 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLaMo-100B: A Ground-Up Language Model Designed for Japanese Proficiency
Oct 10, 2024



We introduce PLaMo-100B, a large-scale language model designed for Japanese proficiency. The model was trained from scratch using 2 trillion tokens, with architecture such as QK Normalization and Z-Loss to ensure training stability during the training process. Post-training techniques, including Supervised Fine-Tuning and Direct Preference Optimization, were applied to refine the model's performance. Benchmark evaluations suggest that PLaMo-100B performs well, particularly in Japanese-specific tasks, achieving results that are competitive with frontier models like GPT-4.
Tool Shape Optimization through Backpropagation of Neural Network
Jul 16, 2024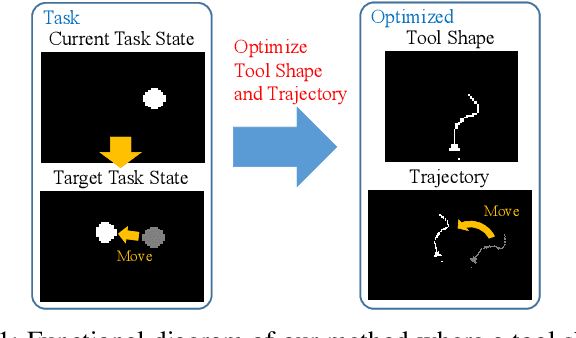
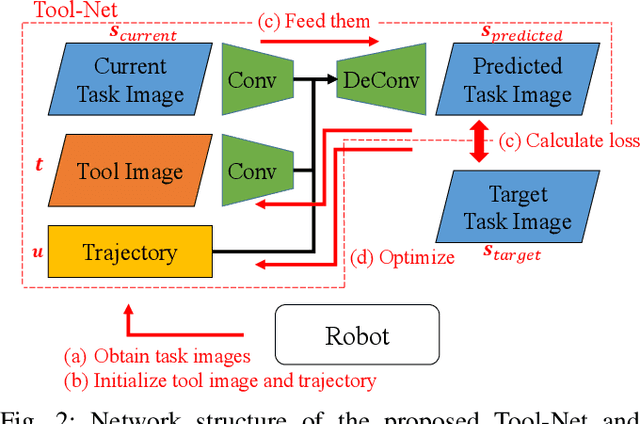
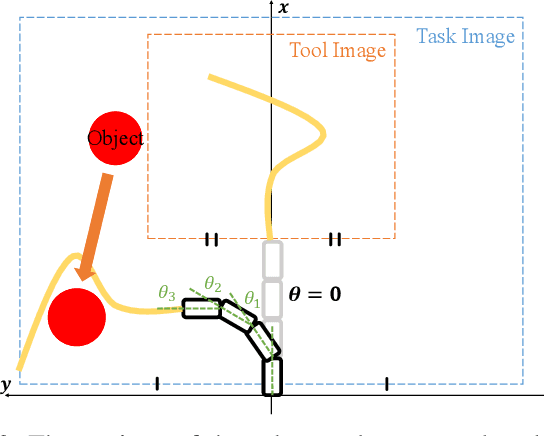

When executing a certain task, human beings can choose or make an appropriate tool to achieve the task. This research especially addresses the optimization of tool shape for robotic tool-use. We propose a method in which a robot obtains an optimized tool shape, tool trajectory, or both, depending on a given task. The feature of our method is that a transition of the task state when the robot moves a certain tool along a certain trajectory is represented by a deep neural network. We applied this method to object manipulation tasks on a 2D plane, and verified that appropriate tool shapes are generated by using this novel method.
Dynamic Task Control Method of a Flexible Manipulator Using a Deep Recurrent Neural Network
Jul 16, 2024



