 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeriodic Event-Triggered Explicit Reference Governor for Constrained Attitude Control on SO(3)
Apr 05, 2026This letter addresses the constrained attitude control problem for rigid bodies directly on the special orthogonal group SO(3), avoiding singularities associated with parameterizations such as Euler angles. We propose a novel Periodic Event-Triggered Explicit Reference Governor (PET-ERG) that enforces input saturation and geometric pointing constraints without relying on online optimization. A key feature is a periodic event-triggered supervisory update: the auxiliary reference is updated only at sampled instants when a robust safety condition is met, thereby avoiding continuous-time reference updates and enabling a rigorous stability analysis of the cascade system on the manifold. Through this structured approach, we rigorously establish the asymptotic stability and exponential convergence of the closed-loop system for almost all initial configurations. Numerical simulations validate the effectiveness of the proposed control architecture and demonstrate constraint satisfaction and convergence properties.
When Object-Centric World Models Meet Policy Learning: From Pixels to Policies, and Where It Breaks
Nov 11, 2025Object-centric world models (OCWM) aim to decompose visual scenes into object-level representations, providing structured abstractions that could improve compositional generalization and data efficiency in reinforcement learning. We hypothesize that explicitly disentangled object-level representations, by localizing task-relevant information, can enhance policy performance across novel feature combinations. To test this hypothesis, we introduce DLPWM, a fully unsupervised, disentangled object-centric world model that learns object-level latents directly from pixels. DLPWM achieves strong reconstruction and prediction performance, including robustness to several out-of-distribution (OOD) visual variations. However, when used for downstream model-based control, policies trained on DLPWM latents underperform compared to DreamerV3. Through latent-trajectory analyses, we identify representation shift during multi-object interactions as a key driver of unstable policy learning. Our results suggest that, although object-centric perception supports robust visual modeling, achieving stable control requires mitigating latent drift.
System 0/1/2/3: Quad-process theory for multi-timescale embodied collective cognitive systems
Mar 08, 2025



This paper introduces the System 0/1/2/3 framework as an extension of dual-process theory, employing a quad-process model of cognition. Expanding upon System 1 (fast, intuitive thinking) and System 2 (slow, deliberative thinking), we incorporate System 0, which represents pre-cognitive embodied processes, and System 3, which encompasses collective intelligence and symbol emergence. We contextualize this model within Bergson's philosophy by adopting multi-scale time theory to unify the diverse temporal dynamics of cognition. System 0 emphasizes morphological computation and passive dynamics, illustrating how physical embodiment enables adaptive behavior without explicit neural processing. Systems 1 and 2 are explained from a constructive perspective, incorporating neurodynamical and AI viewpoints. In System 3, we introduce collective predictive coding to explain how societal-level adaptation and symbol emergence operate over extended timescales. This comprehensive framework ranges from rapid embodied reactions to slow-evolving collective intelligence, offering a unified perspective on cognition across multiple timescales, levels of abstraction, and forms of human intelligence. The System 0/1/2/3 model provides a novel theoretical foundation for understanding the interplay between adaptive and cognitive processes, thereby opening new avenues for research in cognitive science, AI, robotics, and collective intelligence.
Inference-Time Text-to-Video Alignment with Diffusion Latent Beam Search
Jan 31, 2025



