 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaSemSeg: An Adaptive Few-shot Semantic Segmentation of Seismic Facies
Jan 28, 2025Automated interpretation of seismic images using deep learning methods is challenging because of the limited availability of training data. Few-shot learning is a suitable learning paradigm in such scenarios due to its ability to adapt to a new task with limited supervision (small training budget). Existing few-shot semantic segmentation (FSSS) methods fix the number of target classes. Therefore, they do not support joint training on multiple datasets varying in the number of classes. In the context of the interpretation of seismic facies, fixing the number of target classes inhibits the generalization capability of a model trained on one facies dataset to another, which is likely to have a different number of facies. To address this shortcoming, we propose a few-shot semantic segmentation method for interpreting seismic facies that can adapt to the varying number of facies across the dataset, dubbed the AdaSemSeg. In general, the backbone network of FSSS methods is initialized with the statistics learned from the ImageNet dataset for better performance. The lack of such a huge annotated dataset for seismic images motivates using a self-supervised algorithm on seismic datasets to initialize the backbone network. We have trained the AdaSemSeg on three public seismic facies datasets with different numbers of facies and evaluated the proposed method on multiple metrics. The performance of the AdaSemSeg on unseen datasets (not used in training) is better than the prototype-based few-shot method and baselines.
Disentanglement Analysis in Deep Latent Variable Models Matching Aggregate Posterior Distributions
Jan 26, 2025Deep latent variable models (DLVMs) are designed to learn meaningful representations in an unsupervised manner, such that the hidden explanatory factors are interpretable by independent latent variables (aka disentanglement). The variational autoencoder (VAE) is a popular DLVM widely studied in disentanglement analysis due to the modeling of the posterior distribution using a factorized Gaussian distribution that encourages the alignment of the latent factors with the latent axes. Several metrics have been proposed recently, assuming that the latent variables explaining the variation in data are aligned with the latent axes (cardinal directions). However, there are other DLVMs, such as the AAE and WAE-MMD (matching the aggregate posterior to the prior), where the latent variables might not be aligned with the latent axes. In this work, we propose a statistical method to evaluate disentanglement for any DLVMs in general. The proposed technique discovers the latent vectors representing the generative factors of a dataset that can be different from the cardinal latent axes. We empirically demonstrate the advantage of the method on two datasets.
ARD-VAE: A Statistical Formulation to Find the Relevant Latent Dimensions of Variational Autoencoders
Jan 18, 2025The variational autoencoder (VAE) is a popular, deep, latent-variable model (DLVM) due to its simple yet effective formulation for modeling the data distribution. Moreover, optimizing the VAE objective function is more manageable than other DLVMs. The bottleneck dimension of the VAE is a crucial design choice, and it has strong ramifications for the model's performance, such as finding the hidden explanatory factors of a dataset using the representations learned by the VAE. However, the size of the latent dimension of the VAE is often treated as a hyperparameter estimated empirically through trial and error. To this end, we propose a statistical formulation to discover the relevant latent factors required for modeling a dataset. In this work, we use a hierarchical prior in the latent space that estimates the variance of the latent axes using the encoded data, which identifies the relevant latent dimensions. For this, we replace the fixed prior in the VAE objective function with a hierarchical prior, keeping the remainder of the formulation unchanged. We call the proposed method the automatic relevancy detection in the variational autoencoder (ARD-VAE). We demonstrate the efficacy of the ARD-VAE on multiple benchmark datasets in finding the relevant latent dimensions and their effect on different evaluation metrics, such as FID score and disentanglement analysis.
Joint Audio-Visual Idling Vehicle Detection with Streamlined Input Dependencies
Oct 28, 2024