The flexible body has advantages over the rigid body in terms of environmental contact thanks to its underactuation. On the other hand, when applying conventional control methods to realize dynamic tasks with the flexible body, there are two difficulties: accurate modeling of the flexible body and the derivation of intermediate postures to achieve the tasks. Learning-based methods are considered to be more effective than accurate modeling, but they require explicit intermediate postures. To solve these two difficulties at the same time, we developed a real-time task control method with a deep recurrent neural network named Dynamic Task Execution Network (DTXNET), which acquires the relationship among the control command, robot state including image information, and task state. Once the network is trained, only the target event and its timing are needed to realize a given task. To demonstrate the effectiveness of our method, we applied it to the task of Wadaiko (traditional Japanese drum) drumming as an example, and verified the best configuration of DTXNET.
Building a Manga Dataset "Manga109" with Annotations for Multimedia Applications
May 12, 2020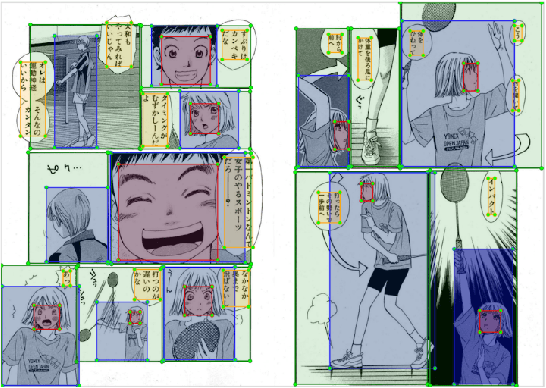
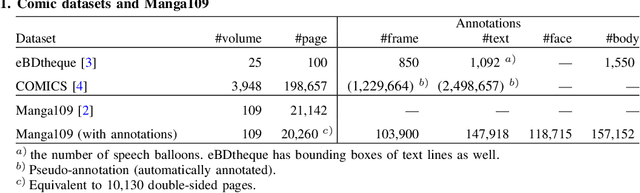
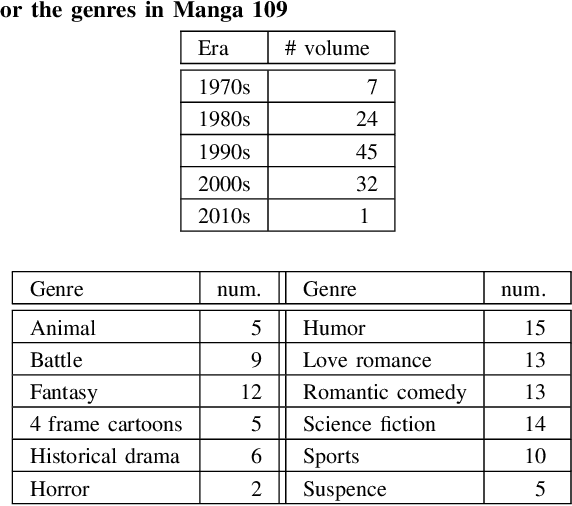
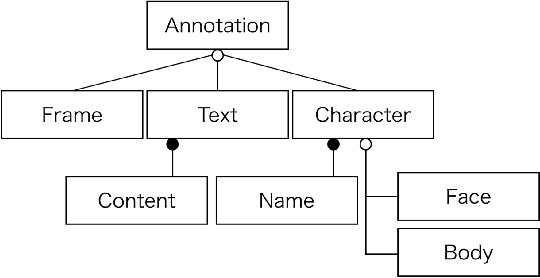
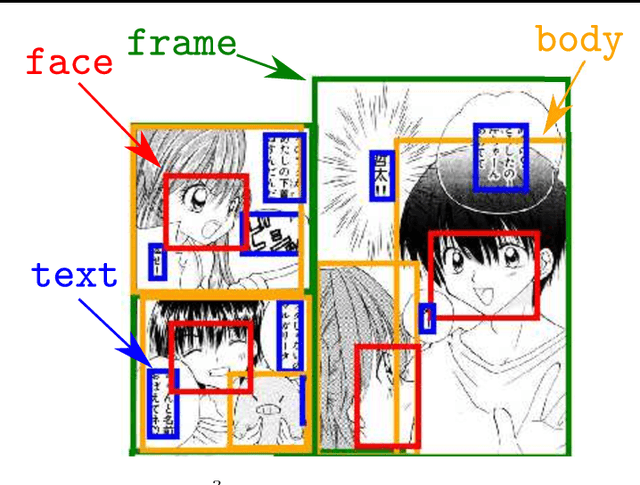
Manga, or comics, which are a type of multimodal artwork, have been left behind in the recent trend of deep learning applications because of the lack of a proper dataset. Hence, we built Manga109, a dataset consisting of a variety of 109 Japanese comic books (94 authors and 21,142 pages) and made it publicly available by obtaining author permissions for academic use. We carefully annotated the frames, speech texts, character faces, and character bodies; the total number of annotations exceeds 500k. This dataset provides numerous manga images and annotations, which will be beneficial for use in machine learning algorithms and their evaluation. In addition to academic use, we obtained further permission for a subset of the dataset for industrial use. In this article, we describe the details of the dataset and present a few examples of multimedia processing applications (detection, retrieval, and generation) that apply existing deep learning methods and are made possible by the dataset.
* 10 pages, 8 figures
Team PFDet's Methods for Open Images Challenge 2019
Oct 25, 2019

