 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Unimodal Latent Representations in Multimodal VAEs through Iterative Amortized Inference
Paper and Code
Oct 15, 2024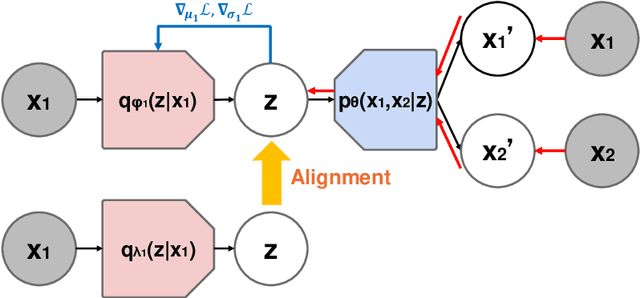
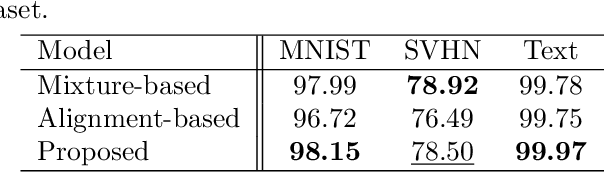


Multimodal variational autoencoders (VAEs) aim to capture shared latent representations by integrating information from different data modalities. A significant challenge is accurately inferring representations from any subset of modalities without training an impractical number (2^M) of inference networks for all possible modality combinations. Mixture-based models simplify this by requiring only as many inference models as there are modalities, aggregating unimodal inferences. However, they suffer from information loss when modalities are missing. Alignment-based VAEs address this by aligning unimodal inference models with a multimodal model through minimizing the Kullback-Leibler (KL) divergence but face issues due to amortization gaps, which compromise inference accuracy. To tackle these problems, we introduce multimodal iterative amortized inference, an iterative refinement mechanism within the multimodal VAE framework. This method overcomes information loss from missing modalities and minimizes the amortization gap by iteratively refining the multimodal inference using all available modalities. By aligning unimodal inference to this refined multimodal posterior, we achieve unimodal inferences that effectively incorporate multimodal information while requiring only unimodal inputs during inference. Experiments on benchmark datasets show that our approach improves inference performance, evidenced by higher linear classification accuracy and competitive cosine similarity, and enhances cross-modal generation, indicated by lower FID scores. This demonstrates that our method enhances inferred representations from unimodal inputs.