The remarkable progress in text-to-video diffusion models enables photorealistic generations, although the contents of the generated video often include unnatural movement or deformation, reverse playback, and motionless scenes. Recently, an alignment problem has attracted huge attention, where we steer the output of diffusion models based on some quantity on the goodness of the content. Because there is a large room for improvement of perceptual quality along the frame direction, we should address which metrics we should optimize and how we can optimize them in the video generation. In this paper, we propose diffusion latent beam search with lookahead estimator, which can select better diffusion latent to maximize a given alignment reward, at inference time. We then point out that the improvement of perceptual video quality considering the alignment to prompts requires reward calibration by weighting existing metrics. When evaluating outputs by using vision language models as a proxy of humans, many previous metrics to quantify the naturalness of video do not always correlate with evaluation and also depend on the degree of dynamic descriptions in evaluation prompts. We demonstrate that our method improves the perceptual quality based on the calibrated reward, without model parameter update, and outputs the best generation compared to greedy search and best-of-N sampling. We provide practical guidelines on which axes, among search budget, lookahead steps for reward estimate, and denoising steps, in the reverse diffusion process, we should allocate the inference-time computation.
Generative Emergent Communication: Large Language Model is a Collective World Model
Dec 31, 2024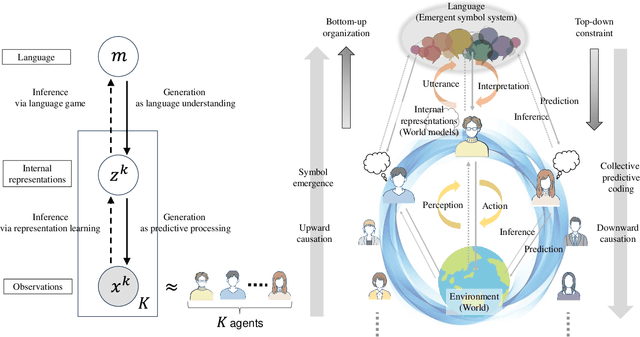

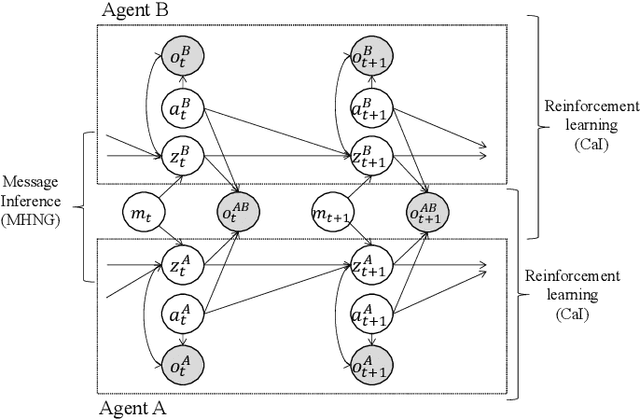

This study proposes a unifying theoretical framework called generative emergent communication (generative EmCom) that bridges emergent communication, world models, and large language models (LLMs) through the lens of collective predictive coding (CPC). The proposed framework formalizes the emergence of language and symbol systems through decentralized Bayesian inference across multiple agents, extending beyond conventional discriminative model-based approaches to emergent communication. This study makes the following two key contributions: First, we propose generative EmCom as a novel framework for understanding emergent communication, demonstrating how communication emergence in multi-agent reinforcement learning (MARL) can be derived from control as inference while clarifying its relationship to conventional discriminative approaches. Second, we propose a mathematical formulation showing the interpretation of LLMs as collective world models that integrate multiple agents' experiences through CPC. The framework provides a unified theoretical foundation for understanding how shared symbol systems emerge through collective predictive coding processes, bridging individual cognitive development and societal language evolution. Through mathematical formulations and discussion on prior works, we demonstrate how this framework explains fundamental aspects of language emergence and offers practical insights for understanding LLMs and developing sophisticated AI systems for improving human-AI interaction and multi-agent systems.
Refined and Segmented Price Sentiment Indices from Survey Comments
Nov 15, 2024



We aim to enhance a price sentiment index and to more precisely understand price trends from the perspective of not only consumers but also businesses. We extract comments related to prices from the Economy Watchers Survey conducted by the Cabinet Office of Japan and classify price trends using a large language model (LLM). We classify whether the survey sample reflects the perspective of consumers or businesses, and whether the comments pertain to goods or services by utilizing information on the fields of comments and the industries of respondents included in the Economy Watchers Survey. From these classified price-related comments, we construct price sentiment indices not only for a general purpose but also for more specific objectives by combining perspectives on consumers and prices, as well as goods and services. It becomes possible to achieve a more accurate classification of price directions by employing a LLM for classification. Furthermore, integrating the outputs of multiple LLMs suggests the potential for the better performance of the classification. The use of more accurately classified comments allows for the construction of an index with a higher correlation to existing indices than previous studies. We demonstrate that the correlation of the price index for consumers, which has a larger sample size, is further enhanced by selecting comments for aggregation based on the industry of the survey respondents.
ADOPT: Modified Adam Can Converge with Any $β_2$ with the Optimal Rate
Nov 05, 2024



