 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-Sensitive Offline Contextual Bandits
Oct 31, 2025Offline contextual bandits allow one to learn policies from historical/offline data without requiring online interaction. However, offline policy optimization that maximizes overall expected rewards can unintentionally amplify the reward disparities across groups. As a result, some groups might benefit more than others from the learned policy, raising concerns about fairness, especially when the resources are limited. In this paper, we study a group-sensitive fairness constraint in offline contextual bandits, reducing group-wise reward disparities that may arise during policy learning. We tackle the following common-parity requirements: the reward disparity is constrained within some user-defined threshold or the reward disparity should be minimized during policy optimization. We propose a constrained offline policy optimization framework by introducing group-wise reward disparity constraints into an off-policy gradient-based optimization procedure. To improve the estimation of the group-wise reward disparity during training, we employ a doubly robust estimator and further provide a convergence guarantee for policy optimization. Empirical results in synthetic and real-world datasets demonstrate that our method effectively reduces reward disparities while maintaining competitive overall performance.
RECOVER: Designing a Large Language Model-based Remote Patient Monitoring System for Postoperative Gastrointestinal Cancer Care
Feb 09, 2025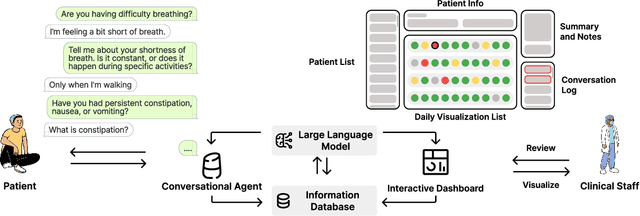

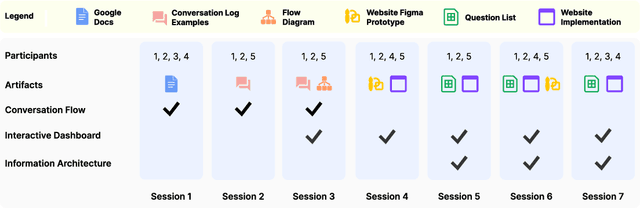
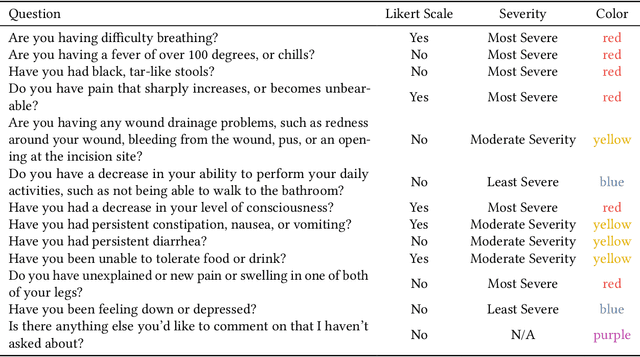
Cancer surgery is a key treatment for gastrointestinal (GI) cancers, a group of cancers that account for more than 35% of cancer-related deaths worldwide, but postoperative complications are unpredictable and can be life-threatening. In this paper, we investigate how recent advancements in large language models (LLMs) can benefit remote patient monitoring (RPM) systems through clinical integration by designing RECOVER, an LLM-powered RPM system for postoperative GI cancer care. To closely engage stakeholders in the design process, we first conducted seven participatory design sessions with five clinical staff and interviewed five cancer patients to derive six major design strategies for integrating clinical guidelines and information needs into LLM-based RPM systems. We then designed and implemented RECOVER, which features an LLM-powered conversational agent for cancer patients and an interactive dashboard for clinical staff to enable efficient postoperative RPM. Finally, we used RECOVER as a pilot system to assess the implementation of our design strategies with four clinical staff and five patients, providing design implications by identifying crucial design elements, offering insights on responsible AI, and outlining opportunities for future LLM-powered RPM systems.
Patient ADE Risk Prediction through Hierarchical Time-Aware Neural Network Using Claim Codes
Aug 20, 2020
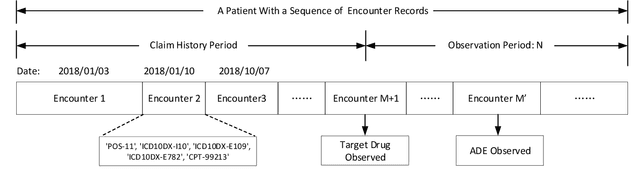
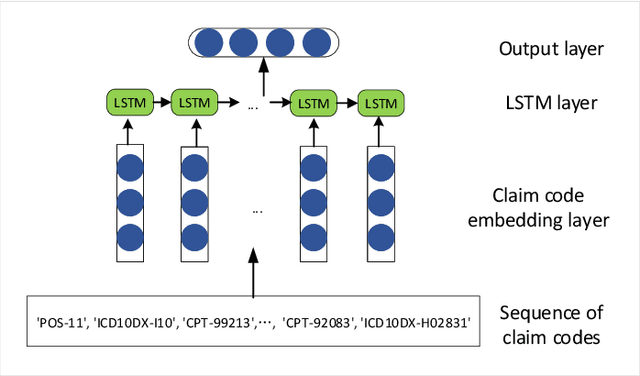
Adverse drug events (ADEs) are a serious health problem that can be life-threatening. While a lot of studies have been performed on detect correlation between a drug and an AE, limited studies have been conducted on personalized ADE risk prediction. Among treatment alternatives, avoiding the drug that has high likelihood of causing severe AE can help physicians to provide safer treatment to patients. Existing work on personalized ADE risk prediction uses the information obtained in the current medical visit. However, on the other hand, medical history reveals each patient's unique characteristics and comprehensive medical information. The goal of this study is to assess personalized ADE risks that a target drug may induce on a target patient, based on patient medical history recorded in claims codes, which provide information about diagnosis, drugs taken, related medical supplies besides billing information. We developed a HTNNR model (Hierarchical Time-aware Neural Network for ADE Risk) that capture characteristics of claim codes and their relationship. The empirical evaluation show that the proposed HTNNR model substantially outperforms the comparison methods, especially for rare drugs.