 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLaMo 2 Technical Report
Sep 05, 2025In this report, we introduce PLaMo 2, a series of Japanese-focused large language models featuring a hybrid Samba-based architecture that transitions to full attention via continual pre-training to support 32K token contexts. Training leverages extensive synthetic corpora to overcome data scarcity, while computational efficiency is achieved through weight reuse and structured pruning. This efficient pruning methodology produces an 8B model that achieves performance comparable to our previous 100B model. Post-training further refines the models using a pipeline of supervised fine-tuning (SFT) and direct preference optimization (DPO), enhanced by synthetic Japanese instruction data and model merging techniques. Optimized for inference using vLLM and quantization with minimal accuracy loss, the PLaMo 2 models achieve state-of-the-art results on Japanese benchmarks, outperforming similarly-sized open models in instruction-following, language fluency, and Japanese-specific knowledge.
Joint Search of Data Augmentation Policies and Network Architectures
Jan 12, 2021
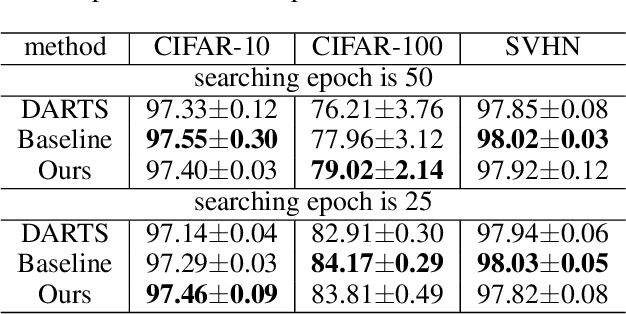
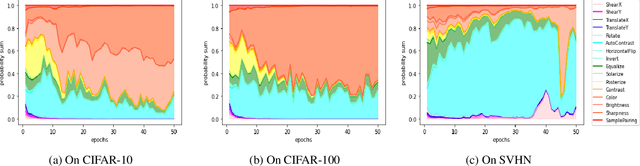
The common pipeline of training deep neural networks consists of several building blocks such as data augmentation and network architecture selection. AutoML is a research field that aims at automatically designing those parts, but most methods explore each part independently because it is more challenging to simultaneously search all the parts. In this paper, we propose a joint optimization method for data augmentation policies and network architectures to bring more automation to the design of training pipeline. The core idea of our approach is to make the whole part differentiable. The proposed method combines differentiable methods for augmentation policy search and network architecture search to jointly optimize them in the end-to-end manner. The experimental results show our method achieves competitive or superior performance to the independently searched results.
