 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRNaB: Mixed Reality-based Robot Navigation Interface using Optical-see-through MR-beacon
Mar 28, 2024Recent advancements in robotics have led to the development of numerous interfaces to enhance the intuitiveness of robot navigation. However, the reliance on traditional 2D displays imposes limitations on the simultaneous visualization of information. Mixed Reality (MR) technology addresses this issue by enhancing the dimensionality of information visualization, allowing users to perceive multiple pieces of information concurrently. This paper proposes Mixed reality-based robot navigation interface using an optical-see-through MR-beacon (MRNaB), a novel approach that incorporates an MR-beacon, situated atop the real-world environment, to function as a signal transmitter for robot navigation. This MR-beacon is designed to be persistent, eliminating the need for repeated navigation inputs for the same location. Our system is mainly constructed into four primary functions: "Add", "Move", "Delete", and "Select". These allow for the addition of a MR-beacon, location movement, its deletion, and the selection of MR-beacon for navigation purposes, respectively. The effectiveness of the proposed method was then validated through experiments by comparing it with the traditional 2D system. As the result, MRNaB was proven to increase the performance of the user when doing navigation to a certain place subjectively and objectively. For additional material, please check: https://mertcookimg.github.io/mrnab
ILBiT: Imitation Learning for Robot Using Position and Torque Information based on Bilateral Control with Transformer
Feb 05, 2024Autonomous manipulation in robot arms is a complex and evolving field of study in robotics. This paper introduces an innovative approach to this challenge by focusing on imitation learning (IL). Unlike traditional imitation methods, our approach uses IL based on bilateral control, allowing for more precise and adaptable robot movements. The conventional IL based on bilateral control method have relied on Long Short-Term Memory (LSTM) networks. In this paper, we present the IL for robot using position and torque information based on Bilateral control with Transformer (ILBiT). This proposed method employs the Transformer model, known for its robust performance in handling diverse datasets and its capability to surpass LSTM's limitations, especially in tasks requiring detailed force adjustments. A standout feature of ILBiT is its high-frequency operation at 100 Hz, which significantly improves the system's adaptability and response to varying environments and objects of different hardness levels. The effectiveness of the Transformer-based ILBiT method can be seen through comprehensive real-world experiments.
