 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoptic-based Object Style-Align for Image-to-Image Translation
Dec 03, 2021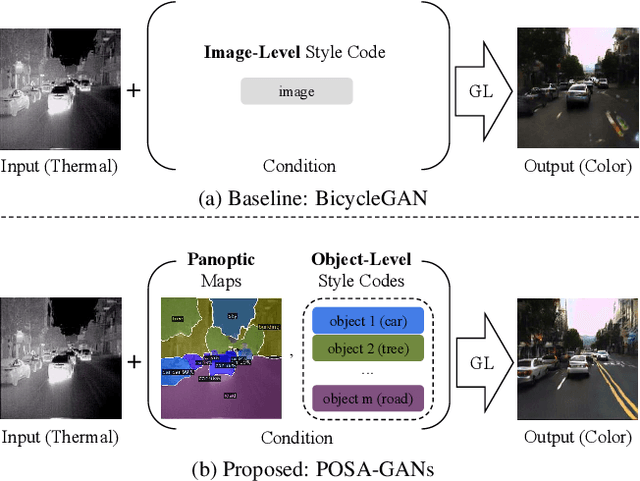

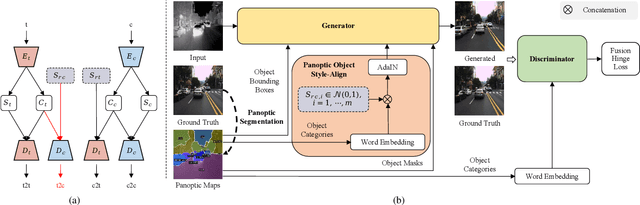
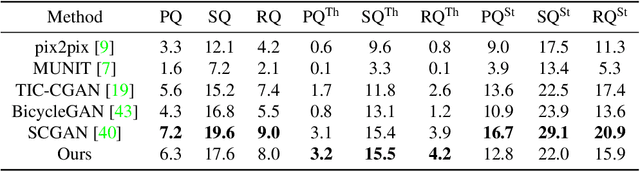
Despite remarkable recent progress in image translation, the complex scene with multiple discrepant objects remains a challenging problem. Because the translated images have low fidelity and tiny objects in fewer details and obtain unsatisfactory performance in object recognition. Without the thorough object perception (i.e., bounding boxes, categories, and masks) of the image as prior knowledge, the style transformation of each object will be difficult to track in the image translation process. We propose panoptic-based object style-align generative adversarial networks (POSA-GANs) for image-to-image translation together with a compact panoptic segmentation dataset. The panoptic segmentation model is utilized to extract panoptic-level perception (i.e., overlap-removed foreground object instances and background semantic regions in the image). This is utilized to guide the alignment between the object content codes of the input domain image and object style codes sampled from the style space of the target domain. The style-aligned object representations are further transformed to obtain precise boundaries layout for higher fidelity object generation. The proposed method was systematically compared with different competing methods and obtained significant improvement on both image quality and object recognition performance for translated images.
REST: Real-to-Synthetic Transform for Illumination Invariant Camera Localization
Mar 26, 2018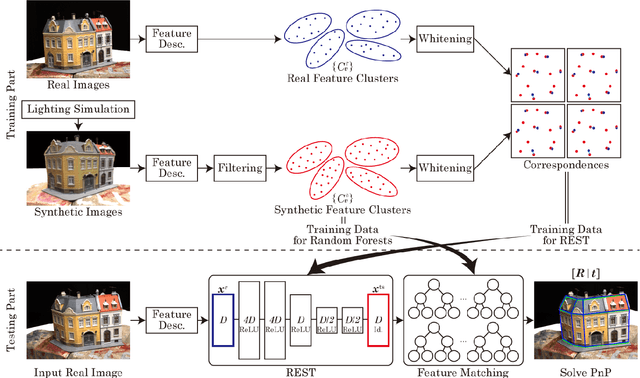
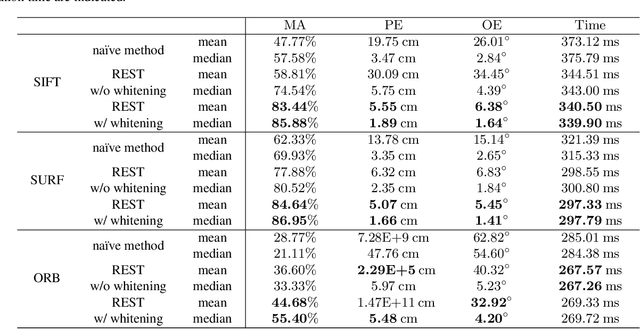
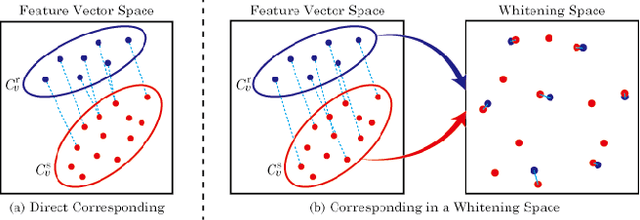

Accurate camera localization is an essential part of tracking systems. However, localization results are greatly affected by illumination. Including data collected under various lighting conditions can improve the robustness of the localization algorithm to lighting variation. However, this is very tedious and time consuming. By using synthesized images it is possible to easily accumulate a large variety of views under varying illumination and weather conditions. Despite continuously improving processing power and rendering algorithms, synthesized images do not perfectly match real images of the same scene, i.e. there exists a gap between real and synthesized images that also affects the accuracy of camera localization. To reduce the impact of this gap, we introduce "REal-to-Synthetic Transform (REST)." REST is an autoencoder-like network that converts real features to their synthetic counterpart. The converted features can then be matched against the accumulated database for robust camera localization. In our experiments REST improved feature matching accuracy under variable lighting conditions by approximately 30%. Moreover, our system outperforms state of the art CNN-based camera localization methods trained with synthetic images. We believe our method could be used to initialize local tracking and to simplify data accumulation for lighting robust localization.