 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Analogical Reasoning in Transformers
Feb 03, 2026Analogy is a central faculty of human intelligence, enabling abstract patterns discovered in one domain to be applied to another. Despite its central role in cognition, the mechanisms by which Transformers acquire and implement analogical reasoning remain poorly understood. In this work, inspired by the notion of functors in category theory, we formalize analogical reasoning as the inference of correspondences between entities across categories. Based on this formulation, we introduce synthetic tasks that evaluate the emergence of analogical reasoning under controlled settings. We find that the emergence of analogical reasoning is highly sensitive to data characteristics, optimization choices, and model scale. Through mechanistic analysis, we show that analogical reasoning in Transformers decomposes into two key components: (1) geometric alignment of relational structure in the embedding space, and (2) the application of a functor within the Transformer. These mechanisms enable models to transfer relational structure from one category to another, realizing analogy. Finally, we quantify these effects and find that the same trends are observed in pretrained LLMs. In doing so, we move analogy from an abstract cognitive notion to a concrete, mechanistically grounded phenomenon in modern neural networks.
Interpreting Multi-Attribute Confounding through Numerical Attributes in Large Language Models
Nov 10, 2025



Although behavioral studies have documented numerical reasoning errors in large language models (LLMs), the underlying representational mechanisms remain unclear. We hypothesize that numerical attributes occupy shared latent subspaces and investigate two questions:(1) How do LLMs internally integrate multiple numerical attributes of a single entity? (2)How does irrelevant numerical context perturb these representations and their downstream outputs? To address these questions, we combine linear probing with partial correlation analysis and prompt-based vulnerability tests across models of varying sizes. Our results show that LLMs encode real-world numerical correlations but tend to systematically amplify them. Moreover, irrelevant context induces consistent shifts in magnitude representations, with downstream effects that vary by model size. These findings reveal a vulnerability in LLM decision-making and lay the groundwork for fairer, representation-aware control under multi-attribute entanglement.
Topology of Reasoning: Understanding Large Reasoning Models through Reasoning Graph Properties
Jun 06, 2025Recent large-scale reasoning models have achieved state-of-the-art performance on challenging mathematical benchmarks, yet the internal mechanisms underlying their success remain poorly understood. In this work, we introduce the notion of a reasoning graph, extracted by clustering hidden-state representations at each reasoning step, and systematically analyze three key graph-theoretic properties: cyclicity, diameter, and small-world index, across multiple tasks (GSM8K, MATH500, AIME 2024). Our findings reveal that distilled reasoning models (e.g., DeepSeek-R1-Distill-Qwen-32B) exhibit significantly more recurrent cycles (about 5 per sample), substantially larger graph diameters, and pronounced small-world characteristics (about 6x) compared to their base counterparts. Notably, these structural advantages grow with task difficulty and model capacity, with cycle detection peaking at the 14B scale and exploration diameter maximized in the 32B variant, correlating positively with accuracy. Furthermore, we show that supervised fine-tuning on an improved dataset systematically expands reasoning graph diameters in tandem with performance gains, offering concrete guidelines for dataset design aimed at boosting reasoning capabilities. By bridging theoretical insights into reasoning graph structures with practical recommendations for data construction, our work advances both the interpretability and the efficacy of large reasoning models.
Beyond Induction Heads: In-Context Meta Learning Induces Multi-Phase Circuit Emergence
May 22, 2025Transformer-based language models exhibit In-Context Learning (ICL), where predictions are made adaptively based on context. While prior work links induction heads to ICL through a sudden jump in accuracy, this can only account for ICL when the answer is included within the context. However, an important property of practical ICL in large language models is the ability to meta-learn how to solve tasks from context, rather than just copying answers from context; how such an ability is obtained during training is largely unexplored. In this paper, we experimentally clarify how such meta-learning ability is acquired by analyzing the dynamics of the model's circuit during training. Specifically, we extend the copy task from previous research into an In-Context Meta Learning setting, where models must infer a task from examples to answer queries. Interestingly, in this setting, we find that there are multiple phases in the process of acquiring such abilities, and that a unique circuit emerges in each phase, contrasting with the single-phases change in induction heads. The emergence of such circuits can be related to several phenomena known in large language models, and our analysis lead to a deeper understanding of the source of the transformer's ICL ability.
Rethinking Evaluation of Sparse Autoencoders through the Representation of Polysemous Words
Jan 09, 2025



