 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Judge-free LLM Open-ended Generation Benchmark Based on the Distributional Hypothesis
Feb 13, 2025


Evaluating the open-ended text generation of large language models (LLMs) is challenging because of the lack of a clear ground truth and the high cost of human or LLM-based assessments. We propose a novel benchmark that evaluates LLMs using n-gram statistics and rules, without relying on human judgement or LLM-as-a-judge approaches. Using 50 question and reference answer sets, we introduce three new metrics based on n-grams and rules: Fluency, Truthfulness, and Helpfulness. Our benchmark strongly correlates with GPT-4o-based evaluations while requiring significantly fewer computational resources, demonstrating its effectiveness as a scalable alternative for assessing LLMs' open-ended generation capabilities.
Financial Fine-tuning a Large Time Series Model
Dec 13, 2024



Large models have shown unprecedented capabilities in natural language processing, image generation, and most recently, time series forecasting. This leads us to ask the question: treating market prices as a time series, can large models be used to predict the market? In this paper, we answer this by evaluating the performance of the latest time series foundation model TimesFM on price prediction. We find that due to the irregular nature of price data, directly applying TimesFM gives unsatisfactory results and propose to fine-tune TimeFM on financial data for the task of price prediction. This is done by continual pre-training of the latest time series foundation model TimesFM on price data containing 100 million time points, spanning a range of financial instruments spanning hourly and daily granularities. The fine-tuned model demonstrates higher price prediction accuracy than the baseline model. We conduct mock trading for our model in various financial markets and show that it outperforms various benchmarks in terms of returns, sharpe ratio, max drawdown and trading cost.
Enhancing Financial Domain Adaptation of Language Models via Model Augmentation
Nov 14, 2024


The domain adaptation of language models, including large language models (LLMs), has become increasingly important as the use of such models continues to expand. This study demonstrates the effectiveness of Composition to Augment Language Models (CALM) in adapting to the financial domain. CALM is a model to extend the capabilities of existing models by introducing cross-attention between two LLMs with different functions. In our experiments, we developed a CALM to enhance the financial performance of an LLM with strong response capabilities by leveraging a financial-specialized LLM. Notably, the CALM was trained using a financial dataset different from the one used to train the financial-specialized LLM, confirming CALM's ability to adapt to various datasets. The models were evaluated through quantitative Japanese financial benchmarks and qualitative response comparisons, demonstrating that CALM enables superior responses with higher scores than the original models and baselines. Additionally, comparative experiments on connection points revealed that connecting the middle layers of the models is most effective in facilitating adaptation to the financial domain. These findings confirm that CALM is a practical approach for adapting LLMs to the financial domain.
PLaMo-100B: A Ground-Up Language Model Designed for Japanese Proficiency
Oct 10, 2024



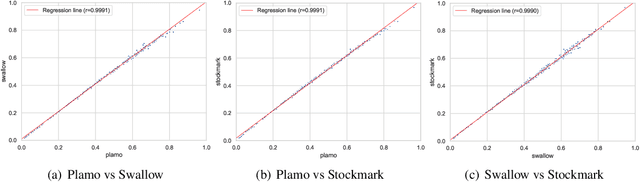
We introduce PLaMo-100B, a large-scale language model designed for Japanese proficiency. The model was trained from scratch using 2 trillion tokens, with architecture such as QK Normalization and Z-Loss to ensure training stability during the training process. Post-training techniques, including Supervised Fine-Tuning and Direct Preference Optimization, were applied to refine the model's performance. Benchmark evaluations suggest that PLaMo-100B performs well, particularly in Japanese-specific tasks, achieving results that are competitive with frontier models like GPT-4.
The Construction of Instruction-tuned LLMs for Finance without Instruction Data Using Continual Pretraining and Model Merging
Sep 30, 2024



