 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarp-Refine Propagation: Semi-Supervised Auto-labeling via Cycle-consistency
Sep 28, 2021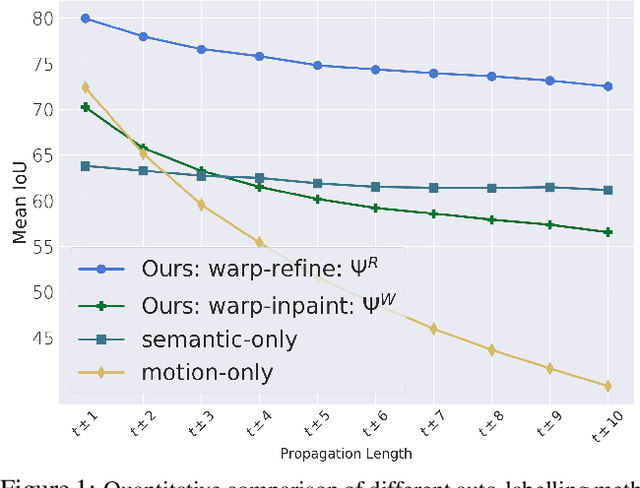
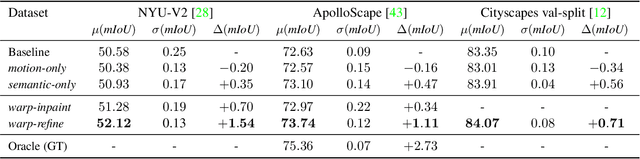
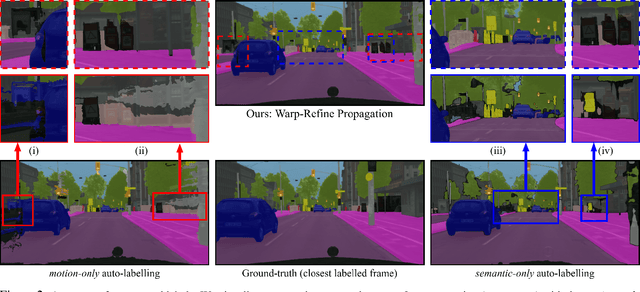

Deep learning models for semantic segmentation rely on expensive, large-scale, manually annotated datasets. Labelling is a tedious process that can take hours per image. Automatically annotating video sequences by propagating sparsely labeled frames through time is a more scalable alternative. In this work, we propose a novel label propagation method, termed Warp-Refine Propagation, that combines semantic cues with geometric cues to efficiently auto-label videos. Our method learns to refine geometrically-warped labels and infuse them with learned semantic priors in a semi-supervised setting by leveraging cycle consistency across time. We quantitatively show that our method improves label-propagation by a noteworthy margin of 13.1 mIoU on the ApolloScape dataset. Furthermore, by training with the auto-labelled frames, we achieve competitive results on three semantic-segmentation benchmarks, improving the state-of-the-art by a large margin of 1.8 and 3.61 mIoU on NYU-V2 and KITTI, while matching the current best results on Cityscapes.
Hierarchical Lovász Embeddings for Proposal-free Panoptic Segmentation
Jun 08, 2021
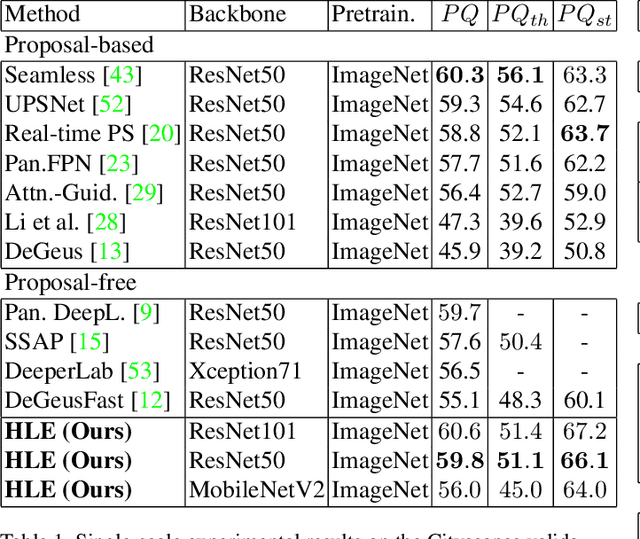
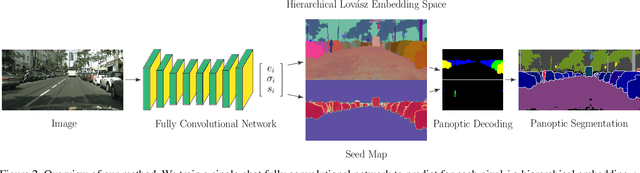