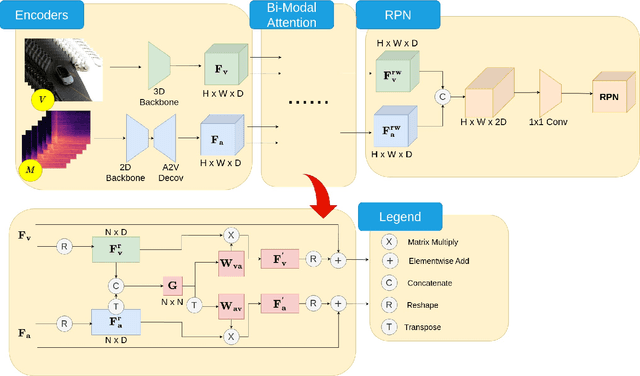

Idling vehicle detection (IVD) can be helpful in monitoring and reducing unnecessary idling and can be integrated into real-time systems to address the resulting pollution and harmful products. The previous approach [13], a non-end-to-end model, requires extra user clicks to specify a part of the input, making system deployment more error-prone or even not feasible. In contrast, we introduce an end-to-end joint audio-visual IVD task designed to detect vehicles visually under three states: moving, idling and engine off. Unlike feature co-occurrence task such as audio-visual vehicle tracking, our IVD task addresses complementary features, where labels cannot be determined by a single modality alone. To this end, we propose AVIVD-Net, a novel network that integrates audio and visual features through a bidirectional attention mechanism. AVIVD-Net streamlines the input process by learning a joint feature space, reducing the deployment complexity of previous methods. Additionally, we introduce the AVIVD dataset, which is seven times larger than previous datasets, offering significantly more annotated samples to study the IVD problem. Our model achieves performance comparable to prior approaches, making it suitable for automated deployment. Furthermore, by evaluating AVIVDNet on the feature co-occurrence public dataset MAVD [23], we demonstrate its potential for extension to self-driving vehicle video-camera setups.
Matching aggregate posteriors in the variational autoencoder
Nov 13, 2023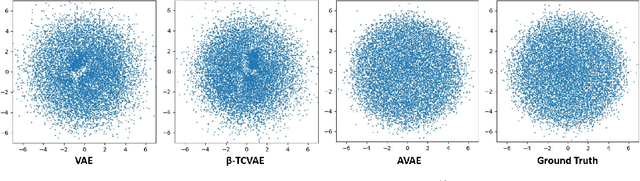

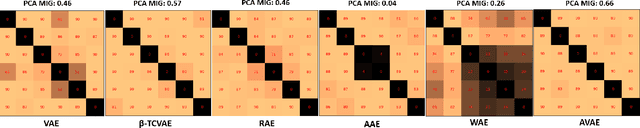
The variational autoencoder (VAE) is a well-studied, deep, latent-variable model (DLVM) that efficiently optimizes the variational lower bound of the log marginal data likelihood and has a strong theoretical foundation. However, the VAE's known failure to match the aggregate posterior often results in \emph{pockets/holes} in the latent distribution (i.e., a failure to match the prior) and/or \emph{posterior collapse}, which is associated with a loss of information in the latent space. This paper addresses these shortcomings in VAEs by reformulating the objective function associated with VAEs in order to match the aggregate/marginal posterior distribution to the prior. We use kernel density estimate (KDE) to model the aggregate posterior in high dimensions. The proposed method is named the \emph{aggregate variational autoencoder} (AVAE) and is built on the theoretical framework of the VAE. Empirical evaluation of the proposed method on multiple benchmark data sets demonstrates the effectiveness of the AVAE relative to state-of-the-art (SOTA) methods.
Real-Time Idling Vehicles Detection Using Combined Audio-Visual Deep Learning
May 23, 2023Combustion vehicle emissions contribute to poor air quality and release greenhouse gases into the atmosphere, and vehicle pollution has been associated with numerous adverse health effects. Roadways with extensive waiting and/or passenger drop off, such as schools and hospital drop-off zones, can result in high incidence and density of idling vehicles. This can produce micro-climates of increased vehicle pollution. Thus, the detection of idling vehicles can be helpful in monitoring and responding to unnecessary idling and be integrated into real-time or off-line systems to address the resulting pollution. In this paper we present a real-time, dynamic vehicle idling detection algorithm. The proposed idle detection algorithm and notification rely on an algorithm to detect these idling vehicles. The proposed method relies on a multi-sensor, audio-visual, machine-learning workflow to detect idling vehicles visually under three conditions: moving, static with the engine on, and static with the engine off. The visual vehicle motion detector is built in the first stage, and then a contrastive-learning-based latent space is trained for classifying static vehicle engine sound. We test our system in real-time at a hospital drop-off point in Salt Lake City. This in-situ dataset was collected and annotated, and it includes vehicles of varying models and types. The experiments show that the method can detect engine switching on or off instantly and achieves 71.01 mean average precision (mAP).
GENs: Generative Encoding Networks
Oct 28, 2020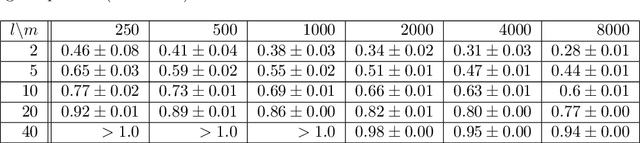