This paper proposes a novel method for constructing instruction-tuned large language models (LLMs) for finance without instruction data. Traditionally, developing such domain-specific LLMs has been resource-intensive, requiring a large dataset and significant computational power for continual pretraining and instruction tuning. Our study proposes a simpler approach that combines domain-specific continual pretraining with model merging. Given that general-purpose pretrained LLMs and their instruction-tuned LLMs are often publicly available, they can be leveraged to obtain the necessary instruction task vector. By merging this with a domain-specific pretrained vector, we can effectively create instruction-tuned LLMs for finance without additional instruction data. Our process involves two steps: first, we perform continual pretraining on financial data; second, we merge the instruction-tuned vector with the domain-specific pretrained vector. Our experiments demonstrate the successful construction of instruction-tuned LLMs for finance. One major advantage of our method is that the instruction-tuned and domain-specific pretrained vectors are nearly independent. This independence makes our approach highly effective. The Japanese financial instruction-tuned LLMs we developed in this study are available at https://huggingface.co/pfnet/nekomata-14b-pfn-qfin-inst-merge.
Construction of Domain-specified Japanese Large Language Model for Finance through Continual Pre-training
Apr 16, 2024

Large language models (LLMs) are now widely used in various fields, including finance. However, Japanese financial-specific LLMs have not been proposed yet. Hence, this study aims to construct a Japanese financial-specific LLM through continual pre-training. Before tuning, we constructed Japanese financial-focused datasets for continual pre-training. As a base model, we employed a Japanese LLM that achieved state-of-the-art performance on Japanese financial benchmarks among the 10-billion-class parameter models. After continual pre-training using the datasets and the base model, the tuned model performed better than the original model on the Japanese financial benchmarks. Moreover, the outputs comparison results reveal that the tuned model's outputs tend to be better than the original model's outputs in terms of the quality and length of the answers. These findings indicate that domain-specific continual pre-training is also effective for LLMs. The tuned model is publicly available on Hugging Face.
Adversarial Deep Hedging: Learning to Hedge without Price Process Modeling
Jul 25, 2023



Deep hedging is a deep-learning-based framework for derivative hedging in incomplete markets. The advantage of deep hedging lies in its ability to handle various realistic market conditions, such as market frictions, which are challenging to address within the traditional mathematical finance framework. Since deep hedging relies on market simulation, the underlying asset price process model is crucial. However, existing literature on deep hedging often relies on traditional mathematical finance models, e.g., Brownian motion and stochastic volatility models, and discovering effective underlying asset models for deep hedging learning has been a challenge. In this study, we propose a new framework called adversarial deep hedging, inspired by adversarial learning. In this framework, a hedger and a generator, which respectively model the underlying asset process and the underlying asset process, are trained in an adversarial manner. The proposed method enables to learn a robust hedger without explicitly modeling the underlying asset process. Through numerical experiments, we demonstrate that our proposed method achieves competitive performance to models that assume explicit underlying asset processes across various real market data.
Uncertainty Aware Trader-Company Method: Interpretable Stock Price Prediction Capturing Uncertainty
Nov 02, 2022



Machine learning is an increasingly popular tool with some success in predicting stock prices. One promising method is the Trader-Company~(TC) method, which takes into account the dynamism of the stock market and has both high predictive power and interpretability. Machine learning-based stock prediction methods including the TC method have been concentrating on point prediction. However, point prediction in the absence of uncertainty estimates lacks credibility quantification and raises concerns about safety. The challenge in this paper is to make an investment strategy that combines high predictive power and the ability to quantify uncertainty. We propose a novel approach called Uncertainty Aware Trader-Company Method~(UTC) method. The core idea of this approach is to combine the strengths of both frameworks by merging the TC method with the probabilistic modeling, which provides probabilistic predictions and uncertainty estimations. We expect this to retain the predictive power and interpretability of the TC method while capturing the uncertainty. We theoretically prove that the proposed method estimates the posterior variance and does not introduce additional biases from the original TC method. We conduct a comprehensive evaluation of our approach based on the synthetic and real market datasets. We confirm with synthetic data that the UTC method can detect situations where the uncertainty increases and the prediction is difficult. We also confirmed that the UTC method can detect abrupt changes in data generating distributions. We demonstrate with real market data that the UTC method can achieve higher returns and lower risks than baselines.
What Data Augmentation Do We Need for Deep-Learning-Based Finance?
Jun 08, 2021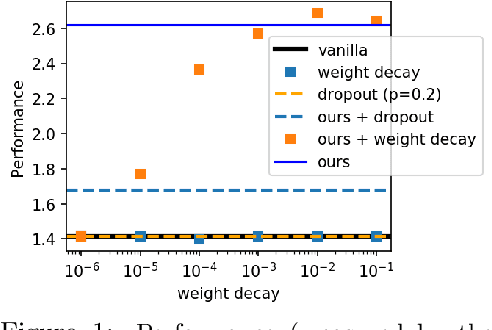


