 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKANHedge: Efficient Hedging of High-Dimensional Options Using Kolmogorov-Arnold Network-Based BSDE Solver
Jan 16, 2026High-dimensional option pricing and hedging present significant challenges in quantitative finance, where traditional PDE-based methods struggle with the curse of dimensionality. The BSDE framework offers a computationally efficient alternative to PDE-based methods, and recently proposed deep BSDE solvers, generally utilizing conventional Multi-Layer Perceptrons (MLPs), build upon this framework to provide a scalable alternative to numerical BSDE solvers. In this research, we show that although such MLP-based deep BSDEs demonstrate promising results in option pricing, there remains room for improvement regarding hedging performance. To address this issue, we introduce KANHedge, a novel BSDE-based hedger that leverages Kolmogorov-Arnold Networks (KANs) within the BSDE framework. Unlike conventional MLP approaches that use fixed activation functions, KANs employ learnable B-spline activation functions that provide enhanced function approximation capabilities for continuous derivatives. We comprehensively evaluate KANHedge on both European and American basket options across multiple dimensions and market conditions. Our experimental results demonstrate that while KANHedge and MLP achieve comparable pricing accuracy, KANHedge provides improved hedging performance. Specifically, KANHedge achieves considerable reductions in hedging cost metrics, demonstrating enhanced risk control capabilities.
A Judge-free LLM Open-ended Generation Benchmark Based on the Distributional Hypothesis
Feb 13, 2025


Evaluating the open-ended text generation of large language models (LLMs) is challenging because of the lack of a clear ground truth and the high cost of human or LLM-based assessments. We propose a novel benchmark that evaluates LLMs using n-gram statistics and rules, without relying on human judgement or LLM-as-a-judge approaches. Using 50 question and reference answer sets, we introduce three new metrics based on n-grams and rules: Fluency, Truthfulness, and Helpfulness. Our benchmark strongly correlates with GPT-4o-based evaluations while requiring significantly fewer computational resources, demonstrating its effectiveness as a scalable alternative for assessing LLMs' open-ended generation capabilities.
Financial Fine-tuning a Large Time Series Model
Dec 13, 2024



Large models have shown unprecedented capabilities in natural language processing, image generation, and most recently, time series forecasting. This leads us to ask the question: treating market prices as a time series, can large models be used to predict the market? In this paper, we answer this by evaluating the performance of the latest time series foundation model TimesFM on price prediction. We find that due to the irregular nature of price data, directly applying TimesFM gives unsatisfactory results and propose to fine-tune TimeFM on financial data for the task of price prediction. This is done by continual pre-training of the latest time series foundation model TimesFM on price data containing 100 million time points, spanning a range of financial instruments spanning hourly and daily granularities. The fine-tuned model demonstrates higher price prediction accuracy than the baseline model. We conduct mock trading for our model in various financial markets and show that it outperforms various benchmarks in terms of returns, sharpe ratio, max drawdown and trading cost.
Enhancing Financial Domain Adaptation of Language Models via Model Augmentation
Nov 14, 2024


The domain adaptation of language models, including large language models (LLMs), has become increasingly important as the use of such models continues to expand. This study demonstrates the effectiveness of Composition to Augment Language Models (CALM) in adapting to the financial domain. CALM is a model to extend the capabilities of existing models by introducing cross-attention between two LLMs with different functions. In our experiments, we developed a CALM to enhance the financial performance of an LLM with strong response capabilities by leveraging a financial-specialized LLM. Notably, the CALM was trained using a financial dataset different from the one used to train the financial-specialized LLM, confirming CALM's ability to adapt to various datasets. The models were evaluated through quantitative Japanese financial benchmarks and qualitative response comparisons, demonstrating that CALM enables superior responses with higher scores than the original models and baselines. Additionally, comparative experiments on connection points revealed that connecting the middle layers of the models is most effective in facilitating adaptation to the financial domain. These findings confirm that CALM is a practical approach for adapting LLMs to the financial domain.
The Construction of Instruction-tuned LLMs for Finance without Instruction Data Using Continual Pretraining and Model Merging
Sep 30, 2024



