 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Koopman Spectral Profiling for Predicting and Preventing Transformer Training Instability
Feb 26, 2026Training divergence in transformers wastes compute, yet practitioners discover instability only after expensive runs begin. They therefore need an expected probability of failure for a transformer before training starts. Our study of Residual Koopman Spectral Profiling (RKSP) provides such an estimate. From a single forward pass at initialization, RKSP extracts Koopman spectral features by applying whitened dynamic mode decomposition to layer-wise residual snapshots. Our central diagnostic, the near-unit spectral mass, quantifies the fraction of modes concentrated near the unit circle, which captures instability risk. For predicting divergence across extensive configurations, this estimator achieves an AUROC of 0.995, outperforming the best gradient baseline. We further make this diagnostic actionable through Koopman Spectral Shaping (KSS), which reshapes spectra during training. We empirically validate that our method works in practice: RKSP predicts divergence at initialization, and when RKSP flags high risk, turning on KSS successfully prevents divergence. In the challenging high learning rate regime without normalization layers, KSS reduces the divergence rate from 66.7% to 12.5% and enables learning rates that are 50% to 150% higher. These findings generalize to WikiText-103 language modeling, vision transformers on CIFAR-10, and pretrained language models, including GPT-2 and LLaMA-2 up to 7B, as well as emerging architectures such as MoE, Mamba-style SSMs, and KAN.
Position Encoding with Random Float Sampling Enhances Length Generalization of Transformers
Feb 15, 2026Length generalization is the ability of language models to maintain performance on inputs longer than those seen during pretraining. In this work, we introduce a simple yet powerful position encoding (PE) strategy, Random Float Sampling (RFS), that generalizes well to lengths unseen during pretraining or fine-tuning. In particular, instead of selecting position indices from a predefined discrete set, RFS uses randomly sampled continuous values, thereby avoiding out-of-distribution (OOD) issues on unseen lengths by exposing the model to diverse indices during training. Since assigning indices to tokens is a common and fundamental procedure in widely used PEs, the advantage of RFS can easily be incorporated into, for instance, the absolute sinusoidal encoding, RoPE, and ALiBi. Experiments corroborate its effectiveness by showing that RFS results in superior performance in length generalization tasks as well as zero-shot commonsense reasoning benchmarks.
$\infty$-MoE: Generalizing Mixture of Experts to Infinite Experts
Jan 25, 2026The Mixture of Experts (MoE) selects a few feed-forward networks (FFNs) per token, achieving an effective trade-off between computational cost and performance. In conventional MoE, each expert is treated as entirely independent, and experts are combined in a discrete space. As a result, when the number of experts increases, it becomes difficult to train each expert effectively. To stabilize training while increasing the number of experts, we propose $\infty$-MoE that selects a portion of the parameters of large FFNs based on continuous values sampled for each token. By considering experts in a continuous space, this approach allows for an infinite number of experts while maintaining computational efficiency. Experiments show that a GPT-2 Small-based $\infty$-MoE model, with 129M active and 186M total parameters, achieves comparable performance to a dense GPT-2 Medium with 350M parameters. Adjusting the number of sampled experts at inference time allows for a flexible trade-off between accuracy and speed, with an improvement of up to 2.5\% in accuracy over conventional MoE.
Beyond Induction Heads: In-Context Meta Learning Induces Multi-Phase Circuit Emergence
May 22, 2025Transformer-based language models exhibit In-Context Learning (ICL), where predictions are made adaptively based on context. While prior work links induction heads to ICL through a sudden jump in accuracy, this can only account for ICL when the answer is included within the context. However, an important property of practical ICL in large language models is the ability to meta-learn how to solve tasks from context, rather than just copying answers from context; how such an ability is obtained during training is largely unexplored. In this paper, we experimentally clarify how such meta-learning ability is acquired by analyzing the dynamics of the model's circuit during training. Specifically, we extend the copy task from previous research into an In-Context Meta Learning setting, where models must infer a task from examples to answer queries. Interestingly, in this setting, we find that there are multiple phases in the process of acquiring such abilities, and that a unique circuit emerges in each phase, contrasting with the single-phases change in induction heads. The emergence of such circuits can be related to several phenomena known in large language models, and our analysis lead to a deeper understanding of the source of the transformer's ICL ability.
