 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Markovian View of Iterative-Feedback Loops in Image Generative Models: Neural Resonance and Model Collapse
Feb 22, 2026AI training datasets will inevitably contain AI-generated examples, leading to ``feedback'' in which the output of one model impacts the training of another. It is known that such iterative feedback can lead to model collapse, yet the mechanisms underlying this degeneration remain poorly understood. Here we show that a broad class of feedback processes converges to a low-dimensional invariant structure in latent space, a phenomenon we call neural resonance. By modeling iterative feedback as a Markov Chain, we show that two conditions are needed for this resonance to occur: ergodicity of the feedback process and directional contraction of the latent representation. By studying diffusion models on MNIST and ImageNet, as well as CycleGAN and an audio feedback experiment, we map how local and global manifold geometry evolve, and we introduce an eight-pattern taxonomy of collapse behaviors. Neural resonance provides a unified explanation for long-term degenerate behavior in generative models and provides practical diagnostics for identifying, characterizing, and eventually mitigating collapse.
GateFusion: Hierarchical Gated Cross-Modal Fusion for Active Speaker Detection
Dec 17, 2025Active Speaker Detection (ASD) aims to identify who is currently speaking in each frame of a video. Most state-of-the-art approaches rely on late fusion to combine visual and audio features, but late fusion often fails to capture fine-grained cross-modal interactions, which can be critical for robust performance in unconstrained scenarios. In this paper, we introduce GateFusion, a novel architecture that combines strong pretrained unimodal encoders with a Hierarchical Gated Fusion Decoder (HiGate). HiGate enables progressive, multi-depth fusion by adaptively injecting contextual features from one modality into the other at multiple layers of the Transformer backbone, guided by learnable, bimodally-conditioned gates. To further strengthen multimodal learning, we propose two auxiliary objectives: Masked Alignment Loss (MAL) to align unimodal outputs with multimodal predictions, and Over-Positive Penalty (OPP) to suppress spurious video-only activations. GateFusion establishes new state-of-the-art results on several challenging ASD benchmarks, achieving 77.8% mAP (+9.4%), 86.1% mAP (+2.9%), and 96.1% mAP (+0.5%) on Ego4D-ASD, UniTalk, and WASD benchmarks, respectively, and delivering competitive performance on AVA-ActiveSpeaker. Out-of-domain experiments demonstrate the generalization of our model, while comprehensive ablations show the complementary benefits of each component.
Issues with Neural Tangent Kernel Approach to Neural Networks
Jan 19, 2025


Neural tangent kernels (NTKs) have been proposed to study the behavior of trained neural networks from the perspective of Gaussian processes. An important result in this body of work is the theorem of equivalence between a trained neural network and kernel regression with the corresponding NTK. This theorem allows for an interpretation of neural networks as special cases of kernel regression. However, does this theorem of equivalence hold in practice? In this paper, we revisit the derivation of the NTK rigorously and conduct numerical experiments to evaluate this equivalence theorem. We observe that adding a layer to a neural network and the corresponding updated NTK do not yield matching changes in the predictor error. Furthermore, we observe that kernel regression with a Gaussian process kernel in the literature that does not account for neural network training produces prediction errors very close to that of kernel regression with NTKs. These observations suggest the equivalence theorem does not hold well in practice and puts into question whether neural tangent kernels adequately address the training process of neural networks.
GC-MVSNet: Multi-View, Multi-Scale, Geometrically-Consistent Multi-View Stereo
Oct 30, 2023Traditional multi-view stereo (MVS) methods rely heavily on photometric and geometric consistency constraints, but newer machine learning-based MVS methods check geometric consistency across multiple source views only as a post-processing step. In this paper, we present a novel approach that explicitly encourages geometric consistency of reference view depth maps across multiple source views at different scales during learning (see Fig. 1). We find that adding this geometric consistency loss significantly accelerates learning by explicitly penalizing geometrically inconsistent pixels, reducing the training iteration requirements to nearly half that of other MVS methods. Our extensive experiments show that our approach achieves a new state-of-the-art on the DTU and BlendedMVS datasets, and competitive results on the Tanks and Temples benchmark. To the best of our knowledge, GC-MVSNet is the first attempt to enforce multi-view, multi-scale geometric consistency during learning.
