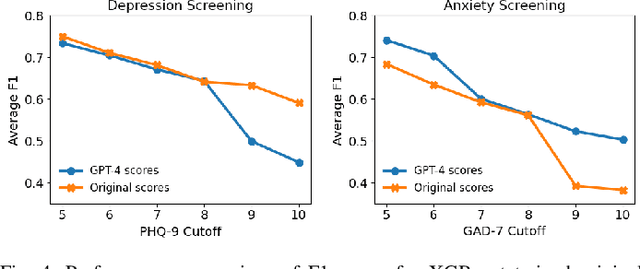
Advances in mobile and wearable technologies have enabled the potential to passively monitor a person's mental, behavioral, and affective health. These approaches typically rely on longitudinal collection of self-reported outcomes, e.g., depression, stress, and anxiety, to train machine learning (ML) models. However, the need to continuously self-report adds a significant burden on the participants, often resulting in attrition, missing labels, or insincere responses. In this work, we introduce the Scale Scores Simulation using Mental Models (SeSaMe) framework to alleviate participants' burden in digital mental health studies. By leveraging pre-trained large language models (LLMs), SeSaMe enables the simulation of participants' responses on psychological scales. In SeSaMe, researchers can prompt LLMs with information on participants' internal behavioral dispositions, enabling LLMs to construct mental models of participants to simulate their responses on psychological scales. We demonstrate an application of SeSaMe, where we use GPT-4 to simulate responses on one scale using responses from another as behavioral information. We also evaluate the alignment between human and SeSaMe-simulated responses to psychological scales. Then, we present experiments to inspect the utility of SeSaMe-simulated responses as ground truth in training ML models by replicating established depression and anxiety screening tasks from a previous study. Our results indicate SeSaMe to be a promising approach, but its alignment may vary across scales and specific prediction objectives. We also observed that model performance with simulated data was on par with using the real data for training in most evaluation scenarios. We conclude by discussing the potential implications of SeSaMe in addressing some challenges researchers face with ground-truth collection in passive sensing studies.