ADOPT: Modified Adam Can Converge with Any $β_2$ with the Optimal Rate
Nov 05, 2024



Adam is one of the most popular optimization algorithms in deep learning. However, it is known that Adam does not converge in theory unless choosing a hyperparameter, i.e., $\beta_2$, in a problem-dependent manner. There have been many attempts to fix the non-convergence (e.g., AMSGrad), but they require an impractical assumption that the gradient noise is uniformly bounded. In this paper, we propose a new adaptive gradient method named ADOPT, which achieves the optimal convergence rate of $\mathcal{O} ( 1 / \sqrt{T} )$ with any choice of $\beta_2$ without depending on the bounded noise assumption. ADOPT addresses the non-convergence issue of Adam by removing the current gradient from the second moment estimate and changing the order of the momentum update and the normalization by the second moment estimate. We also conduct intensive numerical experiments, and verify that our ADOPT achieves superior results compared to Adam and its variants across a wide range of tasks, including image classification, generative modeling, natural language processing, and deep reinforcement learning. The implementation is available at https://github.com/iShohei220/adopt.
SSM Meets Video Diffusion Models: Efficient Video Generation with Structured State Spaces
Mar 12, 2024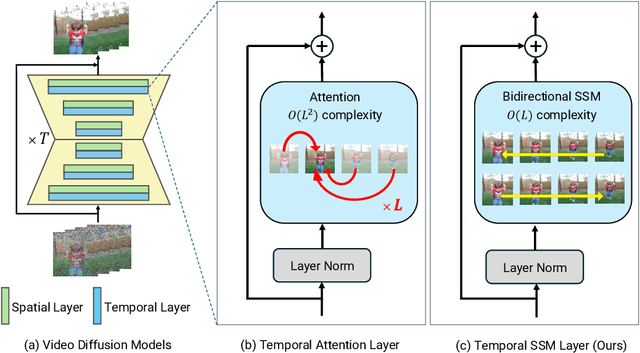



Given the remarkable achievements in image generation through diffusion models, the research community has shown increasing interest in extending these models to video generation. Recent diffusion models for video generation have predominantly utilized attention layers to extract temporal features. However, attention layers are limited by their memory consumption, which increases quadratically with the length of the sequence. This limitation presents significant challenges when attempting to generate longer video sequences using diffusion models. To overcome this challenge, we propose leveraging state-space models (SSMs). SSMs have recently gained attention as viable alternatives due to their linear memory consumption relative to sequence length. In the experiments, we first evaluate our SSM-based model with UCF101, a standard benchmark of video generation. In addition, to investigate the potential of SSMs for longer video generation, we perform an experiment using the MineRL Navigate dataset, varying the number of frames to 64 and 150. In these settings, our SSM-based model can considerably save memory consumption for longer sequences, while maintaining competitive FVD scores to the attention-based models. Our codes are available at https://github.com/shim0114/SSM-Meets-Video-Diffusion-Models.
End-to-end Training of Deep Boltzmann Machines by Unbiased Contrastive Divergence with Local Mode Initialization
May 31, 2023We address the problem of biased gradient estimation in deep Boltzmann machines (DBMs). The existing method to obtain an unbiased estimator uses a maximal coupling based on a Gibbs sampler, but when the state is high-dimensional, it takes a long time to converge. In this study, we propose to use a coupling based on the Metropolis-Hastings (MH) and to initialize the state around a local mode of the target distribution. Because of the propensity of MH to reject proposals, the coupling tends to converge in only one step with a high probability, leading to high efficiency. We find that our method allows DBMs to be trained in an end-to-end fashion without greedy pretraining. We also propose some practical techniques to further improve the performance of DBMs. We empirically demonstrate that our training algorithm enables DBMs to show comparable generative performance to other deep generative models, achieving the FID score of 10.33 for MNIST.