Bi-ACT: Bilateral Control-Based Imitation Learning via Action Chunking with Transformer
Jan 31, 2024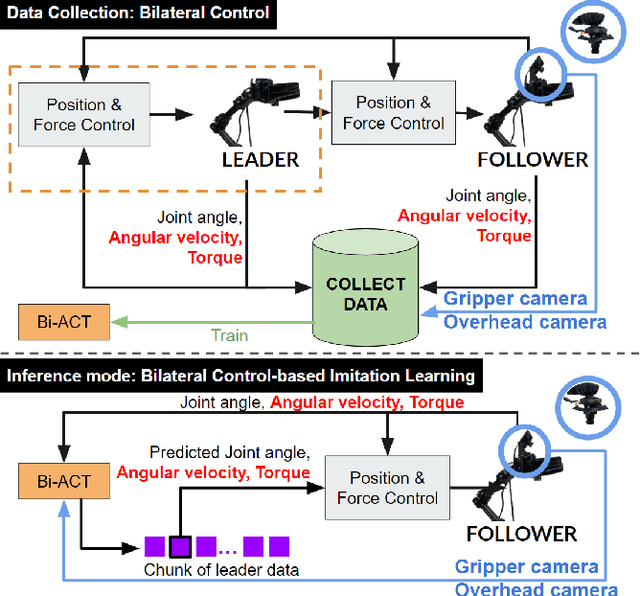

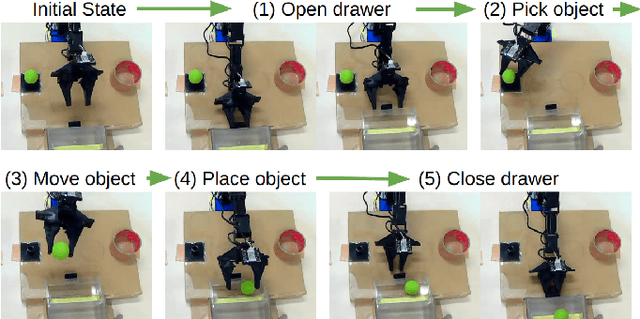
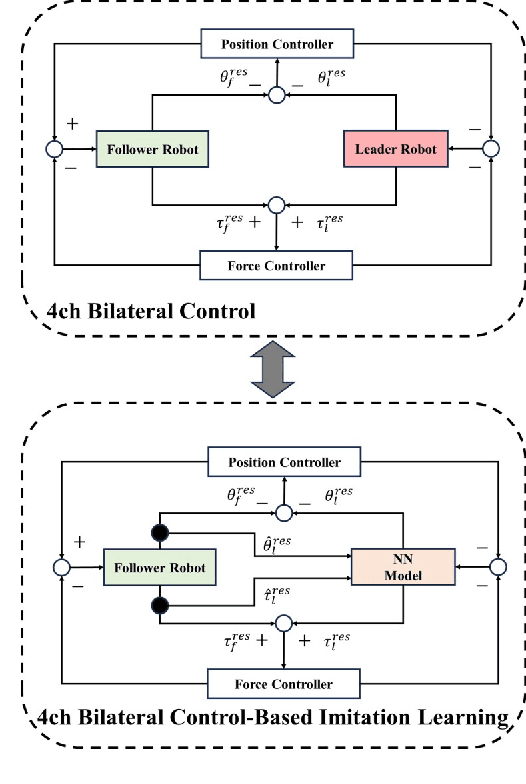
Autonomous manipulation in robot arms is a complex and evolving field of study in robotics. This paper proposes work stands at the intersection of two innovative approaches in the field of robotics and machine learning. Inspired by the Action Chunking with Transformer (ACT) model, which employs joint location and image data to predict future movements, our work integrates principles of Bilateral Control-Based Imitation Learning to enhance robotic control. Our objective is to synergize these techniques, thereby creating a more robust and efficient control mechanism. In our approach, the data collected from the environment are images from the gripper and overhead cameras, along with the joint angles, angular velocities, and forces of the follower robot using bilateral control. The model is designed to predict the subsequent steps for the joint angles, angular velocities, and forces of the leader robot. This predictive capability is crucial for implementing effective bilateral control in the follower robot, allowing for more nuanced and responsive maneuvering.
Panoptic-based Object Style-Align for Image-to-Image Translation
Dec 03, 2021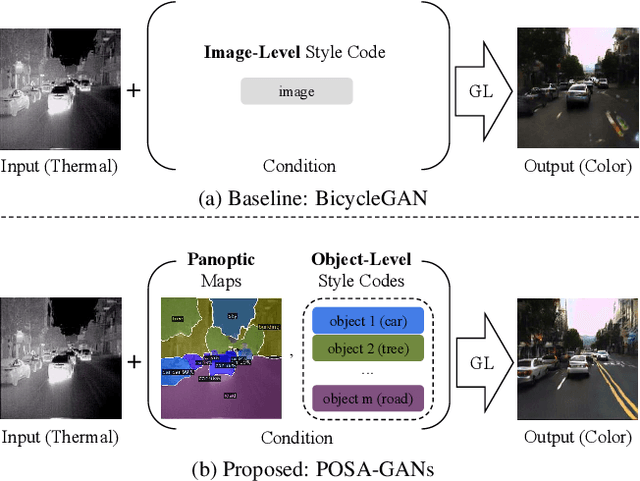

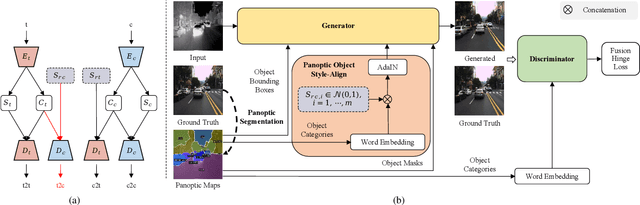
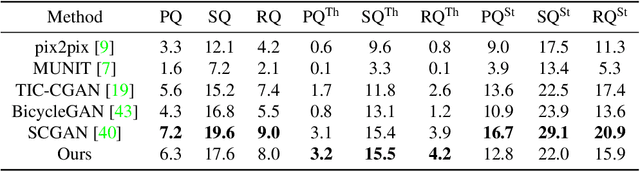
Despite remarkable recent progress in image translation, the complex scene with multiple discrepant objects remains a challenging problem. Because the translated images have low fidelity and tiny objects in fewer details and obtain unsatisfactory performance in object recognition. Without the thorough object perception (i.e., bounding boxes, categories, and masks) of the image as prior knowledge, the style transformation of each object will be difficult to track in the image translation process. We propose panoptic-based object style-align generative adversarial networks (POSA-GANs) for image-to-image translation together with a compact panoptic segmentation dataset. The panoptic segmentation model is utilized to extract panoptic-level perception (i.e., overlap-removed foreground object instances and background semantic regions in the image). This is utilized to guide the alignment between the object content codes of the input domain image and object style codes sampled from the style space of the target domain. The style-aligned object representations are further transformed to obtain precise boundaries layout for higher fidelity object generation. The proposed method was systematically compared with different competing methods and obtained significant improvement on both image quality and object recognition performance for translated images.
