 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRReP: Mixed Reality-based Hand-drawn Reference Path Editing Interface for Mobile Robot Navigation
Mar 31, 2026Autonomous mobile robots operating in human-shared indoor environments often require paths that reflect human spatial intentions, such as avoiding interference with pedestrian flow or maintaining comfortable clearance. However, conventional path planners primarily optimize geometric costs and provide limited support for explicit route specification by human operators. This paper presents MRReP, a Mixed Reality-based interface that enables users to draw a Hand-drawn Reference Path (HRP) directly on the physical floor using hand gestures. The drawn HRP is integrated into the robot navigation stack through a custom Hand-drawn Reference Path Planner, which converts the user-specified point sequence into a global path for autonomous navigation. We evaluated MRReP in a within-subject experiment against a conventional 2D baseline interface. The results demonstrated that MRReP enhanced path specification accuracy, usability, and perceived workload, while enabling more stable path specification in the physical environment. These findings suggest that direct path specification in MR is an effective approach for incorporating human spatial intention into mobile robot navigation. Additional material is available at https://mertcookimg.github.io/mrrep
MR-UBi: Mixed Reality-Based Underwater Robot Arm Teleoperation System with Reaction Torque Indicator via Bilateral Control
Oct 23, 2025We present a mixed reality-based underwater robot arm teleoperation system with a reaction torque indicator via bilateral control (MR-UBi). The reaction torque indicator (RTI) overlays a color and length-coded torque bar in the MR-HMD, enabling seamless integration of visual and haptic feedback during underwater robot arm teleoperation. User studies with sixteen participants compared MR-UBi against a bilateral-control baseline. MR-UBi significantly improved grasping-torque control accuracy, increasing the time within the optimal torque range and reducing both low and high grasping torque range during lift and pick-and-place tasks with objects of different stiffness. Subjective evaluations further showed higher usability (SUS) and lower workload (NASA--TLX). Overall, the results confirm that \textit{MR-UBi} enables more stable, accurate, and user-friendly underwater robot-arm teleoperation through the integration of visual and haptic feedback. For additional material, please check: https://mertcookimg.github.io/mr-ubi
Bi-LAT: Bilateral Control-Based Imitation Learning via Natural Language and Action Chunking with Transformers
Apr 02, 2025We present Bi-LAT, a novel imitation learning framework that unifies bilateral control with natural language processing to achieve precise force modulation in robotic manipulation. Bi-LAT leverages joint position, velocity, and torque data from leader-follower teleoperation while also integrating visual and linguistic cues to dynamically adjust applied force. By encoding human instructions such as "softly grasp the cup" or "strongly twist the sponge" through a multimodal Transformer-based model, Bi-LAT learns to distinguish nuanced force requirements in real-world tasks. We demonstrate Bi-LAT's performance in (1) unimanual cup-stacking scenario where the robot accurately modulates grasp force based on language commands, and (2) bimanual sponge-twisting task that requires coordinated force control. Experimental results show that Bi-LAT effectively reproduces the instructed force levels, particularly when incorporating SigLIP among tested language encoders. Our findings demonstrate the potential of integrating natural language cues into imitation learning, paving the way for more intuitive and adaptive human-robot interaction. For additional material, please visit: https://mertcookimg.github.io/bi-lat/
MRHaD: Mixed Reality-based Hand-Drawn Map Editing Interface for Mobile Robot Navigation