Panoptic segmentation brings together two separate tasks: instance and semantic segmentation. Although they are related, unifying them faces an apparent paradox: how to learn simultaneously instance-specific and category-specific (i.e. instance-agnostic) representations jointly. Hence, state-of-the-art panoptic segmentation methods use complex models with a distinct stream for each task. In contrast, we propose Hierarchical Lov\'asz Embeddings, per pixel feature vectors that simultaneously encode instance- and category-level discriminative information. We use a hierarchical Lov\'asz hinge loss to learn a low-dimensional embedding space structured into a unified semantic and instance hierarchy without requiring separate network branches or object proposals. Besides modeling instances precisely in a proposal-free manner, our Hierarchical Lov\'asz Embeddings generalize to categories by using a simple Nearest-Class-Mean classifier, including for non-instance "stuff" classes where instance segmentation methods are not applicable. Our simple model achieves state-of-the-art results compared to existing proposal-free panoptic segmentation methods on Cityscapes, COCO, and Mapillary Vistas. Furthermore, our model demonstrates temporal stability between video frames.
Team PFDet's Methods for Open Images Challenge 2019
Oct 25, 2019

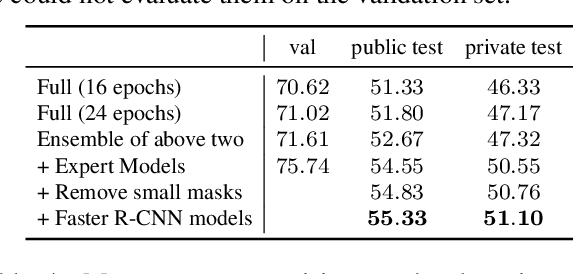

We present the instance segmentation and the object detection method used by team PFDet for Open Images Challenge 2019. We tackle a massive dataset size, huge class imbalance and federated annotations. Using this method, the team PFDet achieved 3rd and 4th place in the instance segmentation and the object detection track, respectively.
Sampling Techniques for Large-Scale Object Detection from Sparsely Annotated Objects
Nov 27, 2018

