 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes AI Coaching Prepare us for Workplace Negotiations?
Sep 26, 2025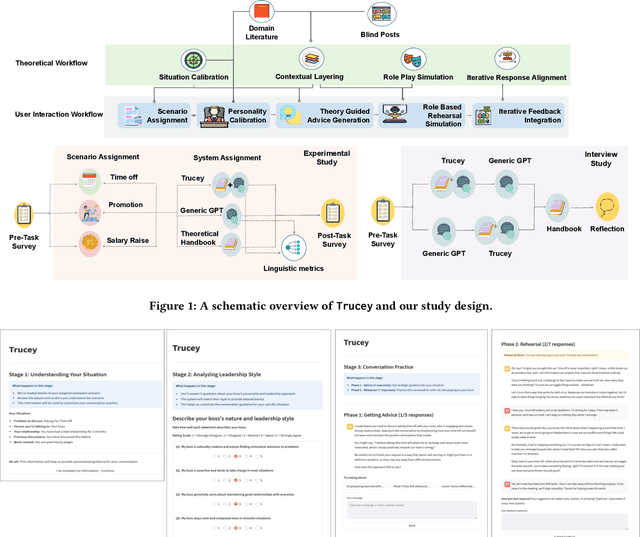
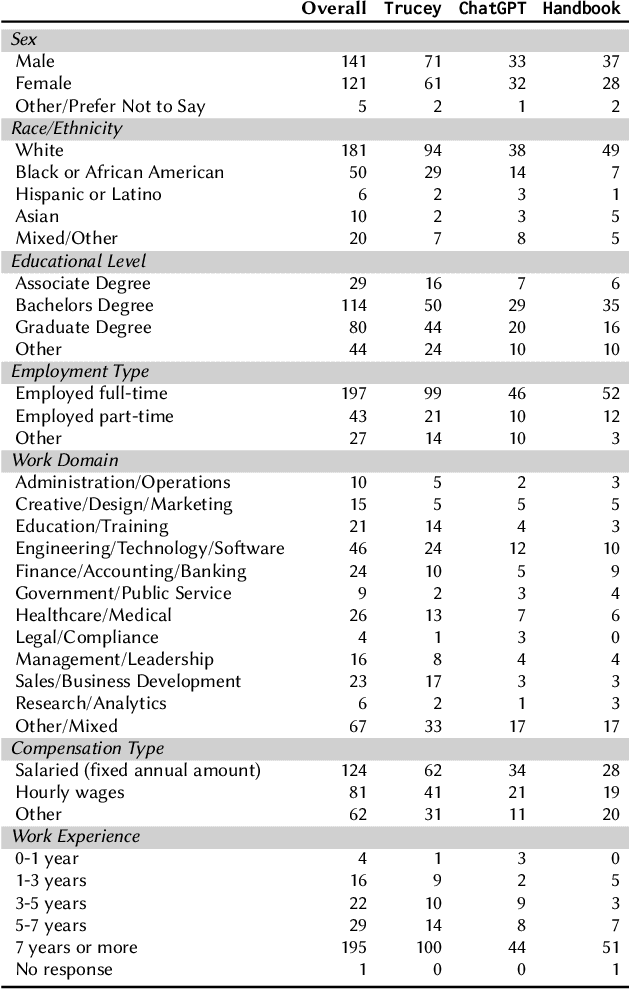
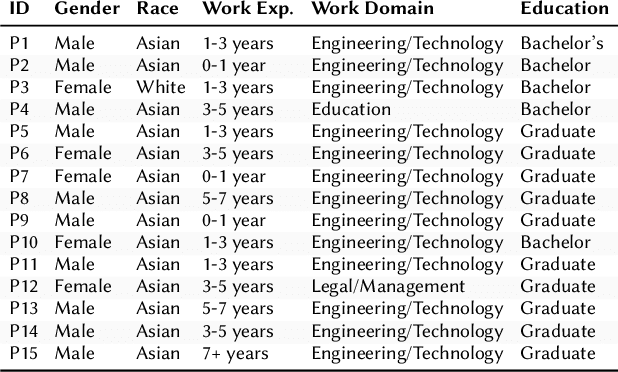
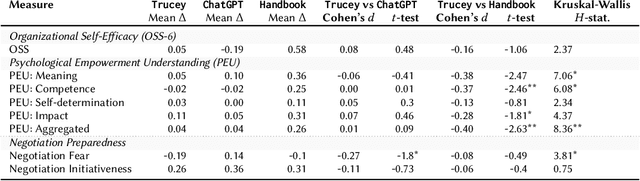
Workplace negotiations are undermined by psychological barriers, which can even derail well-prepared tactics. AI offers personalized and always -- available negotiation coaching, yet its effectiveness for negotiation preparedness remains unclear. We built Trucey, a prototype AI coach grounded in Brett's negotiation model. We conducted a between-subjects experiment (N=267), comparing Trucey, ChatGPT, and a traditional negotiation Handbook, followed by in-depth interviews (N=15). While Trucey showed the strongest reductions in fear relative to both comparison conditions, the Handbook outperformed both AIs in usability and psychological empowerment. Interviews revealed that the Handbook's comprehensive, reviewable content was crucial for participants' confidence and preparedness. In contrast, although participants valued AI's rehearsal capability, its guidance often felt verbose and fragmented -- delivered in bits and pieces that required additional effort -- leaving them uncertain or overwhelmed. These findings challenge assumptions of AI superiority and motivate hybrid designs that integrate structured, theory-driven content with targeted rehearsal, clear boundaries, and adaptive scaffolds to address psychological barriers and support negotiation preparedness.
