 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLaMo 2 Technical Report
Sep 05, 2025In this report, we introduce PLaMo 2, a series of Japanese-focused large language models featuring a hybrid Samba-based architecture that transitions to full attention via continual pre-training to support 32K token contexts. Training leverages extensive synthetic corpora to overcome data scarcity, while computational efficiency is achieved through weight reuse and structured pruning. This efficient pruning methodology produces an 8B model that achieves performance comparable to our previous 100B model. Post-training further refines the models using a pipeline of supervised fine-tuning (SFT) and direct preference optimization (DPO), enhanced by synthetic Japanese instruction data and model merging techniques. Optimized for inference using vLLM and quantization with minimal accuracy loss, the PLaMo 2 models achieve state-of-the-art results on Japanese benchmarks, outperforming similarly-sized open models in instruction-following, language fluency, and Japanese-specific knowledge.
A Judge-free LLM Open-ended Generation Benchmark Based on the Distributional Hypothesis
Feb 13, 2025Evaluating the open-ended text generation of large language models (LLMs) is challenging because of the lack of a clear ground truth and the high cost of human or LLM-based assessments. We propose a novel benchmark that evaluates LLMs using n-gram statistics and rules, without relying on human judgement or LLM-as-a-judge approaches. Using 50 question and reference answer sets, we introduce three new metrics based on n-grams and rules: Fluency, Truthfulness, and Helpfulness. Our benchmark strongly correlates with GPT-4o-based evaluations while requiring significantly fewer computational resources, demonstrating its effectiveness as a scalable alternative for assessing LLMs' open-ended generation capabilities.
PLaMo-100B: A Ground-Up Language Model Designed for Japanese Proficiency
Oct 10, 2024



We introduce PLaMo-100B, a large-scale language model designed for Japanese proficiency. The model was trained from scratch using 2 trillion tokens, with architecture such as QK Normalization and Z-Loss to ensure training stability during the training process. Post-training techniques, including Supervised Fine-Tuning and Direct Preference Optimization, were applied to refine the model's performance. Benchmark evaluations suggest that PLaMo-100B performs well, particularly in Japanese-specific tasks, achieving results that are competitive with frontier models like GPT-4.
A Scaling Law for Synthetic-to-Real Transfer: A Measure of Pre-Training
Aug 25, 2021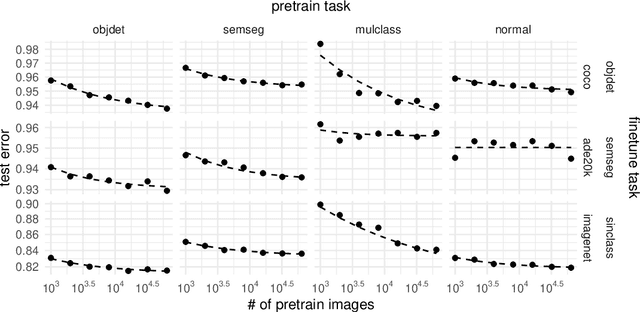

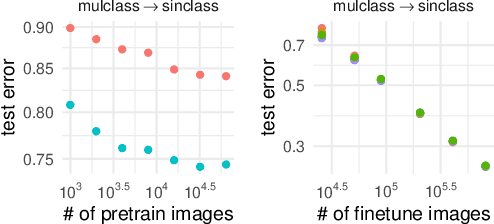
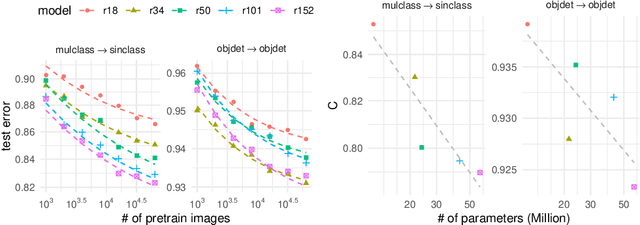
Synthetic-to-real transfer learning is a framework in which we pre-train models with synthetically generated images and ground-truth annotations for real tasks. Although synthetic images overcome the data scarcity issue, it remains unclear how the fine-tuning performance scales with pre-trained models, especially in terms of pre-training data size. In this study, we collect a number of empirical observations and uncover the secret. Through experiments, we observe a simple and general scaling law that consistently describes learning curves in various tasks, models, and complexities of synthesized pre-training data. Further, we develop a theory of transfer learning for a simplified scenario and confirm that the derived generalization bound is consistent with our empirical findings.