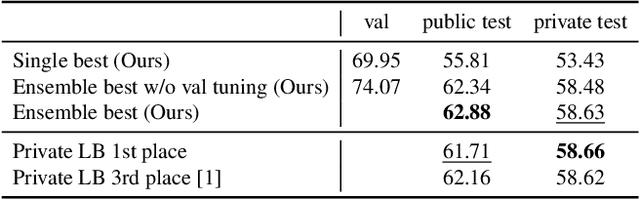
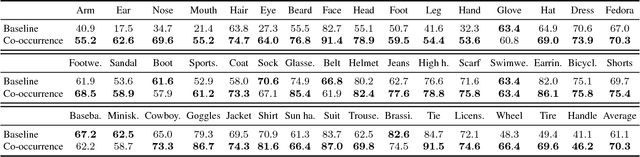
Efficient and reliable methods for training of object detectors are in higher demand than ever, and more and more data relevant to the field is becoming available. However, large datasets like Open Images Dataset v4 (OID) are sparsely annotated, and some measure must be taken in order to ensure the training of a reliable detector. In order to take the incompleteness of these datasets into account, one possibility is to use pretrained models to detect the presence of the unverified objects. However, the performance of such a strategy depends largely on the power of the pretrained model. In this study, we propose part-aware sampling, a method that uses human intuition for the hierarchical relation between objects. In terse terms, our method works by making assumptions like "a bounding box for a car should contain a bounding box for a tire". We demonstrate the power of our method on OID and compare the performance against a method based on a pretrained model. Our method also won the first and second place on the public and private test sets of the Google AI Open Images Competition 2018.
PFDet: 2nd Place Solution to Open Images Challenge 2018 Object Detection Track
Sep 04, 2018
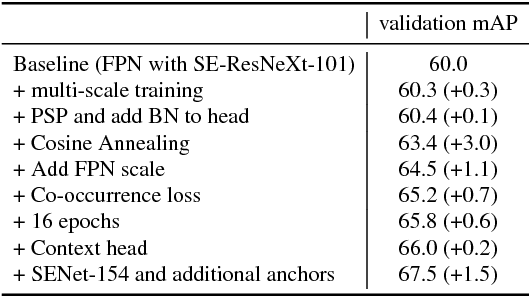
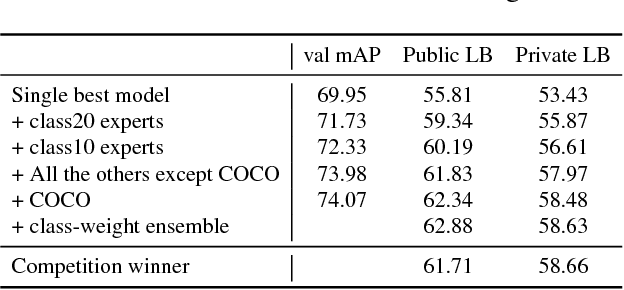
We present a large-scale object detection system by team PFDet. Our system enables training with huge datasets using 512 GPUs, handles sparsely verified classes, and massive class imbalance. Using our method, we achieved 2nd place in the Google AI Open Images Object Detection Track 2018 on Kaggle.
Minimizing Supervision for Free-space Segmentation
Apr 18, 2018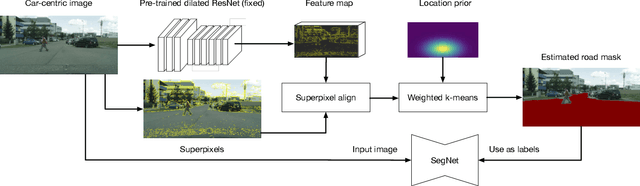

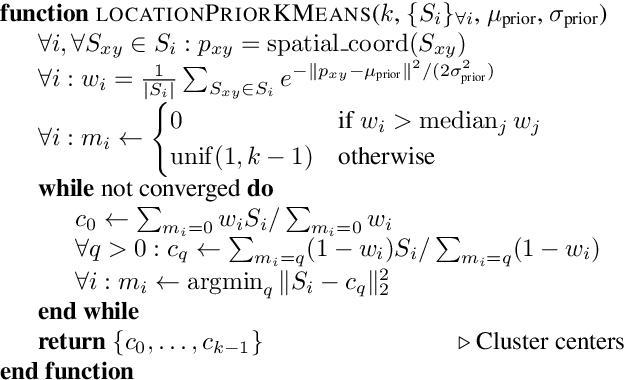

Identifying "free-space," or safely driveable regions in the scene ahead, is a fundamental task for autonomous navigation. While this task can be addressed using semantic segmentation, the manual labor involved in creating pixelwise annotations to train the segmentation model is very costly. Although weakly supervised segmentation addresses this issue, most methods are not designed for free-space. In this paper, we observe that homogeneous texture and location are two key characteristics of free-space, and develop a novel, practical framework for free-space segmentation with minimal human supervision. Our experiments show that our framework performs better than other weakly supervised methods while using less supervision. Our work demonstrates the potential for performing free-space segmentation without tedious and costly manual annotation, which will be important for adapting autonomous driving systems to different types of vehicles and environments
Distantly Supervised Road Segmentation
Aug 21, 2017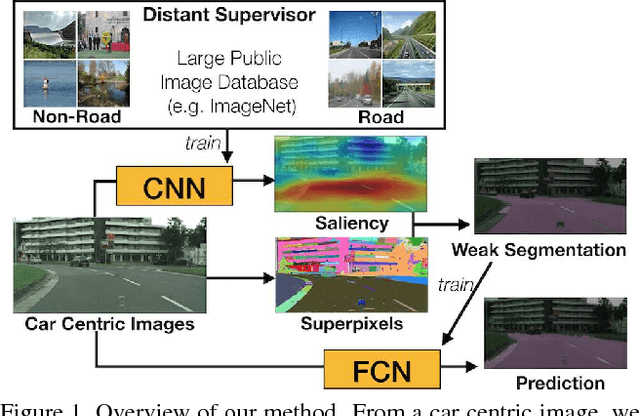