Apr 01, 2025Mobile robot navigation systems are increasingly relied upon in dynamic and complex environments, yet they often struggle with map inaccuracies and the resulting inefficient path planning. This paper presents MRHaD, a Mixed Reality-based Hand-drawn Map Editing Interface that enables intuitive, real-time map modifications through natural hand gestures. By integrating the MR head-mounted display with the robotic navigation system, operators can directly create hand-drawn restricted zones (HRZ), thereby bridging the gap between 2D map representations and the real-world environment. Comparative experiments against conventional 2D editing methods demonstrate that MRHaD significantly improves editing efficiency, map accuracy, and overall usability, contributing to safer and more efficient mobile robot operations. The proposed approach provides a robust technical foundation for advancing human-robot collaboration and establishing innovative interaction models that enhance the hybrid future of robotics and human society. For additional material, please check: https://mertcookimg.github.io/mrhad/
ALPHA-$α$ and Bi-ACT Are All You Need: Importance of Position and Force Information/Control for Imitation Learning of Unimanual and Bimanual Robotic Manipulation with Low-Cost System
Nov 15, 2024

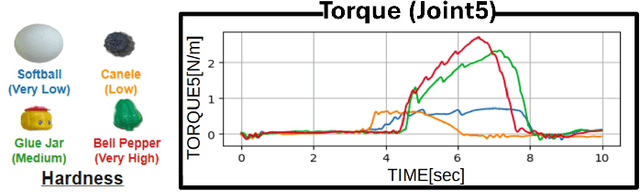
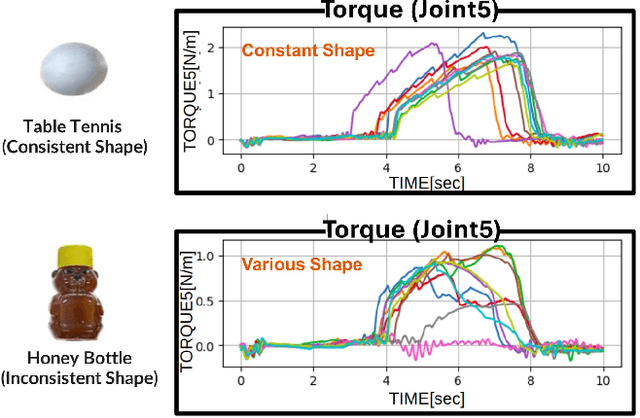
Autonomous manipulation in everyday tasks requires flexible action generation to handle complex, diverse real-world environments, such as objects with varying hardness and softness. Imitation Learning (IL) enables robots to learn complex tasks from expert demonstrations. However, a lot of existing methods rely on position/unilateral control, leaving challenges in tasks that require force information/control, like carefully grasping fragile or varying-hardness objects. As the need for diverse controls increases, there are demand for low-cost bimanual robots that consider various motor inputs. To address these challenges, we introduce Bilateral Control-Based Imitation Learning via Action Chunking with Transformers(Bi-ACT) and"A" "L"ow-cost "P"hysical "Ha"rdware Considering Diverse Motor Control Modes for Research in Everyday Bimanual Robotic Manipulation (ALPHA-$\alpha$). Bi-ACT leverages bilateral control to utilize both position and force information, enhancing the robot's adaptability to object characteristics such as hardness, shape, and weight. The concept of ALPHA-$\alpha$ is affordability, ease of use, repairability, ease of assembly, and diverse control modes (position, velocity, torque), allowing researchers/developers to freely build control systems using ALPHA-$\alpha$. In our experiments, we conducted a detailed analysis of Bi-ACT in unimanual manipulation tasks, confirming its superior performance and adaptability compared to Bi-ACT without force control. Based on these results, we applied Bi-ACT to bimanual manipulation tasks. Experimental results demonstrated high success rates in coordinated bimanual operations across multiple tasks. The effectiveness of the Bi-ACT and ALPHA-$\alpha$ can be seen through comprehensive real-world experiments. Video available at: https://mertcookimg.github.io/alpha-biact/
DABI: Evaluation of Data Augmentation Methods Using Downsampling in Bilateral Control-Based Imitation Learning with Images
Oct 06, 2024



Autonomous robot manipulation is a complex and continuously evolving robotics field. This paper focuses on data augmentation methods in imitation learning. Imitation learning consists of three stages: data collection from experts, learning model, and execution. However, collecting expert data requires manual effort and is time-consuming. Additionally, as sensors have different data acquisition intervals, preprocessing such as downsampling to match the lowest frequency is necessary. Downsampling enables data augmentation and also contributes to the stabilization of robot operations. In light of this background, this paper proposes the Data Augmentation Method for Bilateral Control-Based Imitation Learning with Images, called "DABI". DABI collects robot joint angles, velocities, and torques at 1000 Hz, and uses images from gripper and environmental cameras captured at 100 Hz as the basis for data augmentation. This enables a tenfold increase in data. In this paper, we collected just 5 expert demonstration datasets. We trained the bilateral control Bi-ACT model with the unaltered dataset and two augmentation methods for comparative experiments and conducted real-world experiments. The results confirmed a significant improvement in success rates, thereby proving the effectiveness of DABI. For additional material, please check https://mertcookimg.github.io/dabi