Addressing Class Imbalance in Scene Graph Parsing by Learning to Contrast and Score
Oct 05, 2020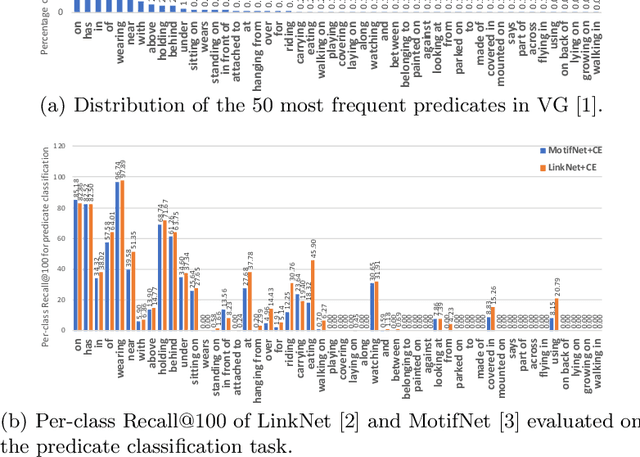
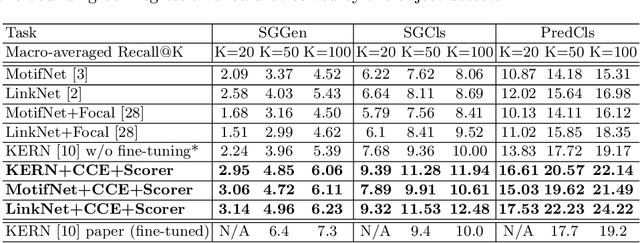
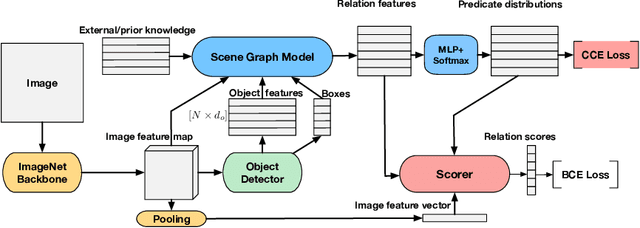
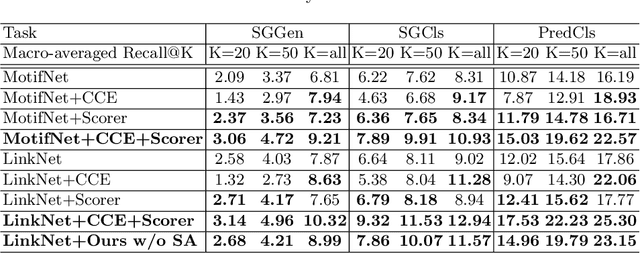
Scene graph parsing aims to detect objects in an image scene and recognize their relations. Recent approaches have achieved high average scores on some popular benchmarks, but fail in detecting rare relations, as the highly long-tailed distribution of data biases the learning towards frequent labels. Motivated by the fact that detecting these rare relations can be critical in real-world applications, this paper introduces a novel integrated framework of classification and ranking to resolve the class imbalance problem in scene graph parsing. Specifically, we design a new Contrasting Cross-Entropy loss, which promotes the detection of rare relations by suppressing incorrect frequent ones. Furthermore, we propose a novel scoring module, termed as Scorer, which learns to rank the relations based on the image features and relation features to improve the recall of predictions. Our framework is simple and effective, and can be incorporated into current scene graph models. Experimental results show that the proposed approach improves the current state-of-the-art methods, with a clear advantage of detecting rare relations.
Chainer: A Deep Learning Framework for Accelerating the Research Cycle
Aug 01, 2019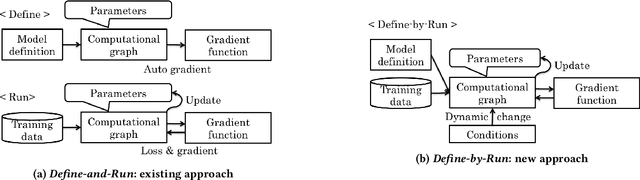


Software frameworks for neural networks play a key role in the development and application of deep learning methods. In this paper, we introduce the Chainer framework, which intends to provide a flexible, intuitive, and high performance means of implementing the full range of deep learning models needed by researchers and practitioners. Chainer provides acceleration using Graphics Processing Units with a familiar NumPy-like API through CuPy, supports general and dynamic models in Python through Define-by-Run, and also provides add-on packages for state-of-the-art computer vision models as well as distributed training.