* Accepted in WACV 2024
Adversarial Attack in the Context of Self-driving
Apr 05, 2021
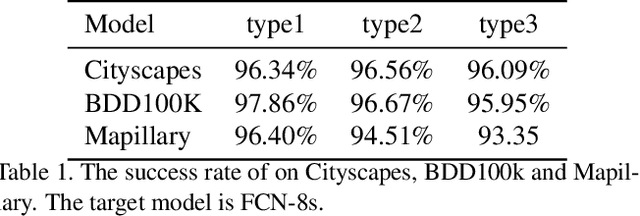
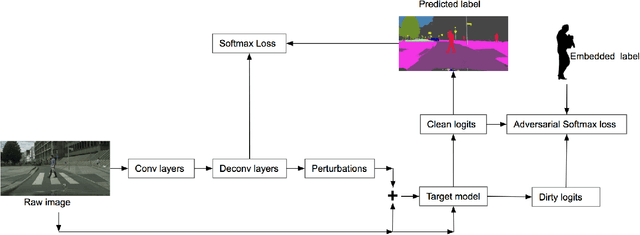
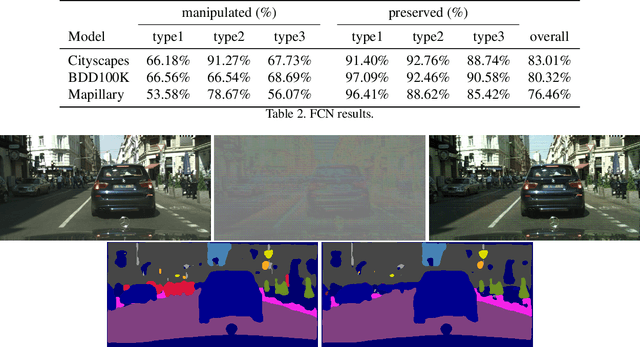
In this paper, we propose a model that can attack segmentation models with semantic and dynamic targets in the context of self-driving. Specifically, our model is designed to map an input image as well as its corresponding label to perturbations. After adding the perturbation to the input image, the adversarial example can manipulate the labels of the pixels in a semantically meaningful way on dynamic targets. In this way, we can make a potential attack subtle and stealthy. To evaluate the stealthiness of our attacking model, we design three types of tasks, including hiding true labels in the context, generating fake labels, and displacing labels that belong to some category. The experiments show that our model can attack segmentation models efficiently with a relatively high success rate on Cityscapes, Mapillary, and BDD100K. We also evaluate the generalization of our model across different datasets. Finally, we propose a new metric to evaluate the parameter-wise efficiency of attacking models by comparing the number of parameters used by both the attacking models and the target models.
Stepwise Goal-Driven Networks for Trajectory Prediction
Mar 25, 2021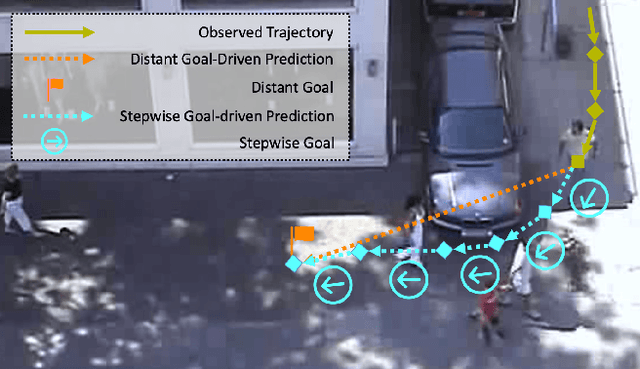
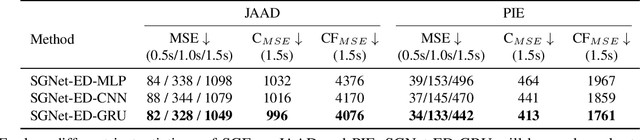
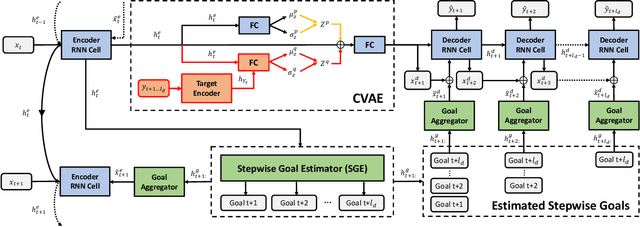
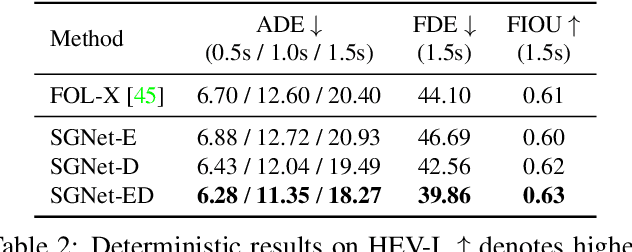
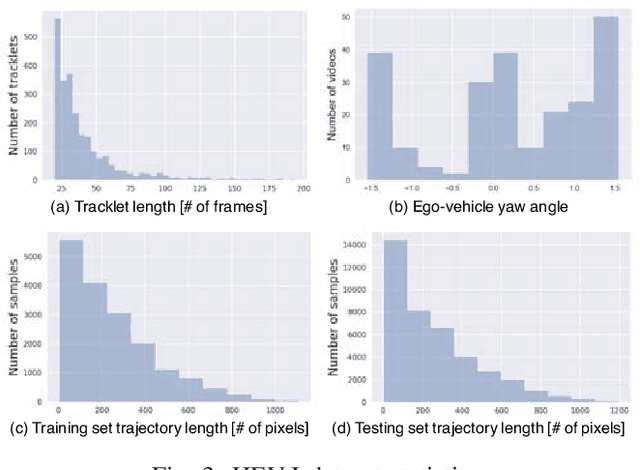
We propose to predict the future trajectories of observed agents (e.g., pedestrians or vehicles) by estimating and using their goals at multiple time scales. We argue that the goal of a moving agent may change over time, and modeling goals continuously provides more accurate and detailed information for future trajectory estimation. In this paper, we present a novel recurrent network for trajectory prediction, called Stepwise Goal-Driven Network (SGNet). Unlike prior work that