 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Text-to-Video Alignment with Diffusion Latent Beam Search
Jan 31, 2025



The remarkable progress in text-to-video diffusion models enables photorealistic generations, although the contents of the generated video often include unnatural movement or deformation, reverse playback, and motionless scenes. Recently, an alignment problem has attracted huge attention, where we steer the output of diffusion models based on some quantity on the goodness of the content. Because there is a large room for improvement of perceptual quality along the frame direction, we should address which metrics we should optimize and how we can optimize them in the video generation. In this paper, we propose diffusion latent beam search with lookahead estimator, which can select better diffusion latent to maximize a given alignment reward, at inference time. We then point out that the improvement of perceptual video quality considering the alignment to prompts requires reward calibration by weighting existing metrics. When evaluating outputs by using vision language models as a proxy of humans, many previous metrics to quantify the naturalness of video do not always correlate with evaluation and also depend on the degree of dynamic descriptions in evaluation prompts. We demonstrate that our method improves the perceptual quality based on the calibrated reward, without model parameter update, and outputs the best generation compared to greedy search and best-of-N sampling. We provide practical guidelines on which axes, among search budget, lookahead steps for reward estimate, and denoising steps, in the reverse diffusion process, we should allocate the inference-time computation.
ADOPT: Modified Adam Can Converge with Any $β_2$ with the Optimal Rate
Nov 05, 2024



Adam is one of the most popular optimization algorithms in deep learning. However, it is known that Adam does not converge in theory unless choosing a hyperparameter, i.e., $\beta_2$, in a problem-dependent manner. There have been many attempts to fix the non-convergence (e.g., AMSGrad), but they require an impractical assumption that the gradient noise is uniformly bounded. In this paper, we propose a new adaptive gradient method named ADOPT, which achieves the optimal convergence rate of $\mathcal{O} ( 1 / \sqrt{T} )$ with any choice of $\beta_2$ without depending on the bounded noise assumption. ADOPT addresses the non-convergence issue of Adam by removing the current gradient from the second moment estimate and changing the order of the momentum update and the normalization by the second moment estimate. We also conduct intensive numerical experiments, and verify that our ADOPT achieves superior results compared to Adam and its variants across a wide range of tasks, including image classification, generative modeling, natural language processing, and deep reinforcement learning. The implementation is available at https://github.com/iShohei220/adopt.
Enhancing Unimodal Latent Representations in Multimodal VAEs through Iterative Amortized Inference
Oct 15, 2024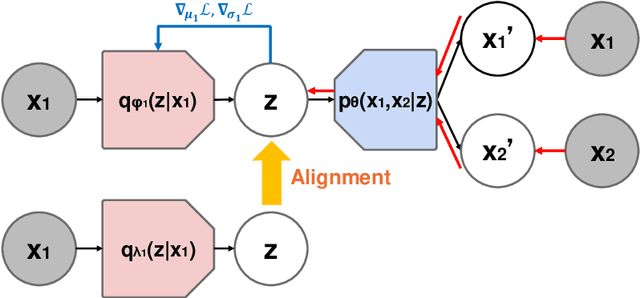
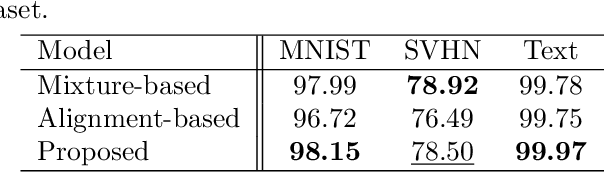


Multimodal variational autoencoders (VAEs) aim to capture shared latent representations by integrating information from different data modalities. A significant challenge is accurately inferring representations from any subset of modalities without training an impractical number (2^M) of inference networks for all possible modality combinations. Mixture-based models simplify this by requiring only as many inference models as there are modalities, aggregating unimodal inferences. However, they suffer from information loss when modalities are missing. Alignment-based VAEs address this by aligning unimodal inference models with a multimodal model through minimizing the Kullback-Leibler (KL) divergence but face issues due to amortization gaps, which compromise inference accuracy. To tackle these problems, we introduce multimodal iterative amortized inference, an iterative refinement mechanism within the multimodal VAE framework. This method overcomes information loss from missing modalities and minimizes the amortization gap by iteratively refining the multimodal inference using all available modalities. By aligning unimodal inference to this refined multimodal posterior, we achieve unimodal inferences that effectively incorporate multimodal information while requiring only unimodal inputs during inference. Experiments on benchmark datasets show that our approach improves inference performance, evidenced by higher linear classification accuracy and competitive cosine similarity, and enhances cross-modal generation, indicated by lower FID scores. This demonstrates that our method enhances inferred representations from unimodal inputs.
SSM Meets Video Diffusion Models: Efficient Video Generation with Structured State Spaces
Mar 12, 2024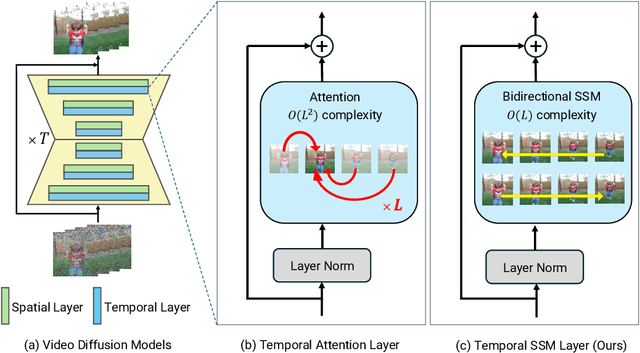



Given the remarkable achievements in image generation through diffusion models, the research community has shown increasing interest in extending these models to video generation. Recent diffusion models for video generation have predominantly utilized attention layers to extract temporal features. However, attention layers are limited by their memory consumption, which increases quadratically with the length of the sequence. This limitation presents significant challenges when attempting to generate longer video sequences using diffusion models. To overcome this challenge, we propose leveraging state-space models (SSMs). SSMs have recently gained attention as viable alternatives due to their linear memory consumption relative to sequence length. In the experiments, we first evaluate our SSM-based model with UCF101, a standard benchmark of video generation. In addition, to investigate the potential of SSMs for longer video generation, we perform an experiment using the MineRL Navigate dataset, varying the number of frames to 64 and 150. In these settings, our SSM-based model can considerably save memory consumption for longer sequences, while maintaining competitive FVD scores to the attention-based models. Our codes are available at https://github.com/shim0114/SSM-Meets-Video-Diffusion-Models.