This paper proposes a novel method for constructing instruction-tuned large language models (LLMs) for finance without instruction data. Traditionally, developing such domain-specific LLMs has been resource-intensive, requiring a large dataset and significant computational power for continual pretraining and instruction tuning. Our study proposes a simpler approach that combines domain-specific continual pretraining with model merging. Given that general-purpose pretrained LLMs and their instruction-tuned LLMs are often publicly available, they can be leveraged to obtain the necessary instruction task vector. By merging this with a domain-specific pretrained vector, we can effectively create instruction-tuned LLMs for finance without additional instruction data. Our process involves two steps: first, we perform continual pretraining on financial data; second, we merge the instruction-tuned vector with the domain-specific pretrained vector. Our experiments demonstrate the successful construction of instruction-tuned LLMs for finance. One major advantage of our method is that the instruction-tuned and domain-specific pretrained vectors are nearly independent. This independence makes our approach highly effective. The Japanese financial instruction-tuned LLMs we developed in this study are available at https://huggingface.co/pfnet/nekomata-14b-pfn-qfin-inst-merge.
Construction of Domain-specified Japanese Large Language Model for Finance through Continual Pre-training
Apr 16, 2024

Large language models (LLMs) are now widely used in various fields, including finance. However, Japanese financial-specific LLMs have not been proposed yet. Hence, this study aims to construct a Japanese financial-specific LLM through continual pre-training. Before tuning, we constructed Japanese financial-focused datasets for continual pre-training. As a base model, we employed a Japanese LLM that achieved state-of-the-art performance on Japanese financial benchmarks among the 10-billion-class parameter models. After continual pre-training using the datasets and the base model, the tuned model performed better than the original model on the Japanese financial benchmarks. Moreover, the outputs comparison results reveal that the tuned model's outputs tend to be better than the original model's outputs in terms of the quality and length of the answers. These findings indicate that domain-specific continual pre-training is also effective for LLMs. The tuned model is publicly available on Hugging Face.
Experimental Analysis of Deep Hedging Using Artificial Market Simulations for Underlying Asset Simulators
Apr 15, 2024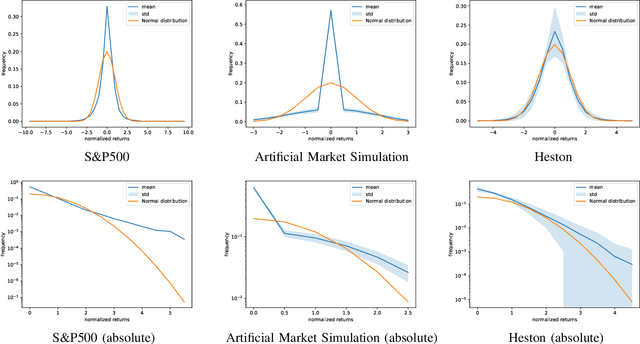



Derivative hedging and pricing are important and continuously studied topics in financial markets. Recently, deep hedging has been proposed as a promising approach that uses deep learning to approximate the optimal hedging strategy and can handle incomplete markets. However, deep hedging usually requires underlying asset simulations, and it is challenging to select the best model for such simulations. This study proposes a new approach using artificial market simulations for underlying asset simulations in deep hedging. Artificial market simulations can replicate the stylized facts of financial markets, and they seem to be a promising approach for deep hedging. We investigate the effectiveness of the proposed approach by comparing its results with those of the traditional approach, which uses mathematical finance models such as Brownian motion and Heston models for underlying asset simulations. The results show that the proposed approach can achieve almost the same level of performance as the traditional approach without mathematical finance models. Finally, we also reveal that the proposed approach has some limitations in terms of performance under certain conditions.
Construction of a Japanese Financial Benchmark for Large Language Models
Mar 22, 2024