RECOVER: Designing a Large Language Model-based Remote Patient Monitoring System for Postoperative Gastrointestinal Cancer Care
Feb 09, 2025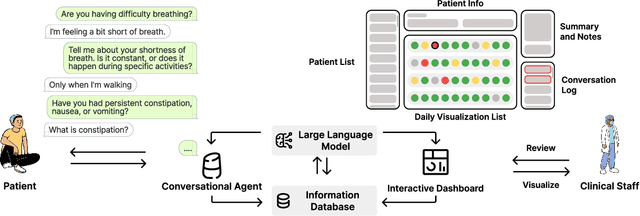

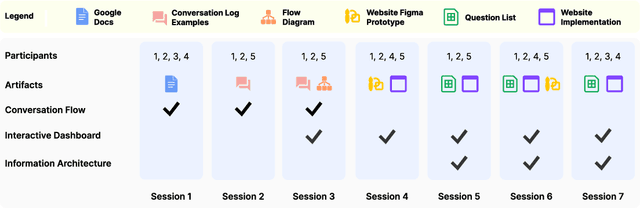
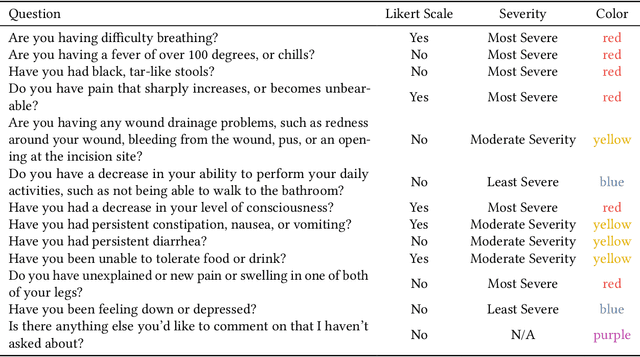
Cancer surgery is a key treatment for gastrointestinal (GI) cancers, a group of cancers that account for more than 35% of cancer-related deaths worldwide, but postoperative complications are unpredictable and can be life-threatening. In this paper, we investigate how recent advancements in large language models (LLMs) can benefit remote patient monitoring (RPM) systems through clinical integration by designing RECOVER, an LLM-powered RPM system for postoperative GI cancer care. To closely engage stakeholders in the design process, we first conducted seven participatory design sessions with five clinical staff and interviewed five cancer patients to derive six major design strategies for integrating clinical guidelines and information needs into LLM-based RPM systems. We then designed and implemented RECOVER, which features an LLM-powered conversational agent for cancer patients and an interactive dashboard for clinical staff to enable efficient postoperative RPM. Finally, we used RECOVER as a pilot system to assess the implementation of our design strategies with four clinical staff and five patients, providing design implications by identifying crucial design elements, offering insights on responsible AI, and outlining opportunities for future LLM-powered RPM systems.
Imputation Matters: A Deeper Look into an Overlooked Step in Longitudinal Health and Behavior Sensing Research
Dec 08, 2024Longitudinal passive sensing studies for health and behavior outcomes often have missing and incomplete data. Handling missing data effectively is thus a critical data processing and modeling step. Our formative interviews with researchers working in longitudinal health and behavior passive sensing revealed a recurring theme: most researchers consider imputation a low-priority step in their analysis and inference pipeline, opting to use simple and off-the-shelf imputation strategies without comprehensively evaluating its impact on study outcomes. Through this paper, we call attention to the importance of imputation. Using publicly available passive sensing datasets for depression, we show that prioritizing imputation can significantly impact the study outcomes -- with our proposed imputation strategies resulting in up to 31% improvement in AUROC to predict depression over the original imputation strategy. We conclude by discussing the challenges and opportunities with effective imputation in longitudinal sensing studies.