Langevin Autoencoders for Learning Deep Latent Variable Models
Sep 15, 2022



Markov chain Monte Carlo (MCMC), such as Langevin dynamics, is valid for approximating intractable distributions. However, its usage is limited in the context of deep latent variable models owing to costly datapoint-wise sampling iterations and slow convergence. This paper proposes the amortized Langevin dynamics (ALD), wherein datapoint-wise MCMC iterations are entirely replaced with updates of an encoder that maps observations into latent variables. This amortization enables efficient posterior sampling without datapoint-wise iterations. Despite its efficiency, we prove that ALD is valid as an MCMC algorithm, whose Markov chain has the target posterior as a stationary distribution under mild assumptions. Based on the ALD, we also present a new deep latent variable model named the Langevin autoencoder (LAE). Interestingly, the LAE can be implemented by slightly modifying the traditional autoencoder. Using multiple synthetic datasets, we first validate that ALD can properly obtain samples from target posteriors. We also evaluate the LAE on the image generation task, and show that our LAE can outperform existing methods based on variational inference, such as the variational autoencoder, and other MCMC-based methods in terms of the test likelihood.
World Robot Challenge 2020 -- Partner Robot: A Data-Driven Approach for Room Tidying with Mobile Manipulator
Jul 22, 2022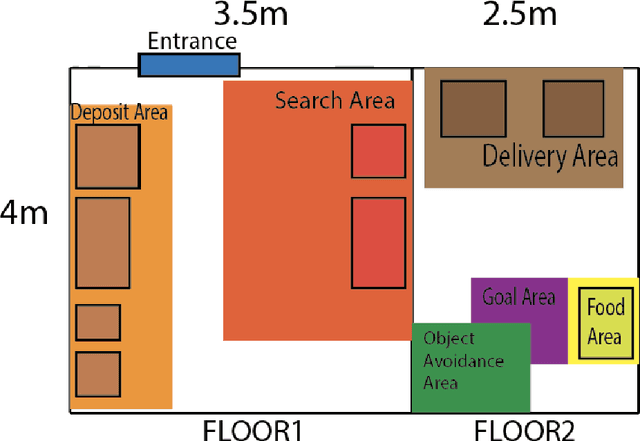


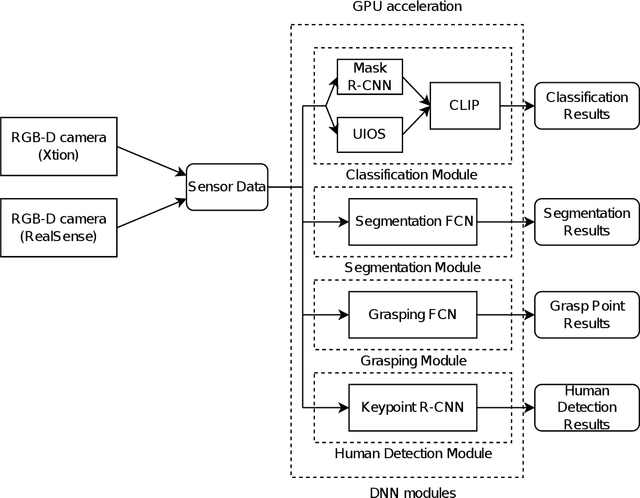
Tidying up a household environment using a mobile manipulator poses various challenges in robotics, such as adaptation to large real-world environmental variations, and safe and robust deployment in the presence of humans.The Partner Robot Challenge in World Robot Challenge (WRC) 2020, a global competition held in September 2021, benchmarked tidying tasks in the real home environments, and importantly, tested for full system performances.For this challenge, we developed an entire household service robot system, which leverages a data-driven approach to adapt to numerous edge cases that occur during the execution, instead of classical manual pre-programmed solutions. In this paper, we describe the core ingredients of the proposed robot system, including visual recognition, object manipulation, and motion planning. Our robot system won the second prize, verifying the effectiveness and potential of data-driven robot systems for mobile manipulation in home environments.