Transferring Domain-Agnostic Knowledge in Video Question Answering
Oct 26, 2021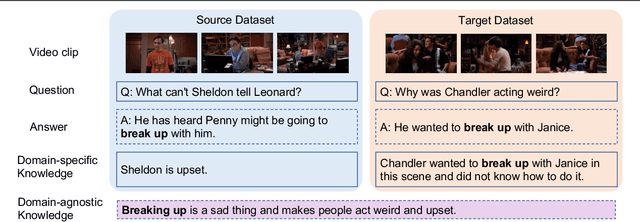
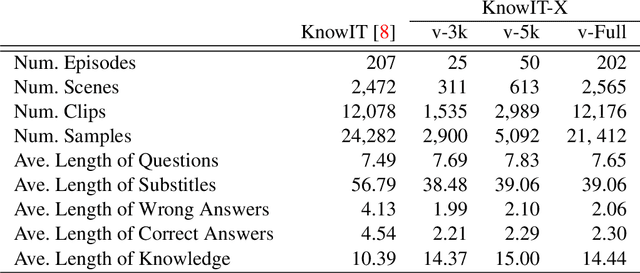
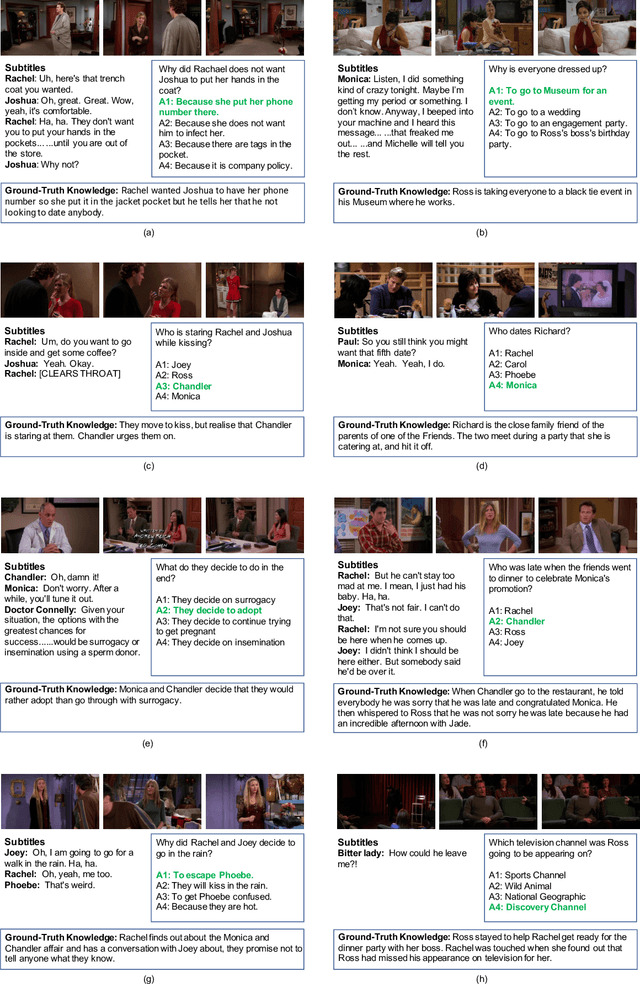
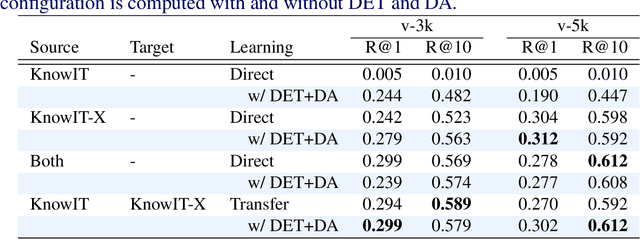
Video question answering (VideoQA) is designed to answer a given question based on a relevant video clip. The current available large-scale datasets have made it possible to formulate VideoQA as the joint understanding of visual and language information. However, this training procedure is costly and still less competent with human performance. In this paper, we investigate a transfer learning method by the introduction of domain-agnostic knowledge and domain-specific knowledge. First, we develop a novel transfer learning framework, which finetunes the pre-trained model by applying domain-agnostic knowledge as the medium. Second, we construct a new VideoQA dataset with 21,412 human-generated question-answer samples for comparable transfer of knowledge. Our experiments show that: (i) domain-agnostic knowledge is transferable and (ii) our proposed transfer learning framework can boost VideoQA performance effectively.
REST: Real-to-Synthetic Transform for Illumination Invariant Camera Localization
Mar 26, 2018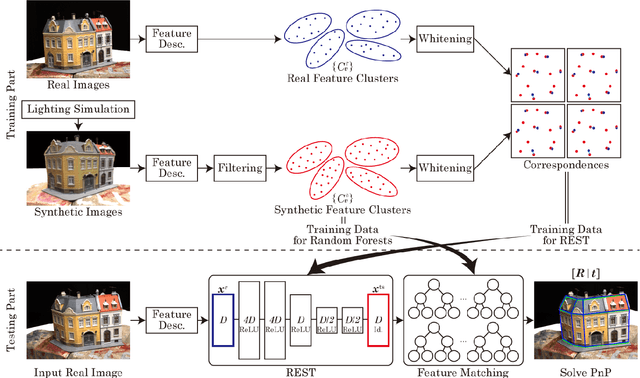
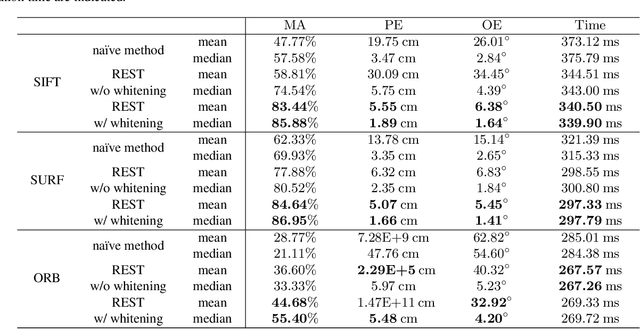

Accurate camera localization is an essential part of tracking systems. However, localization results are greatly affected by illumination. Including data collected under various lighting conditions can improve the robustness of the localization algorithm to lighting variation. However, this is very tedious and time consuming. By using synthesized images it is possible to easily accumulate a large variety of views under varying illumination and weather conditions. Despite continuously improving processing power and rendering algorithms, synthesized images do not perfectly match real images of the same scene, i.e. there exists a gap between real and synthesized images that also affects the accuracy of camera localization. To reduce the impact of this gap, we introduce "REal-to-Synthetic Transform (REST)." REST is an autoencoder-like network that converts real features to their synthetic counterpart. The converted features can then be matched against the accumulated database for robust camera localization. In our experiments REST improved feature matching accuracy under variable lighting conditions by approximately 30%. Moreover, our system outperforms state of the art CNN-based camera localization methods trained with synthetic images. We believe our method could be used to initialize local tracking and to simplify data accumulation for lighting robust localization.