 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexLAM: Resolving the Bottleneck Trade-off in Latent Action Learning
Jun 17, 2026Latent actions provide a compact interface between action-free video and downstream decision-making, yet existing Latent Action Models (LAMs) force every transition through a fixed-capacity bottleneck. We identify a bottleneck trade-off: overly tight codes can discard transition cues needed for action alignment, while overly loose codes preserve additional transition variation that must be resolved when alignment labels are scarce or narrowly distributed. FlexLAM replaces this fixed capacity with variable-length latent actions trained by nested dropout, yielding prefix-valid codes that capture compact transition structure first and add detail only when needed, without new architectures or losses. A single FlexLAM matches or surpasses separately trained fixed-capacity LAMs at every evaluated token budget under standard scarce-label supervision and under a low-return single-task alignment stress test, indicating that FlexLAM is not merely adjustable at inference time but learns a better latent-action interface at the same token budgets. The same model supports inference-time token-budget adjustment without retraining, and FlexLAM improves Ego4D transition reconstruction. These results suggest that variable-length latent actions are an architecture-free, drop-in upgrade to the fixed-capacity bottleneck in latent action models, latent-action world models, and video-pretrained action interfaces.
YUBI: Yielding Universal Bidigital Interface for Bimanual Dexterous Manipulation at Scale
Jun 08, 2026We introduce Yielding Universal Bidigital Interface (YUBI), a finger-aligned gripper designed to enable intuitive, ergonomic, and scalable data collection for bimanual dexterous manipulation. While handheld data collection systems such as Universal Manipulation Interface (UMI) enable affordable data collection, their bulky pistol-grip designs can pose ergonomic and usability challenges for fine-grained, dexterous manipulation tasks. To address this, YUBI presents a distinct design principle: yielding, finger-driven actuation that directly maps human finger movements to gripper jaw motion. Using the YUBI devices, we set up a data collection system with integrated VR-based 6 DoF tracking of the gripper, ensuring high-fidelity trajectory data acquisition. We curate a UMI-based dataset of unprecedented scale: 8,434 hours across 1.20M episodes and 119 tasks. Experiments show that YUBI offers advantages over the UMI gripper in versatility for complex bimanual tasks, dexterity, and operational efficiency. A single policy trained on the YUBI dataset transfers across multiple bimanual robots (UR, Franka, and ELEY) simply by mounting the gripper on each platform, confirming that the collected data are directly executable as policy supervision. We release the gripper hardware, data-collection software, and dataset as one integrated stack, offering the open community a reproducible path to large-scale data acquisition for advancing robotic foundation models.
See Less, Specify More: Visual Evidence Budgets for Generalizable VLAs
Jun 01, 2026Generalization remains a central bottleneck for vision-language-action (VLA) models: under distractors, appearance shifts, and semantically similar tasks, the policy must often infer local execution details from coarse instructions while also deciding which parts of the image matter for control. We present S2 (See Less, Specify More), a framework for improving VLA generalization by training the executor under a cleaner interface. Specify More preserves the original instruction as a stable high-level goal while relabeling each trajectory into refined trajectory- and subtask-level language that disambiguates the current execution mode. Unlike native attention, See Less imposes an explicit visual evidence budget, training the executor to act from task-sufficient evidence rather than unconstrained visual context, without any region or mask annotation. This interface lets the executor follow detailed guidance without relying on distracting visual patches or resolving avoidable ambiguity on its own, and it remains compatible with off-the-shelf VLM planners through in-context learning. Across our main evaluation settings, S2 improves overall generalization metrics by changing the executor's learning problem: coarse instructions induce avoidable supervision aliasing, goal-preserving local guidance outperforms instruction replacement in our main ablations, and explicit evidence budgeting reduces dependence on broad visual context beyond efficiency considerations. Across eight real-robot tasks on TX-G2 (an AgiBot G2-compatible variant) and HSR, S2 raises mean subtask success from 54.2% to 79.0% over pi0.5. Together, these results suggest that VLA generalization improves when the executor is trained to act from informative local guidance and task-sufficient visual evidence, rather than recovering both from weak supervision.