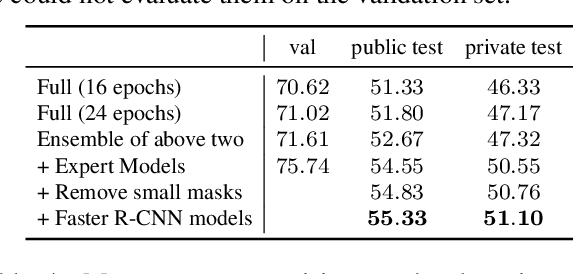

We present the instance segmentation and the object detection method used by team PFDet for Open Images Challenge 2019. We tackle a massive dataset size, huge class imbalance and federated annotations. Using this method, the team PFDet achieved 3rd and 4th place in the instance segmentation and the object detection track, respectively.
Chainer: A Deep Learning Framework for Accelerating the Research Cycle
Aug 01, 2019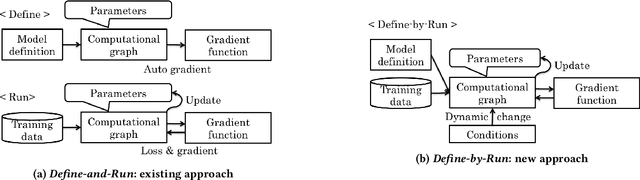
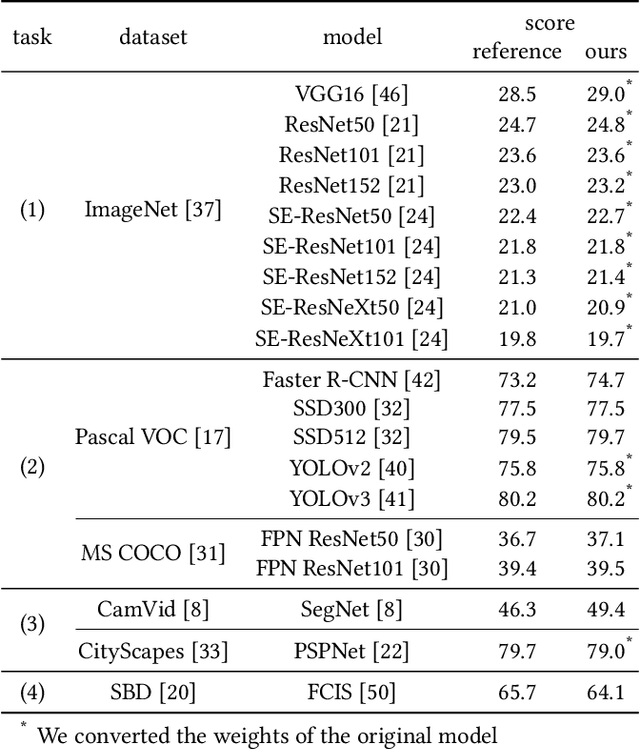