models only a single, long-term goal, SGNet estimates and uses goals at multiple temporal scales. In particular, the framework incorporates an encoder module that captures historical information, a stepwise goal estimator that predicts successive goals into the future, and a decoder module that predicts future trajectory. We evaluate our model on three first-person traffic datasets (HEV-I, JAAD, and PIE) as well as on two bird's eye view datasets (ETH and UCY), and show that our model outperforms the state-of-the-art methods in terms of both average and final displacement errors on all datasets. Code has been made available at: https://github.com/ChuhuaW/SGNet.pytorch.
Dynamic Dual-Attentive Aggregation Learning for Visible-Infrared Person Re-Identification
Jul 18, 2020

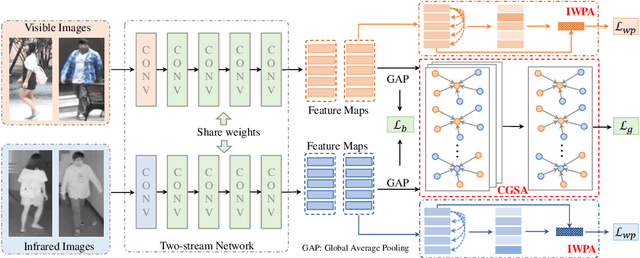

Visible-infrared person re-identification (VI-ReID) is a challenging cross-modality pedestrian retrieval problem. Due to the large intra-class variations and cross-modality discrepancy with large amount of sample noise, it is difficult to learn discriminative part features. Existing VI-ReID methods instead tend to learn global representations, which have limited discriminability and weak robustness to noisy images. In this paper, we propose a novel dynamic dual-attentive aggregation (DDAG) learning method by mining both intra-modality part-level and cross-modality graph-level contextual cues for VI-ReID. We propose an intra-modality weighted-part attention module to extract discriminative part-aggregated features, by imposing the domain knowledge on the part relationship mining. To enhance robustness against noisy samples, we introduce cross-modality graph structured attention to reinforce the representation with the contextual relations across the two modalities. We also develop a parameter-free dynamic dual aggregation learning strategy to adaptively integrate the two components in a progressive joint training manner. Extensive experiments demonstrate that DDAG outperforms the state-of-the-art methods under various settings.