With the recent development of large language models (LLMs), models that focus on certain domains and languages have been discussed for their necessity. There is also a growing need for benchmarks to evaluate the performance of current LLMs in each domain. Therefore, in this study, we constructed a benchmark comprising multiple tasks specific to the Japanese and financial domains and performed benchmark measurements on some models. Consequently, we confirmed that GPT-4 is currently outstanding, and that the constructed benchmarks function effectively. According to our analysis, our benchmark can differentiate benchmark scores among models in all performance ranges by combining tasks with different difficulties.
Error Analysis of Option Pricing via Deep PDE Solvers: Empirical Study
Nov 13, 2023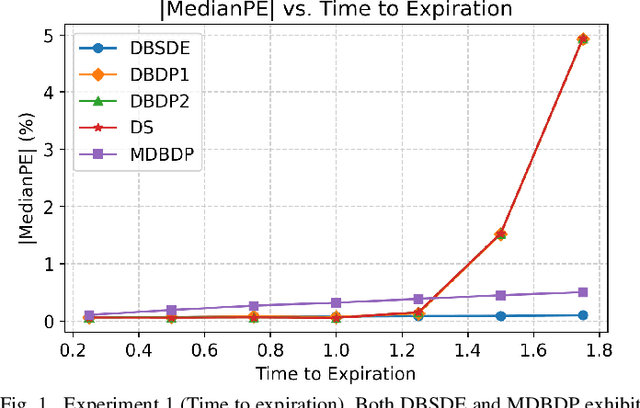
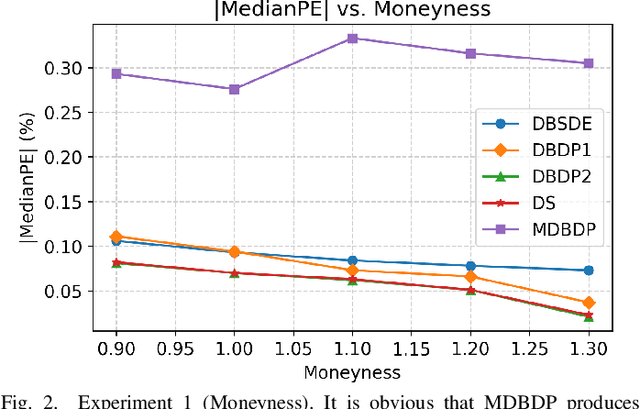
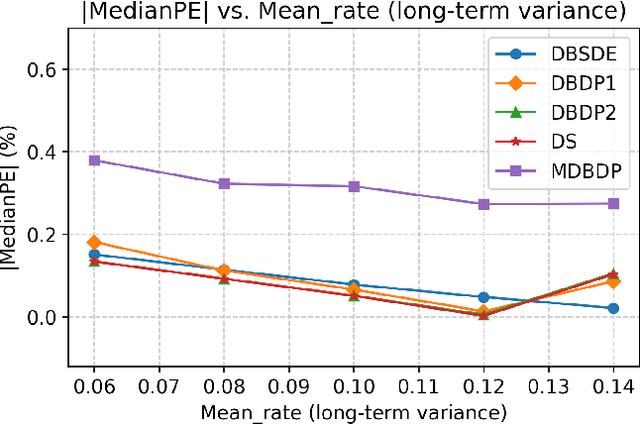
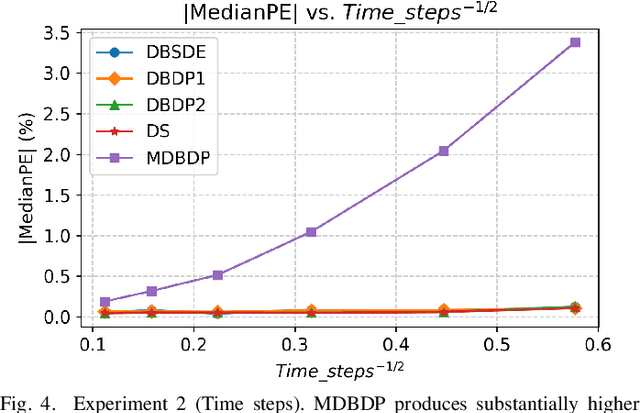
Option pricing, a fundamental problem in finance, often requires solving non-linear partial differential equations (PDEs). When dealing with multi-asset options, such as rainbow options, these PDEs become high-dimensional, leading to challenges posed by the curse of dimensionality. While deep learning-based PDE solvers have recently emerged as scalable solutions to this high-dimensional problem, their empirical and quantitative accuracy remains not well-understood, hindering their real-world applicability. In this study, we aimed to offer actionable insights into the utility of Deep PDE solvers for practical option pricing implementation. Through comparative experiments, we assessed the empirical performance of these solvers in high-dimensional contexts. Our investigation identified three primary sources of errors in Deep PDE solvers: (i) errors inherent in the specifications of the target option and underlying assets, (ii) errors originating from the asset model simulation methods, and (iii) errors stemming from the neural network training. Through ablation studies, we evaluated the individual impact of each error source. Our results indicate that the Deep BSDE method (DBSDE) is superior in performance and exhibits robustness against variations in option specifications. In contrast, some other methods are overly sensitive to option specifications, such as time to expiration. We also find that the performance of these methods improves inversely proportional to the square root of batch size and the number of time steps. This observation can aid in estimating computational resources for achieving desired accuracies with Deep PDE solvers.
PAMS: Platform for Artificial Market Simulations
Sep 19, 2023This paper presents a new artificial market simulation platform, PAMS: Platform for Artificial Market Simulations. PAMS is developed as a Python-based simulator that is easily integrated with deep learning and enabling various simulation that requires easy users' modification. In this paper, we demonstrate PAMS effectiveness through a study using agents predicting future prices by deep learning.