BSL: Navigation Method Considering Blind Spots Based on ROS Navigation Stack and Blind Spots Layer for Mobile Robot
May 09, 2024



This paper proposes a navigation method considering blind spots based on the robot operating system (ROS) navigation stack and blind spots layer (BSL) for a wheeled mobile robot. In this paper, environmental information is recognized using a laser range finder (LRF) and RGB-D cameras. Blind spots occur when corners or obstacles are present in the environment, and may lead to collisions if a human or object moves toward the robot from these blind spots. To prevent such collisions, this paper proposes a navigation method considering blind spots based on the local cost map layer of the BSL for the wheeled mobile robot. Blind spots are estimated by utilizing environmental data collected through RGB-D cameras. The navigation method that takes these blind spots into account is achieved through the implementation of the BSL and a local path planning method that employs an enhanced cost function of dynamic window approach. The effectiveness of the proposed method was further demonstrated through simulations and experiments.
MRNaB: Mixed Reality-based Robot Navigation Interface using Optical-see-through MR-beacon
Mar 28, 2024Recent advancements in robotics have led to the development of numerous interfaces to enhance the intuitiveness of robot navigation. However, the reliance on traditional 2D displays imposes limitations on the simultaneous visualization of information. Mixed Reality (MR) technology addresses this issue by enhancing the dimensionality of information visualization, allowing users to perceive multiple pieces of information concurrently. This paper proposes Mixed reality-based robot navigation interface using an optical-see-through MR-beacon (MRNaB), a novel approach that incorporates an MR-beacon, situated atop the real-world environment, to function as a signal transmitter for robot navigation. This MR-beacon is designed to be persistent, eliminating the need for repeated navigation inputs for the same location. Our system is mainly constructed into four primary functions: "Add", "Move", "Delete", and "Select". These allow for the addition of a MR-beacon, location movement, its deletion, and the selection of MR-beacon for navigation purposes, respectively. The effectiveness of the proposed method was then validated through experiments by comparing it with the traditional 2D system. As the result, MRNaB was proven to increase the performance of the user when doing navigation to a certain place subjectively and objectively. For additional material, please check: https://mertcookimg.github.io/mrnab
ILBiT: Imitation Learning for Robot Using Position and Torque Information based on Bilateral Control with Transformer
Feb 05, 2024Autonomous manipulation in robot arms is a complex and evolving field of study in robotics. This paper introduces an innovative approach to this challenge by focusing on imitation learning (IL). Unlike traditional imitation methods, our approach uses IL based on bilateral control, allowing for more precise and adaptable robot movements. The conventional IL based on bilateral control method have relied on Long Short-Term Memory (LSTM) networks. In this paper, we present the IL for robot using position and torque information based on Bilateral control with Transformer (ILBiT). This proposed method employs the Transformer model, known for its robust performance in handling diverse datasets and its capability to surpass LSTM's limitations, especially in tasks requiring detailed force adjustments. A standout feature of ILBiT is its high-frequency operation at 100 Hz, which significantly improves the system's adaptability and response to varying environments and objects of different hardness levels. The effectiveness of the Transformer-based ILBiT method can be seen through comprehensive real-world experiments.