Egocentric Vision-based Future Vehicle Localization for Intelligent Driving Assistance Systems
Mar 03, 2019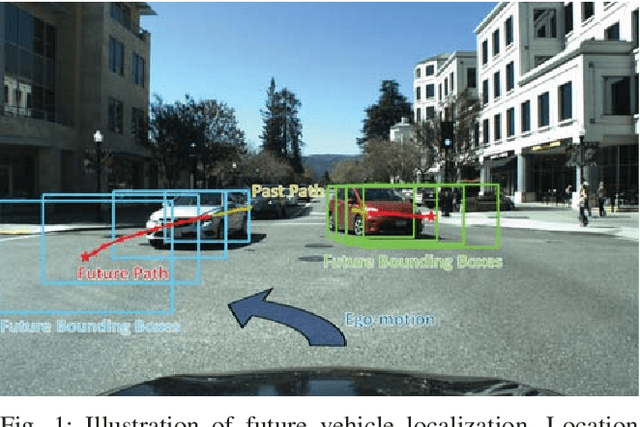
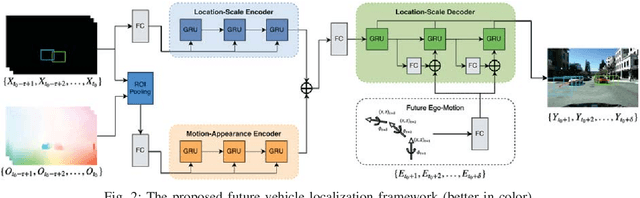

Predicting the future location of vehicles is essential for safety-critical applications such as advanced driver assistance systems (ADAS) and autonomous driving. This paper introduces a novel approach to simultaneously predict both the location and scale of target vehicles in the first-person (egocentric) view of an ego-vehicle. We present a multi-stream recurrent neural network (RNN) encoder-decoder model that separately captures both object location and scale and pixel-level observations for future vehicle localization. We show that incorporating dense optical flow improves prediction results significantly since it captures information about motion as well as appearance change. We also find that explicitly modeling future motion of the ego-vehicle improves the prediction accuracy, which could be especially beneficial in intelligent and automated vehicles that have motion planning capability. To evaluate the performance of our approach, we present a new dataset of first-person videos collected from a variety of scenarios at road intersections, which are particularly challenging moments for prediction because vehicle trajectories are diverse and dynamic.
Unsupervised Traffic Accident Detection in First-Person Videos
Mar 02, 2019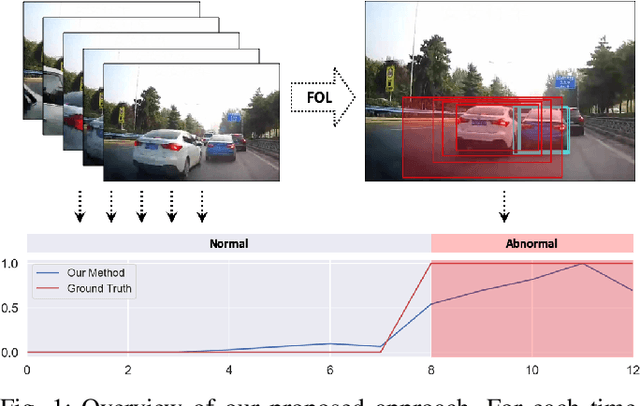
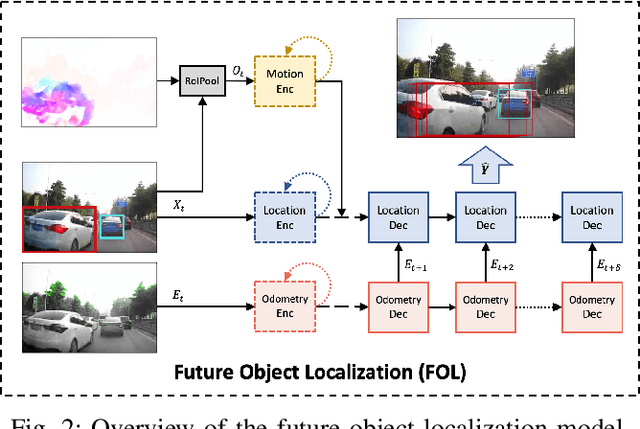
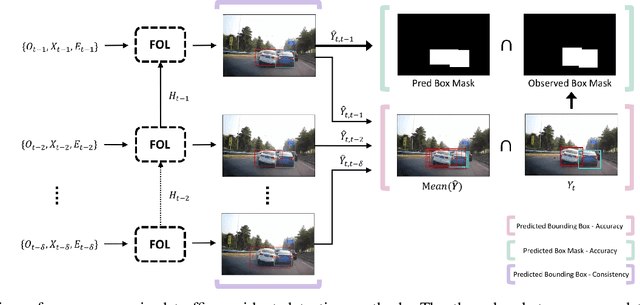
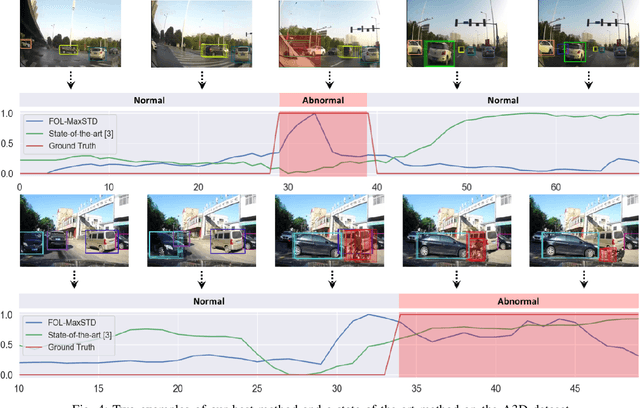
Recognizing abnormal events such as traffic violations and accidents in natural driving scenes is essential for successful autonomous and advanced driver assistance systems. However, most work on video anomaly detection suffers from one of two crucial drawbacks. First, it assumes cameras are fixed and videos have a static background, which is reasonable for surveillance applications but not for vehicle-mounted cameras. Second, it poses the problem as one-class classification, which relies on arduous human annotation and only recognizes categories of anomalies that have been explicitly trained. In this paper, we propose an unsupervised approach for traffic accident detection in first-person videos. Our major novelty is to detect anomalies by predicting the future locations of traffic participants and then monitoring the prediction accuracy and consistency metrics with three different strategies. To evaluate our approach, we introduce a new dataset of diverse traffic accidents, AnAn Accident Detection (A3D), as well as another publicly-available dataset. Experimental results show that our approach outperforms the state-of-the-art.