Continuous Reasoning for Vision-Language-Action
May 29, 2026Natural language is a powerful reasoning medium for language and vision-language models, but it is mismatched to the granularity of continuous control. Text and explicit subgoals operate at task-level granularity, whereas vision-language-action (VLA) policies must choose actions at a much finer temporal scale; a single reasoning step can therefore span many action chunks while remaining only weakly coupled to the action needed now. This suggests a different question for VLA: what should play the role of language? We argue that a useful VLA reasoning medium must be shareable across model instances, verifiable through downstream action improvement, and aligned with temporally extended control structure. Based on this view, we propose Continuous Reasoning for Vision-Language-Action. Our model first predicts continuous reasoning in the form of a structured set of continuous thoughts, then reuses them as shared context for chunk-structured action generation. Better action prediction alone does not certify good reasoning: if the same internal medium cannot be shared across model instances and independently verified through improved downstream control, the added latent may simply become a model-private shortcut that helps on seen behaviors without supporting generalizable control. We therefore instantiate continuous reasoning as a shared Gaussian latent interface and train it with a self-verification objective in which an exponential-moving-average teacher must successfully consume the student's reasoning when predicting target actions. Empirically, Continuous Reasoning improves LIBERO-PRO robustness and performs strongly on real robots, raising mean subtask success over π0.5 by 40.4% on TX-G2, an AgiBot G2-compatible variant, and 26.3% on HSR. This suggests that reasoning in VLA is less about extra tokens than about a shareable, verifiable internal language for action.
A Comprehensive Survey on Physical Risk Control in the Era of Foundation Model-enabled Robotics
May 19, 2025Recent Foundation Model-enabled robotics (FMRs) display greatly improved general-purpose skills, enabling more adaptable automation than conventional robotics. Their ability to handle diverse tasks thus creates new opportunities to replace human labor. However, unlike general foundation models, FMRs interact with the physical world, where their actions directly affect the safety of humans and surrounding objects, requiring careful deployment and control. Based on this proposition, our survey comprehensively summarizes robot control approaches to mitigate physical risks by covering all the lifespan of FMRs ranging from pre-deployment to post-accident stage. Specifically, we broadly divide the timeline into the following three phases: (1) pre-deployment phase, (2) pre-incident phase, and (3) post-incident phase. Throughout this survey, we find that there is much room to study (i) pre-incident risk mitigation strategies, (ii) research that assumes physical interaction with humans, and (iii) essential issues of foundation models themselves. We hope that this survey will be a milestone in providing a high-resolution analysis of the physical risks of FMRs and their control, contributing to the realization of a good human-robot relationship.
Real-World Robot Applications of Foundation Models: A Review
Feb 08, 2024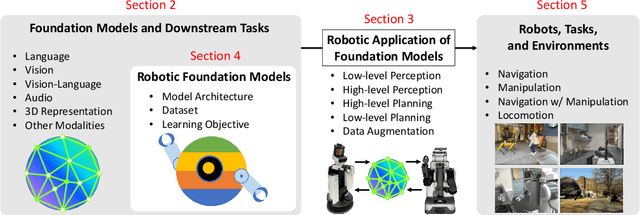
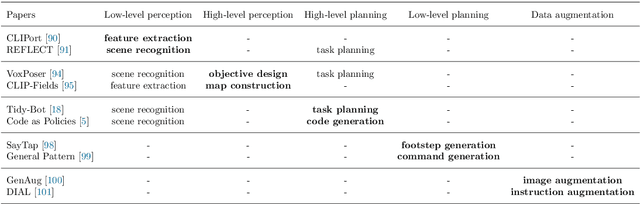
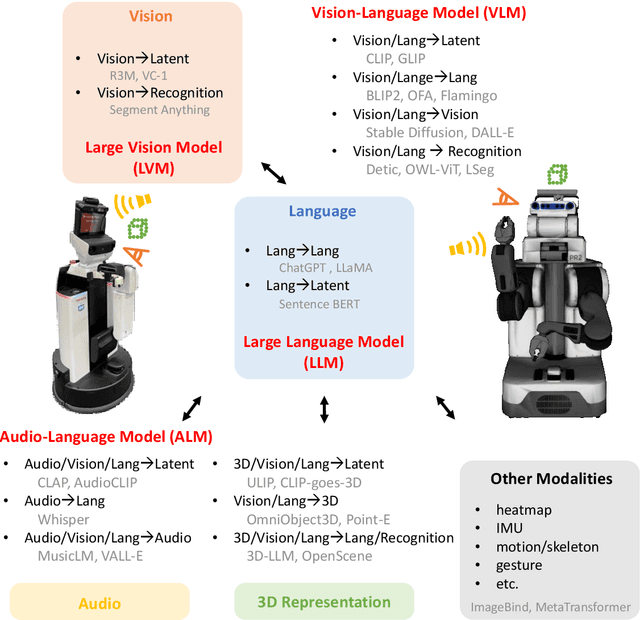
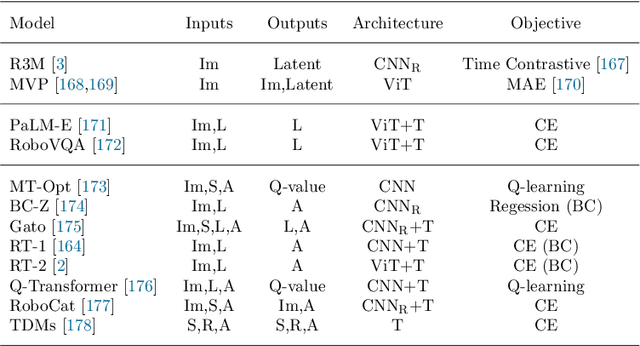
Recent developments in foundation models, like Large Language Models (LLMs) and Vision-Language Models (VLMs), trained on extensive data, facilitate flexible application across different tasks and modalities. Their impact spans various fields, including healthcare, education, and robotics. This paper provides an overview of the practical application of foundation models in real-world robotics, with a primary emphasis on the replacement of specific components within existing robot systems. The summary encompasses the perspective of input-output relationships in foundation models, as well as their role in perception, motion planning, and control within the field of robotics. This paper concludes with a discussion of future challenges and implications for practical robot applications.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