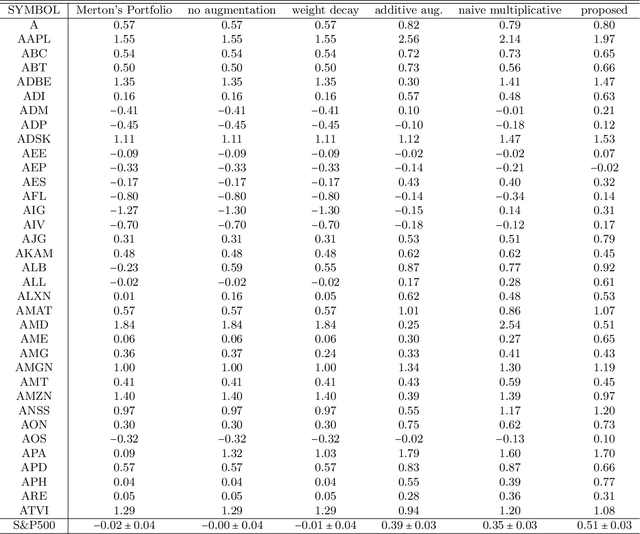
The main task we consider is portfolio construction in a speculative market, a fundamental problem in modern finance. While various empirical works now exist to explore deep learning in finance, the theory side is almost non-existent. In this work, we focus on developing a theoretical framework for understanding the use of data augmentation for deep-learning-based approaches to quantitative finance. The proposed theory clarifies the role and necessity of data augmentation for finance; moreover, our theory motivates a simple algorithm of injecting a random noise of strength $\sqrt{|r_{t-1}|}$ to the observed return $r_{t}$. This algorithm is shown to work well in practice.
Trader-Company Method: A Metaheuristic for Interpretable Stock Price Prediction
Dec 18, 2020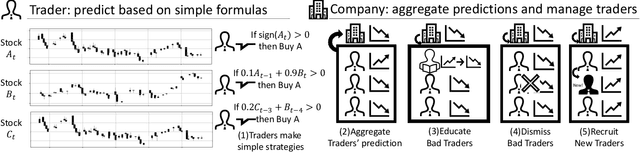


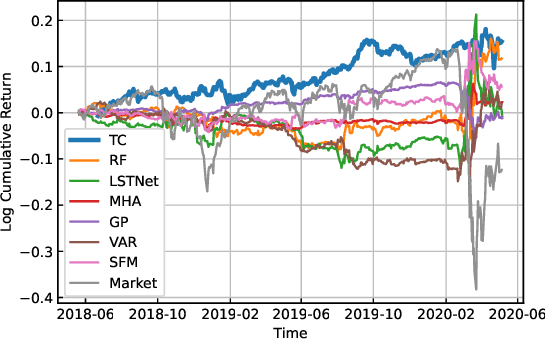
Investors try to predict returns of financial assets to make successful investment. Many quantitative analysts have used machine learning-based methods to find unknown profitable market rules from large amounts of market data. However, there are several challenges in financial markets hindering practical applications of machine learning-based models. First, in financial markets, there is no single model that can consistently make accurate prediction because traders in markets quickly adapt to newly available information. Instead, there are a number of ephemeral and partially correct models called "alpha factors". Second, since financial markets are highly uncertain, ensuring interpretability of prediction models is quite important to make reliable trading strategies. To overcome these challenges, we propose the Trader-Company method, a novel evolutionary model that mimics the roles of a financial institute and traders belonging to it. Our method predicts future stock returns by aggregating suggestions from multiple weak learners called Traders. A Trader holds a collection of simple mathematical formulae, each of which represents a candidate of an alpha factor and would be interpretable for real-world investors. The aggregation algorithm, called a Company, maintains multiple Traders. By randomly generating new Traders and retraining them, Companies can efficiently find financially meaningful formulae whilst avoiding overfitting to a transient state of the market. We show the effectiveness of our method by conducting experiments on real market data.