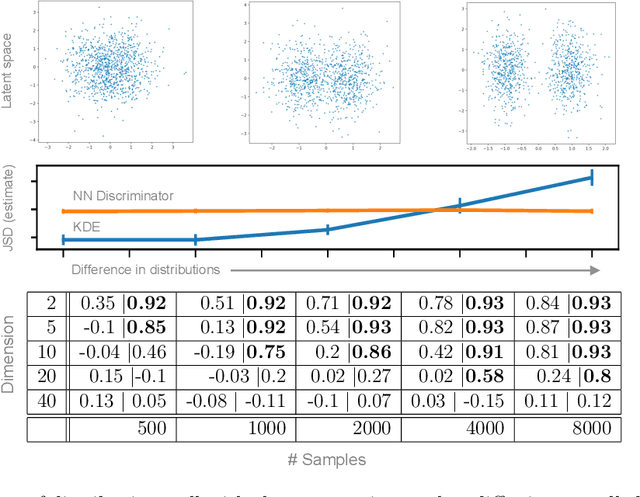

Mapping data from and/or onto a known family of distributions has become an important topic in machine learning and data analysis. Deep generative models (e.g., generative adversarial networks ) have been used effectively to match known and unknown distributions. Nonetheless, when the form of the target distribution is known, analytical methods are advantageous in providing robust results with provable properties. In this paper, we propose and analyze the use of nonparametric density methods to estimate the Jensen-Shannon divergence for matching unknown data distributions to known target distributions, such Gaussian or mixtures of Gaussians, in latent spaces. This analytical method has several advantages: better behavior when training sample quantity is low, provable convergence properties, and relatively few parameters, which can be derived analytically. Using the proposed method, we enforce the latent representation of an autoencoder to match a target distribution in a learning framework that we call a {\em generative encoding network}. Here, we present the numerical methods; derive the expected distribution of the data in the latent space; evaluate the properties of the latent space, sample reconstruction, and generated samples; show the advantages over the adversarial counterpart; and demonstrate the application of the method in real world.
Minimal Solvers for Mini-Loop Closures in 3D Multi-Scan Alignment
Apr 08, 2019



3D scan registration is a classical, yet a highly useful problem in the context of 3D sensors such as Kinect and Velodyne. While there are several existing methods, the techniques are usually incremental where adjacent scans are registered first to obtain the initial poses, followed by motion averaging and bundle-adjustment refinement. In this paper, we take a different approach and develop minimal solvers for jointly computing the initial poses of cameras in small loops such as 3-, 4-, and 5-cycles. Note that the classical registration of 2 scans can be done using a minimum of 3 point matches to compute 6 degrees of relative motion. On the other hand, to jointly compute the 3D registrations in n-cycles, we take 2 point matches between the first n-1 consecutive pairs (i.e., Scan 1 & Scan 2, ... , and Scan n-1 & Scan n) and 1 or 2 point matches between Scan 1 and Scan n. Overall, we use 5, 7, and 10 point matches for 3-, 4-, and 5-cycles, and recover 12, 18, and 24 degrees of transformation variables, respectively. Using simulations and real-data we show that the 3D registration using mini n-cycles are computationally efficient, and can provide alternate and better initial poses compared to standard pairwise methods.
* 10 pages, 5 figures, 5 tables