An Inductive Transfer Learning Approach using Cycle-consistent Adversarial Domain Adaptation with Application to Brain Tumor Segmentation
May 11, 2020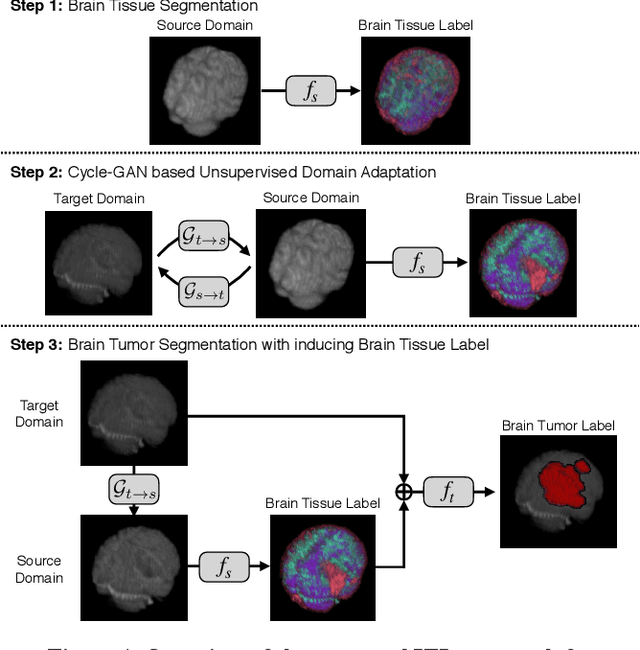
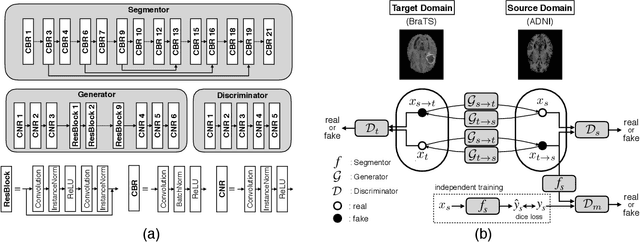
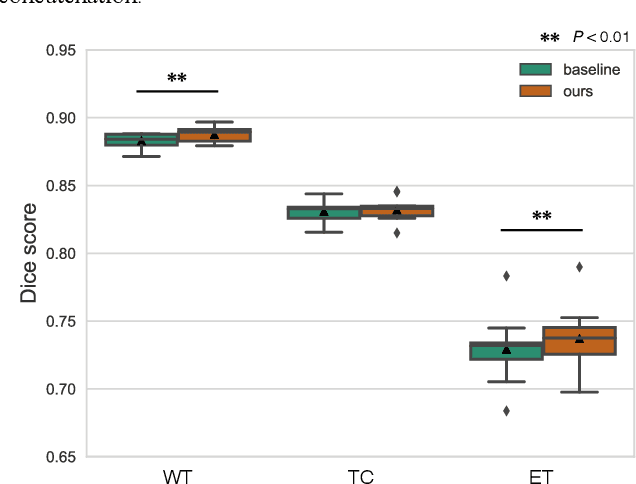
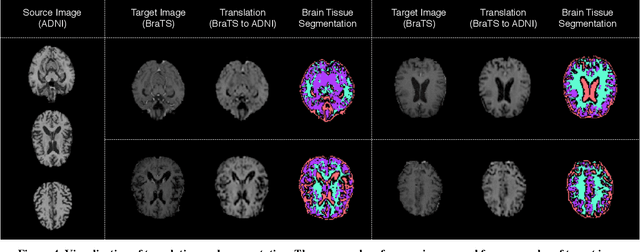
With recent advances in supervised machine learning for medical image analysis applications, the annotated medical image datasets of various domains are being shared extensively. Given that the annotation labelling requires medical expertise, such labels should be applied to as many learning tasks as possible. However, the multi-modal nature of each annotated image renders it difficult to share the annotation label among diverse tasks. In this work, we provide an inductive transfer learning (ITL) approach to adopt the annotation label of the source domain datasets to tasks of the target domain datasets using Cycle-GAN based unsupervised domain adaptation (UDA). To evaluate the applicability of the ITL approach, we adopted the brain tissue annotation label on the source domain dataset of Magnetic Resonance Imaging (MRI) images to the task of brain tumor segmentation on the target domain dataset of MRI. The results confirm that the segmentation accuracy of brain tumor segmentation improved significantly. The proposed ITL approach can make significant contribution to the field of medical image analysis, as we develop a fundamental tool to improve and promote various tasks using medical images.