TGANv2: Efficient Training of Large Models for Video Generation with Multiple Subsampling Layers
Nov 22, 2018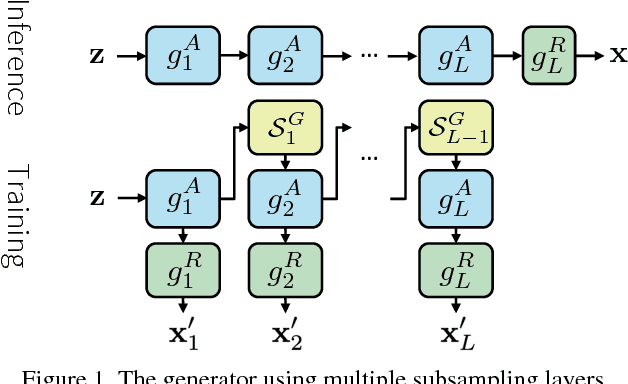
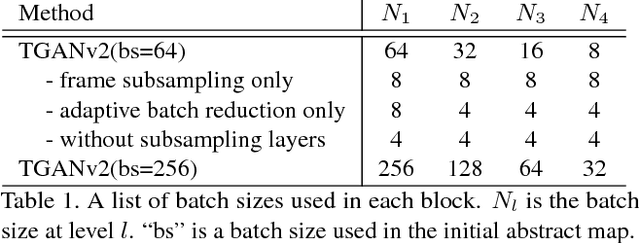
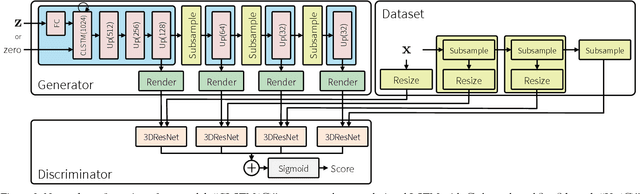

In this paper, we propose a novel method to efficiently train a Generative Adversarial Network (GAN) on high dimensional samples. The key idea is to introduce a differentiable subsampling layer which appropriately reduces the dimensionality of intermediate feature maps in the generator during training. In general, generators require large memory and computational costs in the latter stages of the network as the feature maps become larger, though the latter stages have relatively fewer parameters than the earlier stages. It makes training large models for video generation difficult due to the limited computational resource. We solve this problem by introducing a method that gradually reduces the dimensionality of feature maps in the generator with multiple subsampling layers. We also propose a network (Temporal GAN v2) with such layers and perform video generation experiments. As a consequence, our model trained on the UCF101 dataset at $192 \times 192$ pixels achieves an Inception Score (IS) of 24.34, which shows a significant improvement over the previous state-of-the-art score of 14.56.
Minimizing Supervision for Free-space Segmentation
Apr 18, 2018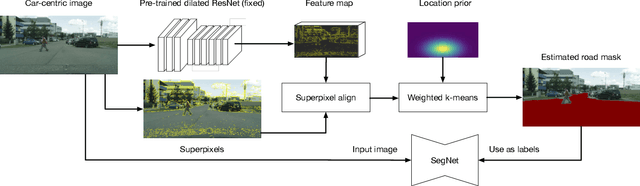

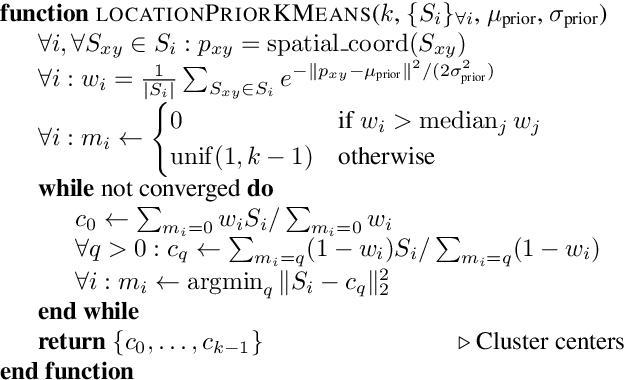

Identifying "free-space," or safely driveable regions in the scene ahead, is a fundamental task for autonomous navigation. While this task can be addressed using semantic segmentation, the manual labor involved in creating pixelwise annotations to train the segmentation model is very costly. Although weakly supervised segmentation addresses this