TRAIL Team Description Paper for RoboCup@Home 2023
Oct 05, 2023



Our team, TRAIL, consists of AI/ML laboratory members from The University of Tokyo. We leverage our extensive research experience in state-of-the-art machine learning to build general-purpose in-home service robots. We previously participated in two competitions using Human Support Robot (HSR): RoboCup@Home Japan Open 2020 (DSPL) and World Robot Summit 2020, equivalent to RoboCup World Tournament. Throughout the competitions, we showed that a data-driven approach is effective for performing in-home tasks. Aiming for further development of building a versatile and fast-adaptable system, in RoboCup @Home 2023, we unify three technologies that have recently been evaluated as components in the fields of deep learning and robot learning into a real household robot system. In addition, to stimulate research all over the RoboCup@Home community, we build a platform that manages data collected from each site belonging to the community around the world, taking advantage of the characteristics of the community.
Self-Recovery Prompting: Promptable General Purpose Service Robot System with Foundation Models and Self-Recovery
Sep 27, 2023



A general-purpose service robot (GPSR), which can execute diverse tasks in various environments, requires a system with high generalizability and adaptability to tasks and environments. In this paper, we first developed a top-level GPSR system for worldwide competition (RoboCup@Home 2023) based on multiple foundation models. This system is both generalizable to variations and adaptive by prompting each model. Then, by analyzing the performance of the developed system, we found three types of failure in more realistic GPSR application settings: insufficient information, incorrect plan generation, and plan execution failure. We then propose the self-recovery prompting pipeline, which explores the necessary information and modifies its prompts to recover from failure. We experimentally confirm that the system with the self-recovery mechanism can accomplish tasks by resolving various failure cases. Supplementary videos are available at https://sites.google.com/view/srgpsr .
GenDOM: Generalizable One-shot Deformable Object Manipulation with Parameter-Aware Policy
Sep 19, 2023Due to the inherent uncertainty in their deformability during motion, previous methods in deformable object manipulation, such as rope and cloth, often required hundreds of real-world demonstrations to train a manipulation policy for each object, which hinders their applications in our ever-changing world. To address this issue, we introduce GenDOM, a framework that allows the manipulation policy to handle different deformable objects with only a single real-world demonstration. To achieve this, we augment the policy by conditioning it on deformable object parameters and training it with a diverse range of simulated deformable objects so that the policy can adjust actions based on different object parameters. At the time of inference, given a new object, GenDOM can estimate the deformable object parameters with only a single real-world demonstration by minimizing the disparity between the grid density of point clouds of real-world demonstrations and simulations in a differentiable physics simulator. Empirical validations on both simulated and real-world object manipulation setups clearly show that our method can manipulate different objects with a single demonstration and significantly outperforms the baseline in both environments (a 62% improvement for in-domain ropes and a 15% improvement for out-of-distribution ropes in simulation, as well as a 26% improvement for ropes and a 50% improvement for cloths in the real world), demonstrating the effectiveness of our approach in one-shot deformable object manipulation.