Team PFDet's Methods for Open Images Challenge 2019
Oct 25, 2019

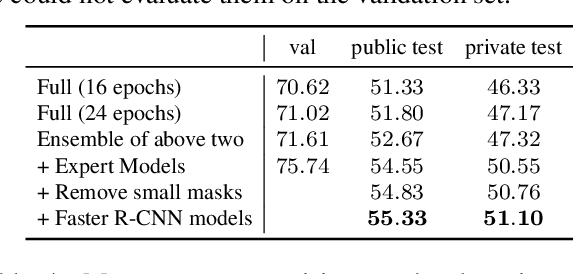

We present the instance segmentation and the object detection method used by team PFDet for Open Images Challenge 2019. We tackle a massive dataset size, huge class imbalance and federated annotations. Using this method, the team PFDet achieved 3rd and 4th place in the instance segmentation and the object detection track, respectively.
Chainer: A Deep Learning Framework for Accelerating the Research Cycle
Aug 01, 2019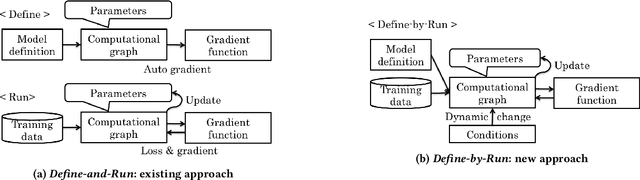


Software frameworks for neural networks play a key role in the development and application of deep learning methods. In this paper, we introduce the Chainer framework, which intends to provide a flexible, intuitive, and high performance means of implementing the full range of deep learning models needed by researchers and practitioners. Chainer provides acceleration using Graphics Processing Units with a familiar NumPy-like API through CuPy, supports general and dynamic models in Python through Define-by-Run, and also provides add-on packages for state-of-the-art computer vision models as well as distributed training.
Sampling Techniques for Large-Scale Object Detection from Sparsely Annotated Objects
Nov 27, 2018

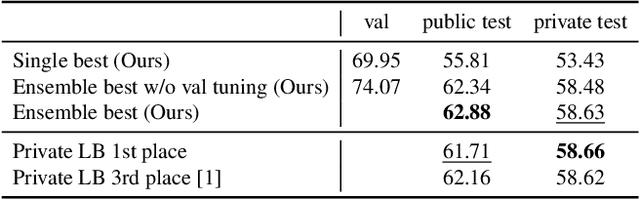
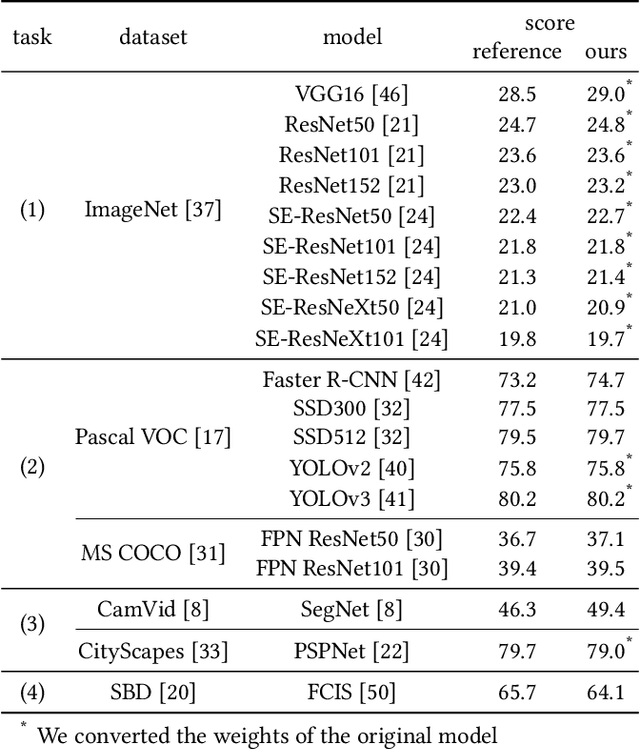
Efficient and reliable methods for training of object detectors are in higher demand than ever, and more and more data relevant to the field is becoming available. However, large datasets like Open Images Dataset v4 (OID) are sparsely annotated, and some measure must be taken in order to ensure the training of a reliable detector. In order to take the incompleteness of these datasets into account, one possibility is to