Sparse autoencoders (SAEs) have gained a lot of attention as a promising tool to improve the interpretability of large language models (LLMs) by mapping the complex superposition of polysemantic neurons into monosemantic features and composing a sparse dictionary of words. However, traditional performance metrics like Mean Squared Error and L0 sparsity ignore the evaluation of the semantic representational power of SAEs -- whether they can acquire interpretable monosemantic features while preserving the semantic relationship of words. For instance, it is not obvious whether a learned sparse feature could distinguish different meanings in one word. In this paper, we propose a suite of evaluations for SAEs to analyze the quality of monosemantic features by focusing on polysemous words. Our findings reveal that SAEs developed to improve the MSE-L0 Pareto frontier may confuse interpretability, which does not necessarily enhance the extraction of monosemantic features. The analysis of SAEs with polysemous words can also figure out the internal mechanism of LLMs; deeper layers and the Attention module contribute to distinguishing polysemy in a word. Our semantics focused evaluation offers new insights into the polysemy and the existing SAE objective and contributes to the development of more practical SAEs.
ADOPT: Modified Adam Can Converge with Any $β_2$ with the Optimal Rate
Nov 05, 2024



Adam is one of the most popular optimization algorithms in deep learning. However, it is known that Adam does not converge in theory unless choosing a hyperparameter, i.e., $\beta_2$, in a problem-dependent manner. There have been many attempts to fix the non-convergence (e.g., AMSGrad), but they require an impractical assumption that the gradient noise is uniformly bounded. In this paper, we propose a new adaptive gradient method named ADOPT, which achieves the optimal convergence rate of $\mathcal{O} ( 1 / \sqrt{T} )$ with any choice of $\beta_2$ without depending on the bounded noise assumption. ADOPT addresses the non-convergence issue of Adam by removing the current gradient from the second moment estimate and changing the order of the momentum update and the normalization by the second moment estimate. We also conduct intensive numerical experiments, and verify that our ADOPT achieves superior results compared to Adam and its variants across a wide range of tasks, including image classification, generative modeling, natural language processing, and deep reinforcement learning. The implementation is available at https://github.com/iShohei220/adopt.
Interpreting Grokked Transformers in Complex Modular Arithmetic
Feb 27, 2024

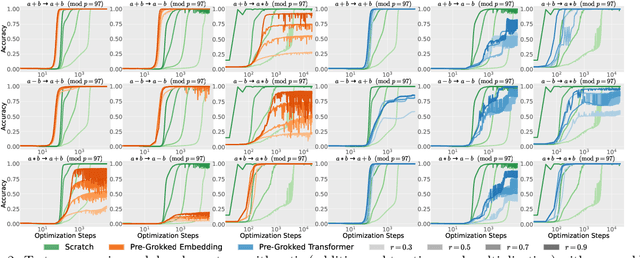

Grokking has been actively explored to reveal the mystery of delayed generalization. Identifying interpretable algorithms inside the grokked models is a suggestive hint to understanding its mechanism. In this work, beyond the simplest and well-studied modular addition, we observe the internal circuits learned through grokking in complex modular arithmetic via interpretable reverse engineering, which highlights the significant difference in their dynamics: subtraction poses a strong asymmetry on Transformer; multiplication requires cosine-biased components at all the frequencies in a Fourier domain; polynomials often result in the superposition of the patterns from elementary arithmetic, but clear patterns do not emerge in challenging cases; grokking can easily occur even in higher-degree formulas with basic symmetric and alternating expressions. We also introduce the novel progress measure for modular arithmetic; Fourier Frequency Sparsity and Fourier Coefficient Ratio, which not only indicate the late generalization but also characterize distinctive internal representations of grokked models per modular operation. Our empirical analysis emphasizes the importance of holistic evaluation among various combinations.
Grokking Tickets: Lottery Tickets Accelerate Grokking
Oct 30, 2023



Grokking is one of the most surprising puzzles in neural network generalization: a network first reaches a memorization solution with perfect training accuracy and poor generalization, but with further training, it reaches a perfectly generalized solution. We aim to analyze the mechanism of grokking from the lottery ticket hypothesis, identifying the process to find the lottery tickets (good sparse subnetworks) as the key to describing the transitional phase between memorization and generalization. We refer to these subnetworks as ''Grokking tickets'', which is identified via magnitude pruning after perfect generalization. First, using ''Grokking tickets'', we show that the lottery tickets drastically accelerate grokking compared to the dense networks on various configurations (MLP and Transformer, and an arithmetic and image classification tasks). Additionally, to verify that ''Grokking ticket'' are a more critical factor than weight norms, we compared the ''good'' subnetworks with a dense network having the same L1 and L2 norms. Results show that the subnetworks generalize faster than the controlled dense model. In further investigations, we discovered that at an appropriate pruning rate, grokking can be achieved even without weight decay. We also show that speedup does not happen when using tickets identified at the memorization solution or transition between memorization and generalization or when pruning networks at the initialization (Random pruning, Grasp, SNIP, and Synflow). The results indicate that the weight norm of network parameters is not enough to explain the process of grokking, but the importance of finding good subnetworks to describe the transition from memorization to generalization. The implementation code can be accessed via this link: \url{https://github.com/gouki510/Grokking-Tickets}.