Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChainerMN: Scalable Distributed Deep Learning Framework
Paper and Code
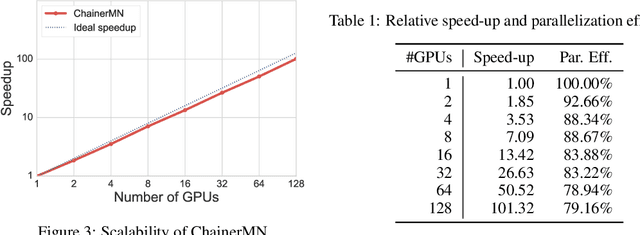

One of the keys for deep learning to have made a breakthrough in various fields was to utilize high computing powers centering around GPUs. Enabling the use of further computing abilities by distributed processing is essential not only to make the deep learning bigger and faster but also to tackle unsolved challenges. We present the design, implementation, and evaluation of ChainerMN, the distributed deep learning framework we have developed. We demonstrate that ChainerMN can scale the learning process of the ResNet-50 model to the ImageNet dataset up to 128 GPUs with the parallel efficiency of 90%.
View paper on