 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeSaMe: A Framework to Simulate Self-Reported Ground Truth for Mental Health Sensing Studies
Paper and Code

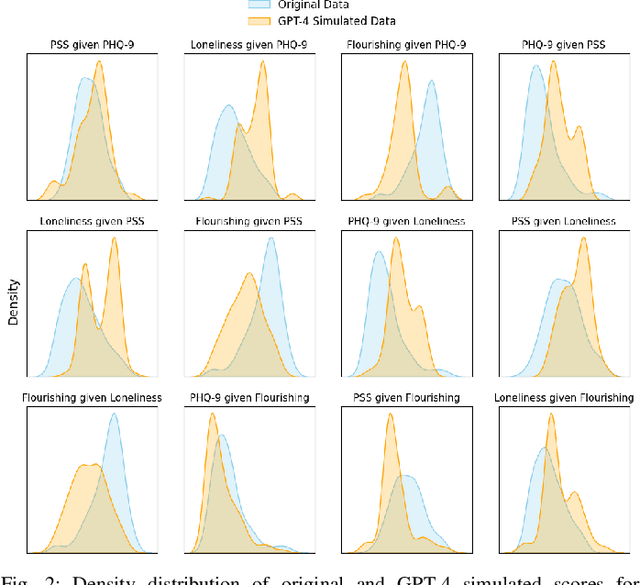
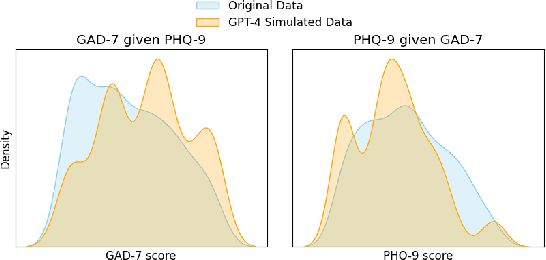
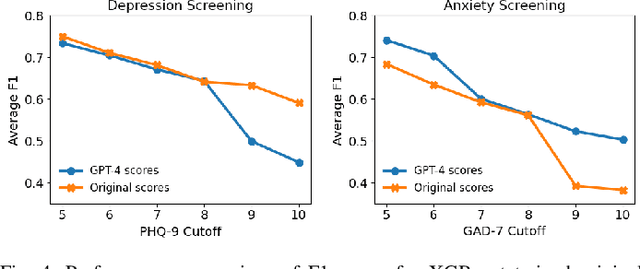
Advances in mobile and wearable technologies have enabled the potential to passively monitor a person's mental, behavioral, and affective health. These approaches typically rely on longitudinal collection of self-reported outcomes, e.g., depression, stress, and anxiety, to train machine learning (ML) models. However, the need to continuously self-report adds a significant burden on the participants, often resulting in attrition, missing labels, or insincere responses. In this work, we introduce the Scale Scores Simulation using Mental Models (SeSaMe) framework to alleviate participants' burden in digital mental health studies. By leveraging pre-trained large language models (LLMs), SeSaMe enables the simulation of participants' responses on psychological scales. In SeSaMe, researchers can prompt LLMs with information on participants' internal behavioral dispositions, enabling LLMs to construct mental models of participants to simulate their responses on psychological scales. We demonstrate an application of SeSaMe, where we use GPT-4 to simulate responses on one scale using responses from another as behavioral information. We also evaluate the alignment between human and SeSaMe-simulated responses to psychological scales. Then, we present experiments to inspect the utility of SeSaMe-simulated responses as ground truth in training ML models by replicating established depression and anxiety screening tasks from a previous study. Our results indicate SeSaMe to be a promising approach, but its alignment may vary across scales and specific prediction objectives. We also observed that model performance with simulated data was on par with using the real data for training in most evaluation scenarios. We conclude by discussing the potential implications of SeSaMe in addressing some challenges researchers face with ground-truth collection in passive sensing studies.