use pretrained models to detect the presence of the unverified objects. However, the performance of such a strategy depends largely on the power of the pretrained model. In this study, we propose part-aware sampling, a method that uses human intuition for the hierarchical relation between objects. In terse terms, our method works by making assumptions like "a bounding box for a car should contain a bounding box for a tire". We demonstrate the power of our method on OID and compare the performance against a method based on a pretrained model. Our method also won the first and second place on the public and private test sets of the Google AI Open Images Competition 2018.
PFDet: 2nd Place Solution to Open Images Challenge 2018 Object Detection Track
Sep 04, 2018
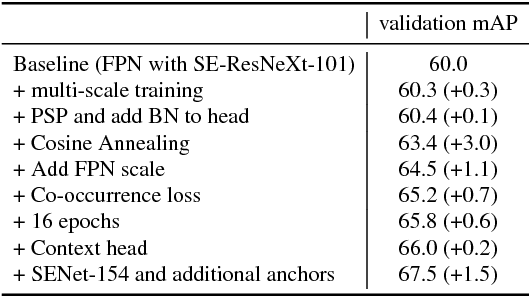
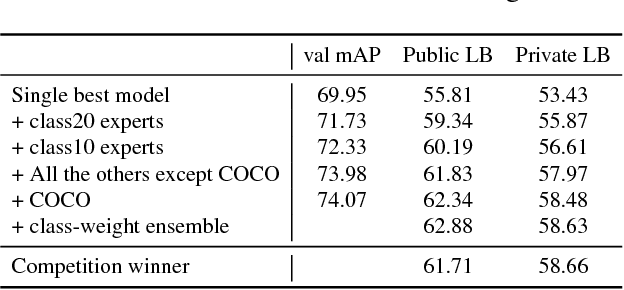
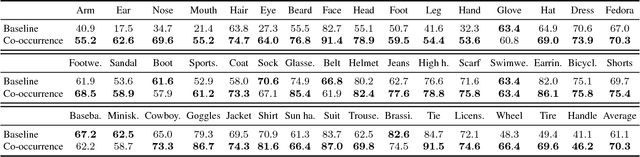
We present a large-scale object detection system by team PFDet. Our system enables training with huge datasets using 512 GPUs, handles sparsely verified classes, and massive class imbalance. Using our method, we achieved 2nd place in the Google AI Open Images Object Detection Track 2018 on Kaggle.
Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes
Nov 12, 2017
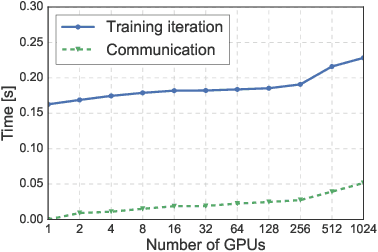
We demonstrate that training ResNet-50 on ImageNet for 90 epochs can be achieved in 15 minutes with 1024 Tesla P100 GPUs. This was made possible by using a large minibatch size of 32k. To maintain accuracy with this large minibatch size, we employed several techniques such as RMSprop warm-up, batch normalization without moving averages, and a slow-start learning rate schedule. This paper also describes the details of the hardware and software of the system used to achieve the above performance.