Software frameworks for neural networks play a key role in the development and application of deep learning methods. In this paper, we introduce the Chainer framework, which intends to provide a flexible, intuitive, and high performance means of implementing the full range of deep learning models needed by researchers and practitioners. Chainer provides acceleration using Graphics Processing Units with a familiar NumPy-like API through CuPy, supports general and dynamic models in Python through Define-by-Run, and also provides add-on packages for state-of-the-art computer vision models as well as distributed training.
Dynamic Manipulation of Flexible Objects with Torque Sequence Using a Deep Neural Network
Jan 29, 2019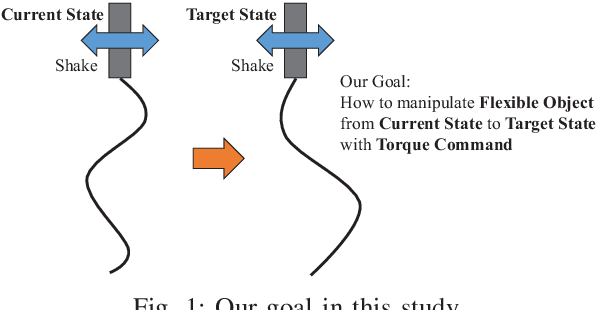
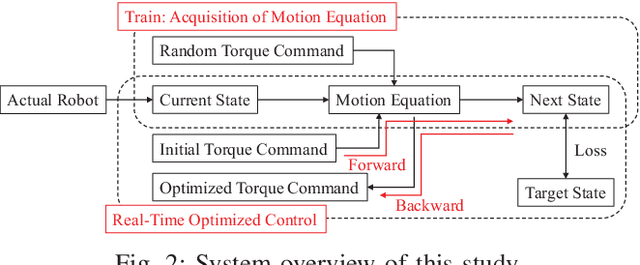
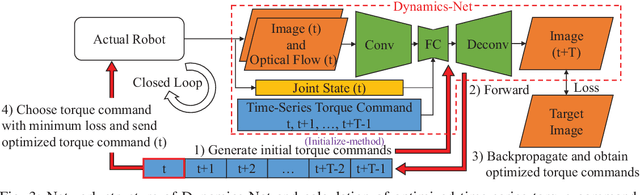

For dynamic manipulation of flexible objects, we propose an acquisition method of a flexible object motion equation model using a deep neural network and a control method to realize a target state by calculating an optimized time-series joint torque command. By using the proposed method, any physics model of a target object is not needed, and the object can be controlled as intended. We applied this method to manipulations of a rigid object, a flexible object with and without environmental contact, and a cloth, and verified its effectiveness.
Sampling Techniques for Large-Scale Object Detection from Sparsely Annotated Objects
Nov 27, 2018