Temporal Recurrent Networks for Online Action Detection
Nov 18, 2018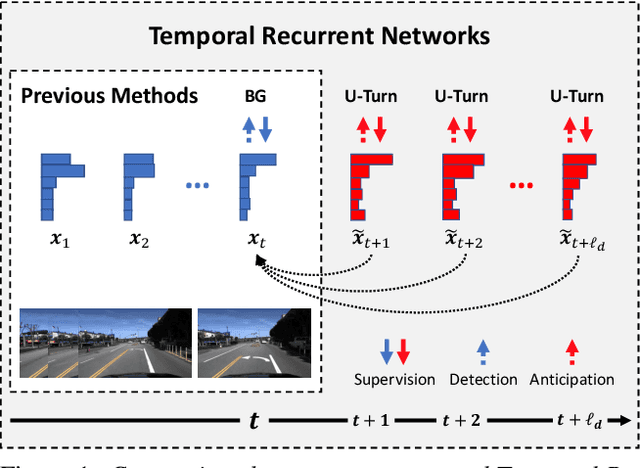
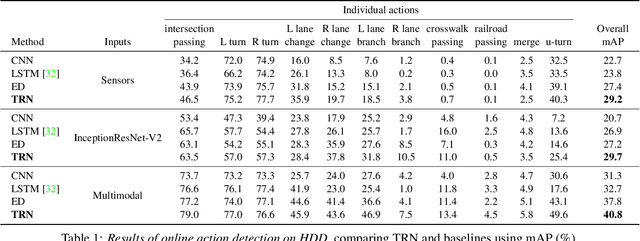
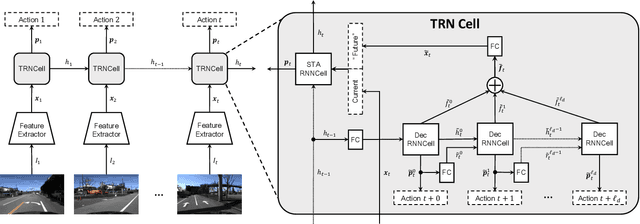
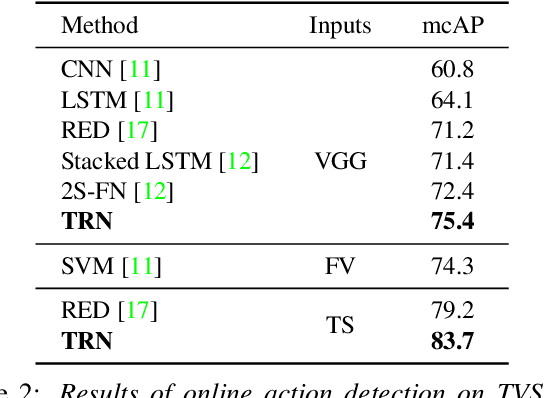
Most work on temporal action detection is formulated in an offline manner, in which the start and end times of actions are determined after the entire video is fully observed. However, real-time applications including surveillance and driver assistance systems require identifying actions as soon as each video frame arrives, based only on current and historical observations. In this paper, we propose a novel framework, Temporal Recurrent Networks (TRNs), to model greater temporal context of a video frame by simultaneously performing online action detection and anticipation of the immediate future. At each moment in time, our approach makes use of both accumulated historical evidence and predicted future information to better recognize the action that is currently occurring, and integrates both of these into a unified end-to-end architecture. We evaluate our approach on two popular online action detection datasets, HDD and TVSeries, as well as another widely used dataset, THUMOS'14. The results show that TRN significantly outperforms the state-of-the-art.