 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Bayesian Filter for Bayes-faithful Data Assimilation
May 29, 2024



State estimation for nonlinear state space models is a challenging task. Existing assimilation methodologies predominantly assume Gaussian posteriors on physical space, where true posteriors become inevitably non-Gaussian. We propose Deep Bayesian Filtering (DBF) for data assimilation on nonlinear state space models (SSMs). DBF constructs new latent variables $h_t$ on a new latent (``fancy'') space and assimilates observations $o_t$. By (i) constraining the state transition on fancy space to be linear and (ii) learning a Gaussian inverse observation operator $q(h_t|o_t)$, posteriors always remain Gaussian for DBF. Quite distinctively, the structured design of posteriors provides an analytic formula for the recursive computation of posteriors without accumulating Monte-Carlo sampling errors over time steps. DBF seeks the Gaussian inverse observation operators $q(h_t|o_t)$ and other latent SSM parameters (e.g., dynamics matrix) by maximizing the evidence lower bound. Experiments show that DBF outperforms model-based approaches and latent assimilation methods in various tasks and conditions.
Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes
Nov 12, 2017
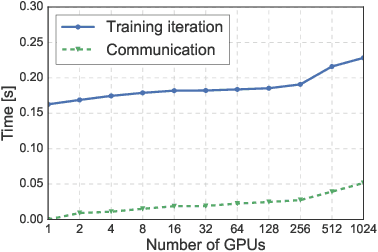
We demonstrate that training ResNet-50 on ImageNet for 90 epochs can be achieved in 15 minutes with 1024 Tesla P100 GPUs. This was made possible by using a large minibatch size of 32k. To maintain accuracy with this large minibatch size, we employed several techniques such as RMSprop warm-up, batch normalization without moving averages, and a slow-start learning rate schedule. This paper also describes the details of the hardware and software of the system used to achieve the above performance.
ChainerMN: Scalable Distributed Deep Learning Framework
Oct 31, 2017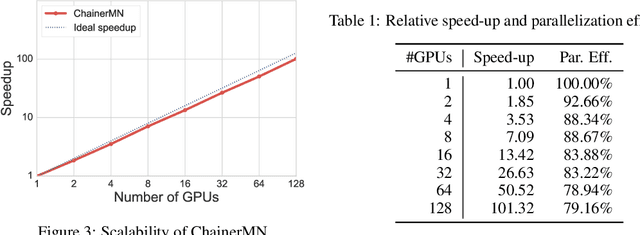

One of the keys for deep learning to have made a breakthrough in various fields was to utilize high computing powers centering around GPUs. Enabling the use of further computing abilities by distributed processing is essential not only to make the deep learning bigger and faster but also to tackle unsolved challenges. We present the design, implementation, and evaluation of ChainerMN, the distributed deep learning framework we have developed. We demonstrate that ChainerMN can scale the learning process of the ResNet-50 model to the ImageNet dataset up to 128 GPUs with the parallel efficiency of 90%.