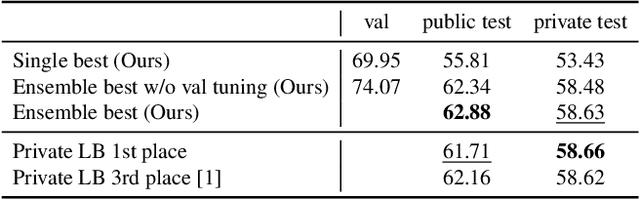
Efficient and reliable methods for training of object detectors are in higher demand than ever, and more and more data relevant to the field is becoming available. However, large datasets like Open Images Dataset v4 (OID) are sparsely annotated, and some measure must be taken in order to ensure the training of a reliable detector. In order to take the incompleteness of these datasets into account, one possibility is to use pretrained models to detect the presence of the unverified objects. However, the performance of such a strategy depends largely on the power of the pretrained model. In this study, we propose part-aware sampling, a method that uses human intuition for the hierarchical relation between objects. In terse terms, our method works by making assumptions like "a bounding box for a car should contain a bounding box for a tire". We demonstrate the power of our method on OID and compare the performance against a method based on a pretrained model. Our method also won the first and second place on the public and private test sets of the Google AI Open Images Competition 2018.
PFDet: 2nd Place Solution to Open Images Challenge 2018 Object Detection Track
Sep 04, 2018
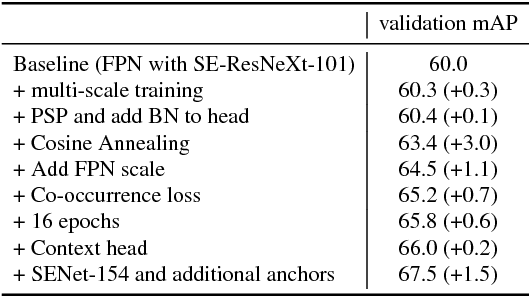
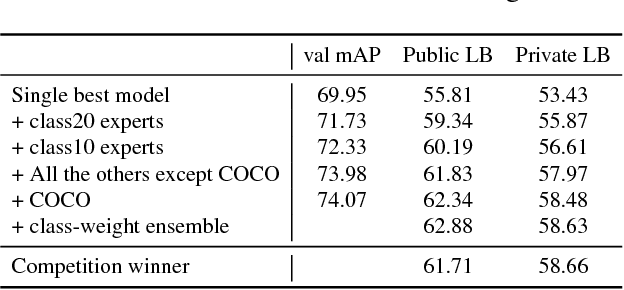
We present a large-scale object detection system by team PFDet. Our system enables training with huge datasets using 512 GPUs, handles sparsely verified classes, and massive class imbalance. Using our method, we achieved 2nd place in the Google AI Open Images Object Detection Track 2018 on Kaggle.
Object Detection for Comics using Manga109 Annotations
Mar 26, 2018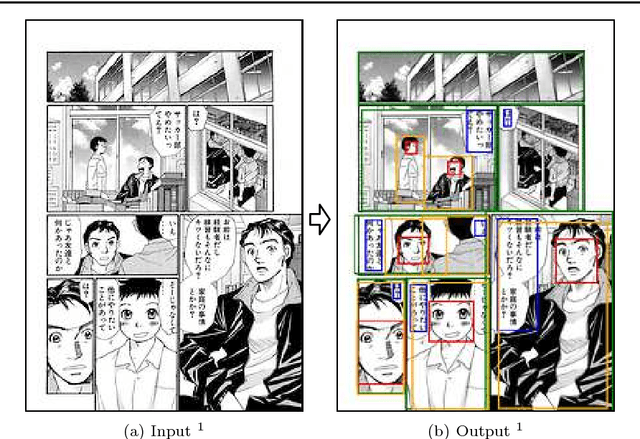
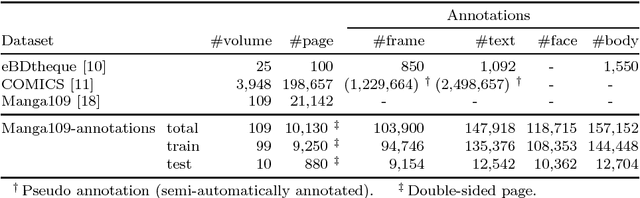

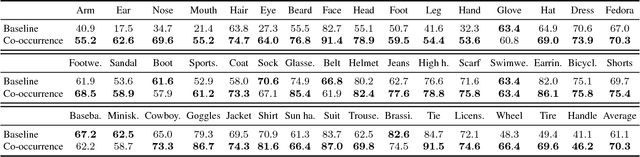
With the growth of digitized comics, image understanding techniques are becoming important. In this paper, we focus on object detection, which is a fundamental task of image understanding. Although convolutional neural networks (CNN)-based methods archived good performance in object detection for naturalistic images, there are two problems in applying these methods to the comic object detection task. First, there is no large-scale annotated comics dataset. The CNN-based methods require large-scale annotations for training. Secondly, the objects in comics are highly overlapped compared to naturalistic images. This overlap causes the assignment problem in the existing CNN-based methods. To solve these problems, we proposed a new annotation dataset and a new CNN model. We annotated an existing image dataset of comics and created the largest annotation dataset, named Manga109-annotations. For the assignment problem, we proposed a new CNN-based detector, SSD300-fork. We compared SSD300-fork with other detection methods using Manga109-annotations and confirmed that our model outperformed them based on the mAP score.