 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Supervision for Free-space Segmentation
Paper and Code
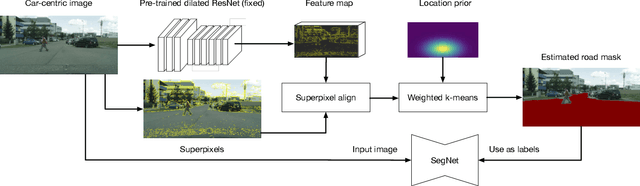

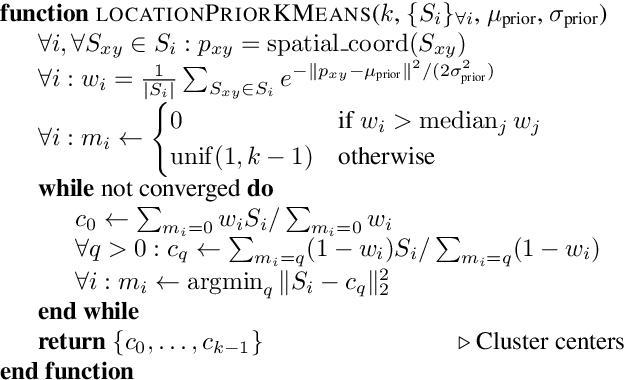

Identifying "free-space," or safely driveable regions in the scene ahead, is a fundamental task for autonomous navigation. While this task can be addressed using semantic segmentation, the manual labor involved in creating pixelwise annotations to train the segmentation model is very costly. Although weakly supervised segmentation addresses this issue, most methods are not designed for free-space. In this paper, we observe that homogeneous texture and location are two key characteristics of free-space, and develop a novel, practical framework for free-space segmentation with minimal human supervision. Our experiments show that our framework performs better than other weakly supervised methods while using less supervision. Our work demonstrates the potential for performing free-space segmentation without tedious and costly manual annotation, which will be important for adapting autonomous driving systems to different types of vehicles and environments