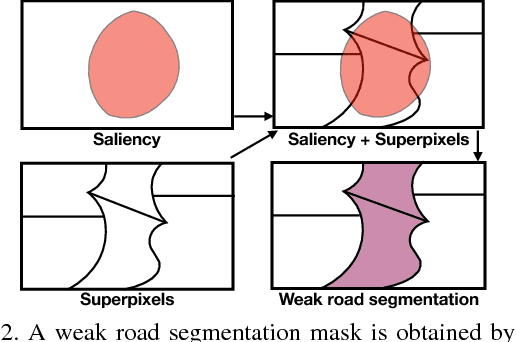
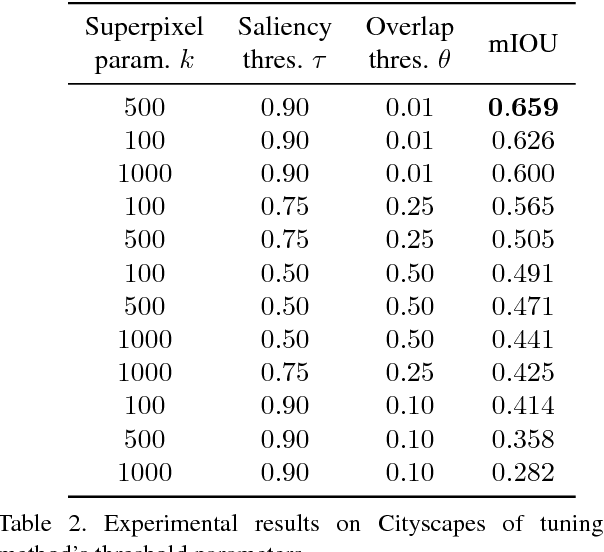
We present an approach for road segmentation that only requires image-level annotations at training time. We leverage distant supervision, which allows us to train our model using images that are different from the target domain. Using large publicly available image databases as distant supervisors, we develop a simple method to automatically generate weak pixel-wise road masks. These are used to iteratively train a fully convolutional neural network, which produces our final segmentation model. We evaluate our method on the Cityscapes dataset, where we compare it with a fully supervised approach. Further, we discuss the trade-off between annotation cost and performance. Overall, our distantly supervised approach achieves 93.8% of the performance of the fully supervised approach, while using orders of magnitude less annotation work.
Pano2CAD: Room Layout From A Single Panorama Image
Sep 30, 2016

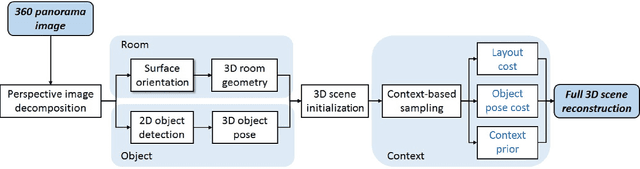

This paper presents a method of estimating the geometry of a room and the 3D pose of objects from a single 360-degree panorama image. Assuming Manhattan World geometry, we formulate the task as a Bayesian inference problem in which we estimate positions and orientations of walls and objects. The method combines surface normal estimation, 2D object detection and 3D object pose estimation. Quantitative results are presented on a dataset of synthetically generated 3D rooms containing objects, as well as on a subset of hand-labeled images from the public SUN360 dataset.