Adam is one of the most popular optimization algorithms in deep learning. However, it is known that Adam does not converge in theory unless choosing a hyperparameter, i.e., $\beta_2$, in a problem-dependent manner. There have been many attempts to fix the non-convergence (e.g., AMSGrad), but they require an impractical assumption that the gradient noise is uniformly bounded. In this paper, we propose a new adaptive gradient method named ADOPT, which achieves the optimal convergence rate of $\mathcal{O} ( 1 / \sqrt{T} )$ with any choice of $\beta_2$ without depending on the bounded noise assumption. ADOPT addresses the non-convergence issue of Adam by removing the current gradient from the second moment estimate and changing the order of the momentum update and the normalization by the second moment estimate. We also conduct intensive numerical experiments, and verify that our ADOPT achieves superior results compared to Adam and its variants across a wide range of tasks, including image classification, generative modeling, natural language processing, and deep reinforcement learning. The implementation is available at https://github.com/iShohei220/adopt.
Object-Centric Temporal Consistency via Conditional Autoregressive Inductive Biases
Oct 21, 2024



Unsupervised object-centric learning from videos is a promising approach towards learning compositional representations that can be applied to various downstream tasks, such as prediction and reasoning. Recently, it was shown that pretrained Vision Transformers (ViTs) can be useful to learn object-centric representations on real-world video datasets. However, while these approaches succeed at extracting objects from the scenes, the slot-based representations fail to maintain temporal consistency across consecutive frames in a video, i.e. the mapping of objects to slots changes across the video. To address this, we introduce Conditional Autoregressive Slot Attention (CA-SA), a framework that enhances the temporal consistency of extracted object-centric representations in video-centric vision tasks. Leveraging an autoregressive prior network to condition representations on previous timesteps and a novel consistency loss function, CA-SA predicts future slot representations and imposes consistency across frames. We present qualitative and quantitative results showing that our proposed method outperforms the considered baselines on downstream tasks, such as video prediction and visual question-answering tasks.
Enhancing Unimodal Latent Representations in Multimodal VAEs through Iterative Amortized Inference
Oct 15, 2024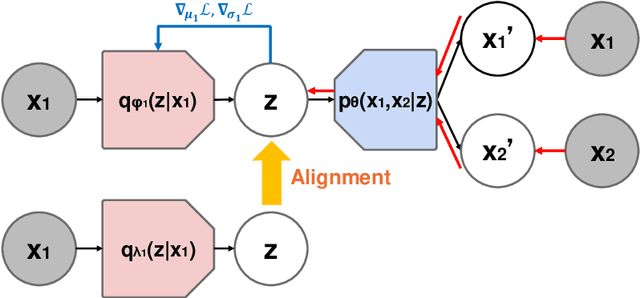
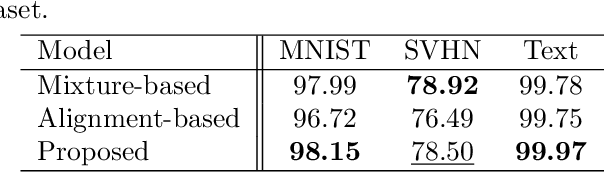