Navigating AI Fallibility: Examining People's Reactions and Perceptions of AI after Encountering Personality Misrepresentations
May 25, 2024Many hyper-personalized AI systems profile people's characteristics (e.g., personality traits) to provide personalized recommendations. These systems are increasingly used to facilitate interactions among people, such as providing teammate recommendations. Despite improved accuracy, such systems are not immune to errors when making inferences about people's most personal traits. These errors manifested as AI misrepresentations. However, the repercussions of such AI misrepresentations are unclear, especially on people's reactions and perceptions of the AI. We present two studies to examine how people react and perceive the AI after encountering personality misrepresentations in AI-facilitated team matching in a higher education context. Through semi-structured interviews (n=20) and a survey experiment (n=198), we pinpoint how people's existing and newly acquired AI knowledge could shape their perceptions and reactions of the AI after encountering AI misrepresentations. Specifically, we identified three rationales that people adopted through knowledge acquired from AI (mis)representations: AI works like a machine, human, and/or magic. These rationales are highly connected to people's reactions of over-trusting, rationalizing, and forgiving of AI misrepresentations. Finally, we found that people's existing AI knowledge, i.e., AI literacy, could moderate people's changes in their trust in AI after encountering AI misrepresentations, but not changes in people's social perceptions of AI. We discuss the role of people's AI knowledge when facing AI fallibility and implications for designing responsible mitigation and repair strategies.
SeSaMe: A Framework to Simulate Self-Reported Ground Truth for Mental Health Sensing Studies
Mar 27, 2024
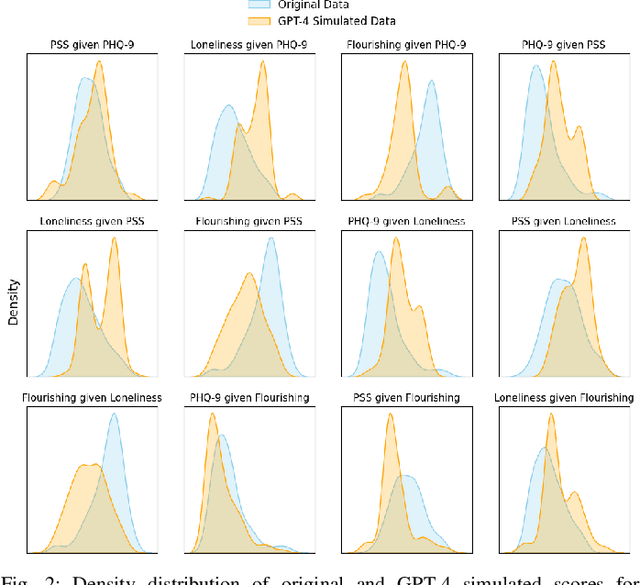
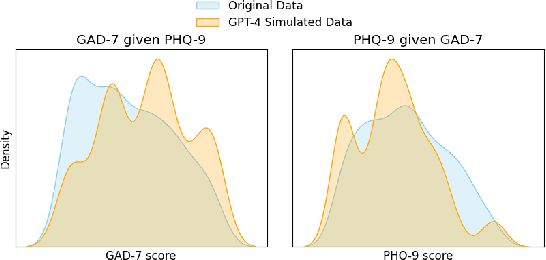
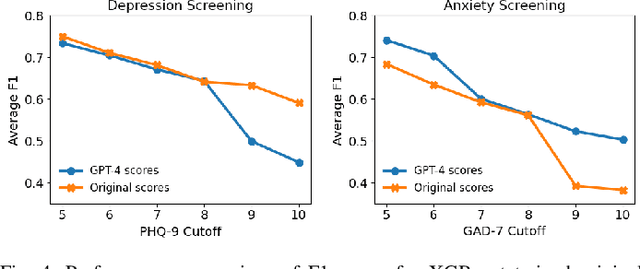
Advances in mobile and wearable technologies have enabled the potential to passively monitor a person's mental, behavioral, and affective health. These approaches typically rely on longitudinal collection of self-reported outcomes, e.g., depression, stress, and anxiety, to train machine learning (ML) models. However, the need to continuously self-report adds a significant burden on the participants, often resulting in attrition, missing labels, or insincere responses. In this work, we introduce the Scale Scores Simulation using Mental Models (SeSaMe) framework to alleviate participants' burden in digital mental health studies. By leveraging pre-trained large language models (LLMs), SeSaMe enables the simulation of participants' responses on psychological scales. In SeSaMe, researchers can prompt LLMs with information on participants' internal behavioral dispositions, enabling LLMs to construct mental models of participants to simulate their responses on psychological scales. We demonstrate an application of SeSaMe, where we use GPT-4 to simulate responses on one scale using responses from another as behavioral information. We also evaluate the alignment between human and SeSaMe-simulated responses to psychological scales. Then, we present experiments to inspect the utility of SeSaMe-simulated responses as ground truth in training ML models by replicating established depression and anxiety screening tasks from a previous study. Our results indicate SeSaMe to be a promising approach, but its alignment may vary across scales and specific prediction objectives. We also observed that model performance with simulated data was on par with using the real data for training in most evaluation scenarios. We conclude by discussing the potential implications of SeSaMe in addressing some challenges researchers face with ground-truth collection in passive sensing studies.