issue, most methods are not designed for free-space. In this paper, we observe that homogeneous texture and location are two key characteristics of free-space, and develop a novel, practical framework for free-space segmentation with minimal human supervision. Our experiments show that our framework performs better than other weakly supervised methods while using less supervision. Our work demonstrates the potential for performing free-space segmentation without tedious and costly manual annotation, which will be important for adapting autonomous driving systems to different types of vehicles and environments
ChainerCV: a Library for Deep Learning in Computer Vision
Aug 28, 2017


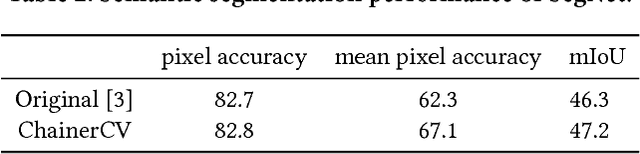
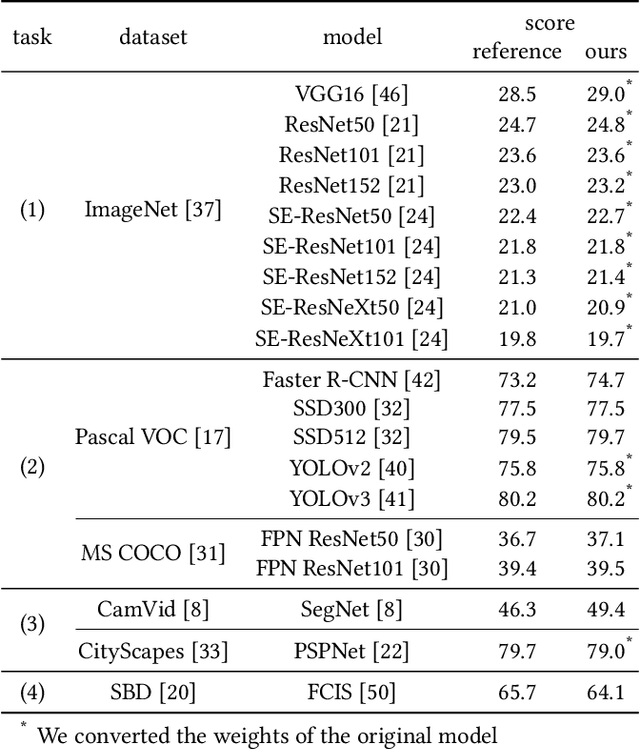
Despite significant progress of deep learning in the field of computer vision, there has not been a software library that covers these methods in a unifying manner. We introduce ChainerCV, a software library that is intended to fill this gap. ChainerCV supports numerous neural network models as well as software components needed to conduct research in computer vision. These implementations emphasize simplicity, flexibility and good software engineering practices. The library is designed to perform on par with the results reported in published papers and its tools can be used as a baseline for future research in computer vision. Our implementation includes sophisticated models like Faster R-CNN and SSD, and covers tasks such as object detection and semantic segmentation.
Distantly Supervised Road Segmentation
Aug 21, 2017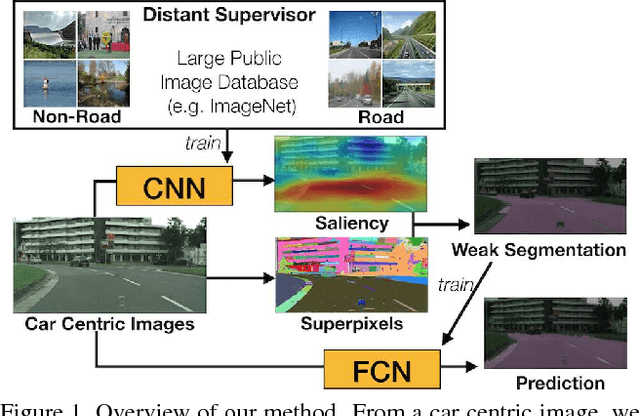

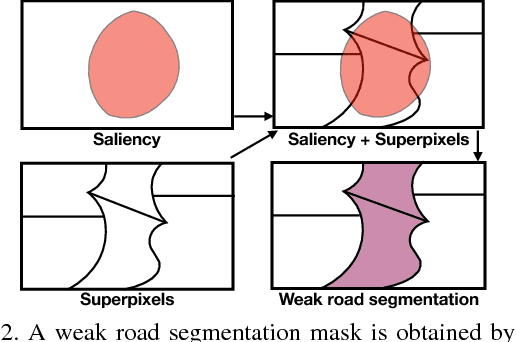
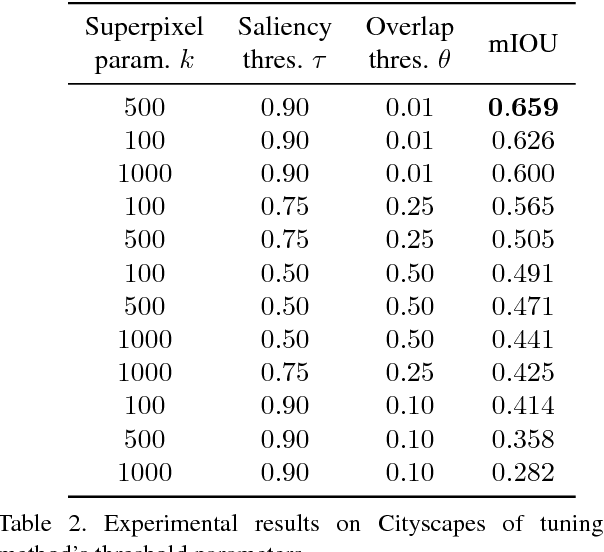