Multimodal variational autoencoders (VAEs) aim to capture shared latent representations by integrating information from different data modalities. A significant challenge is accurately inferring representations from any subset of modalities without training an impractical number (2^M) of inference networks for all possible modality combinations. Mixture-based models simplify this by requiring only as many inference models as there are modalities, aggregating unimodal inferences. However, they suffer from information loss when modalities are missing. Alignment-based VAEs address this by aligning unimodal inference models with a multimodal model through minimizing the Kullback-Leibler (KL) divergence but face issues due to amortization gaps, which compromise inference accuracy. To tackle these problems, we introduce multimodal iterative amortized inference, an iterative refinement mechanism within the multimodal VAE framework. This method overcomes information loss from missing modalities and minimizes the amortization gap by iteratively refining the multimodal inference using all available modalities. By aligning unimodal inference to this refined multimodal posterior, we achieve unimodal inferences that effectively incorporate multimodal information while requiring only unimodal inputs during inference. Experiments on benchmark datasets show that our approach improves inference performance, evidenced by higher linear classification accuracy and competitive cosine similarity, and enhances cross-modal generation, indicated by lower FID scores. This demonstrates that our method enhances inferred representations from unimodal inputs.
Interactive DualChecker for Mitigating Hallucinations in Distilling Large Language Models
Aug 22, 2024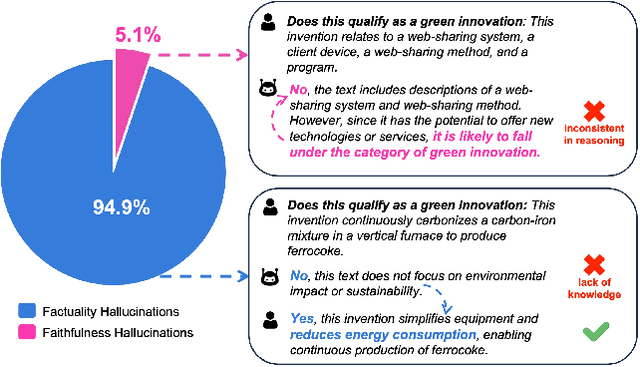

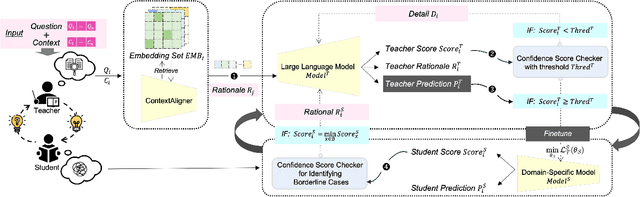
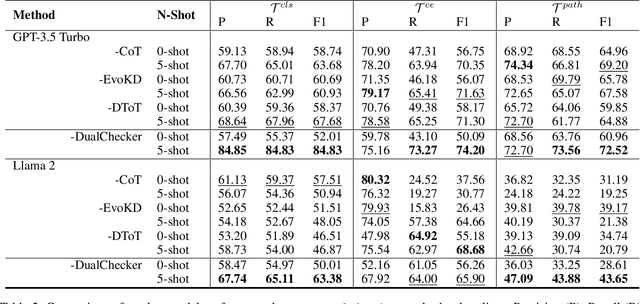
Large Language Models (LLMs) have demonstrated exceptional capabilities across various machine learning (ML) tasks. Given the high costs of creating annotated datasets for supervised learning, LLMs offer a valuable alternative by enabling effective few-shot in-context learning. However, these models can produce hallucinations, particularly in domains with incomplete knowledge. Additionally, current methods for knowledge distillation using LLMs often struggle to enhance the effectiveness of both teacher and student models. To address these challenges, we introduce DualChecker, an innovative framework designed to mitigate hallucinations and improve the performance of both teacher and student models during knowledge distillation. DualChecker employs ContextAligner to ensure that the context provided by teacher models aligns with human labeling standards. It also features a dynamic checker system that enhances model interaction: one component re-prompts teacher models with more detailed content when they show low confidence, and another identifies borderline cases from student models to refine the teaching templates. This interactive process promotes continuous improvement and effective knowledge transfer between the models. We evaluate DualChecker using a green innovation textual dataset that includes binary, multiclass, and token classification tasks. The experimental results show that DualChecker significantly outperforms existing state-of-the-art methods, achieving up to a 17% improvement in F1 score for teacher models and 10% for student models. Notably, student models fine-tuned with LLM predictions perform comparably to those fine-tuned with actual data, even in a challenging domain. We make all datasets, models, and code from this research publicly available.