Bi-ACT: Bilateral Control-Based Imitation Learning via Action Chunking with Transformer
Jan 31, 2024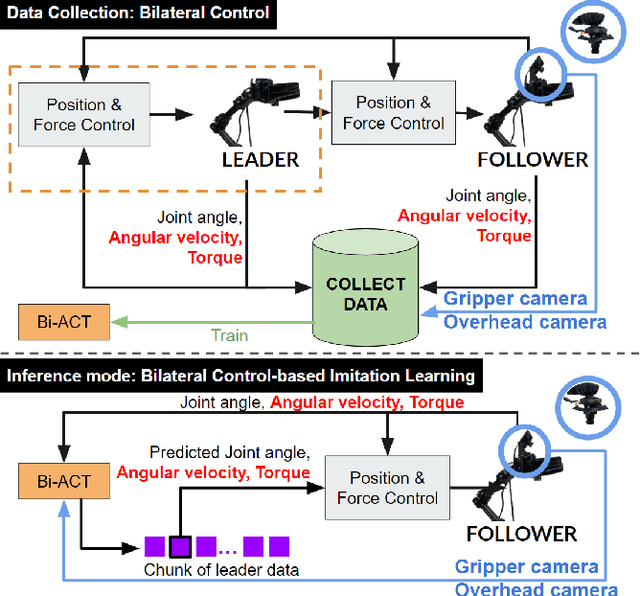

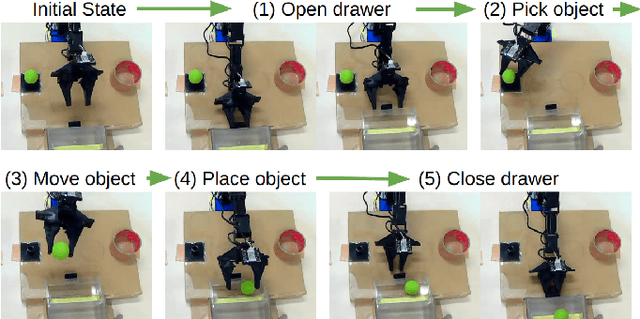
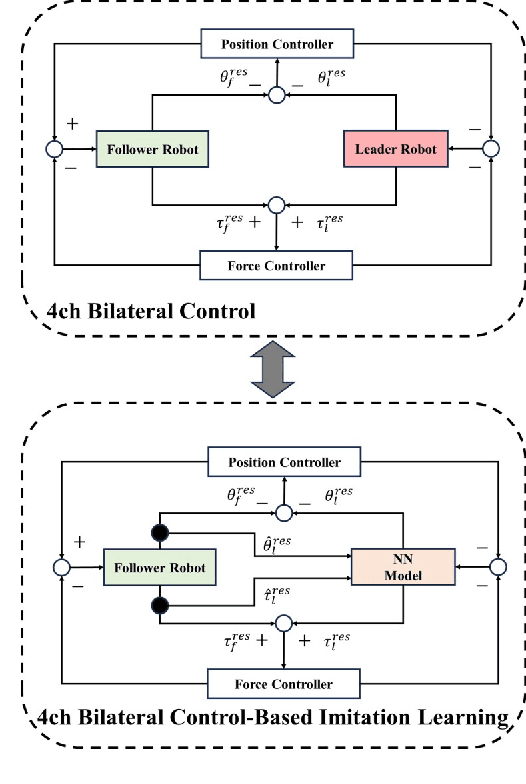
Autonomous manipulation in robot arms is a complex and evolving field of study in robotics. This paper proposes work stands at the intersection of two innovative approaches in the field of robotics and machine learning. Inspired by the Action Chunking with Transformer (ACT) model, which employs joint location and image data to predict future movements, our work integrates principles of Bilateral Control-Based Imitation Learning to enhance robotic control. Our objective is to synergize these techniques, thereby creating a more robust and efficient control mechanism. In our approach, the data collected from the environment are images from the gripper and overhead cameras, along with the joint angles, angular velocities, and forces of the follower robot using bilateral control. The model is designed to predict the subsequent steps for the joint angles, angular velocities, and forces of the leader robot. This predictive capability is crucial for implementing effective bilateral control in the follower robot, allowing for more nuanced and responsive maneuvering.