We present an approach for road segmentation that only requires image-level annotations at training time. We leverage distant supervision, which allows us to train our model using images that are different from the target domain. Using large publicly available image databases as distant supervisors, we develop a simple method to automatically generate weak pixel-wise road masks. These are used to iteratively train a fully convolutional neural network, which produces our final segmentation model. We evaluate our method on the Cityscapes dataset, where we compare it with a fully supervised approach. Further, we discuss the trade-off between annotation cost and performance. Overall, our distantly supervised approach achieves 93.8% of the performance of the fully supervised approach, while using orders of magnitude less annotation work.
Temporal Generative Adversarial Nets with Singular Value Clipping
Aug 18, 2017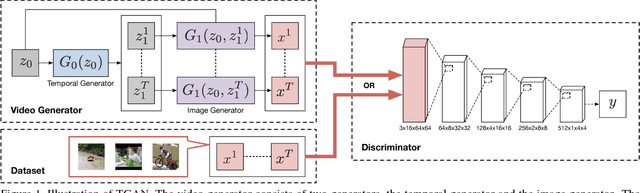
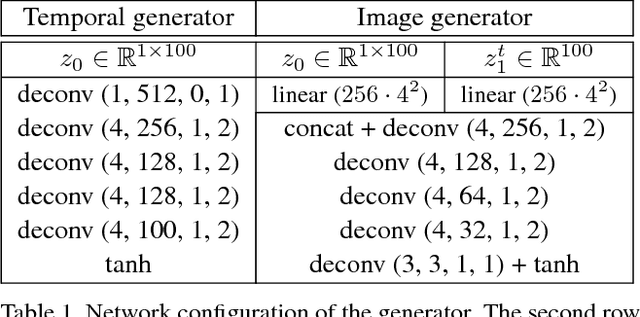


In this paper, we propose a generative model, Temporal Generative Adversarial Nets (TGAN), which can learn a semantic representation of unlabeled videos, and is capable of generating videos. Unlike existing Generative Adversarial Nets (GAN)-based methods that generate videos with a single generator consisting of 3D deconvolutional layers, our model exploits two different types of generators: a temporal generator and an image generator. The temporal generator takes a single latent variable as input and outputs a set of latent variables, each of which corresponds to an image frame in a video. The image generator transforms a set of such latent variables into a video. To deal with instability in training of GAN with such advanced networks, we adopt a recently proposed model, Wasserstein GAN, and propose a novel method to train it stably in an end-to-end manner. The experimental results demonstrate the effectiveness of our methods.