 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DGesPolicy: Phoneme-Aware Holistic Co-Speech Gesture Generation Based on Action Control
Jan 26, 2026Generating holistic co-speech gestures that integrate full-body motion with facial expressions suffers from semantically incoherent coordination on body motion and spatially unstable meaningless movements due to existing part-decomposed or frame-level regression methods, We introduce 3DGesPolicy, a novel action-based framework that reformulates holistic gesture generation as a continuous trajectory control problem through diffusion policy from robotics. By modeling frame-to-frame variations as unified holistic actions, our method effectively learns inter-frame holistic gesture motion patterns and ensures both spatially and semantically coherent movement trajectories that adhere to realistic motion manifolds. To further bridge the gap in expressive alignment, we propose a Gesture-Audio-Phoneme (GAP) fusion module that can deeply integrate and refine multi-modal signals, ensuring structured and fine-grained alignment between speech semantics, body motion, and facial expressions. Extensive quantitative and qualitative experiments on the BEAT2 dataset demonstrate the effectiveness of our 3DGesPolicy across other state-of-the-art methods in generating natural, expressive, and highly speech-aligned holistic gestures.
3DFacePolicy: Speech-Driven 3D Facial Animation with Diffusion Policy
Sep 17, 2024Audio-driven 3D facial animation has made immersive progress both in research and application developments. The newest approaches focus on Transformer-based methods and diffusion-based methods, however, there is still gap in the vividness and emotional expression between the generated animation and real human face. To tackle this limitation, we propose 3DFacePolicy, a diffusion policy model for 3D facial animation prediction. This method generates variable and realistic human facial movements by predicting the 3D vertex trajectory on the 3D facial template with diffusion policy instead of facial generation for every frame. It takes audio and vertex states as observations to predict the vertex trajectory and imitate real human facial expressions, which keeps the continuous and natural flow of human emotions. The experiments show that our approach is effective in variable and dynamic facial motion synthesizing.
It's DONE: Direct ONE-shot learning without training optimization
Apr 28, 2022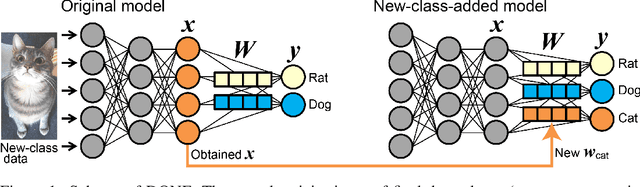



Learning a new concept from one example is a superior function of human brain and it is drawing attention in the field of machine learning as one-shot learning task. In this paper, we propose the simplest method for this task, named Direct ONE-shot learning (DONE). DONE adds a new class to a pretrained deep neural network (DNN) classifier with neither training optimization nor other-classes modification. DONE is inspired by Hebbian theory and directly uses the neural activity input of the final dense layer obtained from a data that belongs to the new additional class as the connectivity weight (synaptic strength) with a newly-provided-output neuron for the new class. DONE requires just one inference for obtaining the output of the final dense layer and its procedure is simple, deterministic, not requiring parameter tuning and hyperparameters. The performance of DONE depends entirely on the pretrained DNN model used as a backbone model, and we confirmed that DONE with a well-trained backbone model performs a practical-level accuracy. DONE has some advantages including a DNN's practical use that is difficult to spend high cost for a training, an evaluation of existing DNN models, and the understanding of the brain. DONE might be telling us one-shot learning is an easy task that can be achieved by a simple principle not only for humans but also for current well-trained DNN models.
REST: Real-to-Synthetic Transform for Illumination Invariant Camera Localization
Mar 26, 2018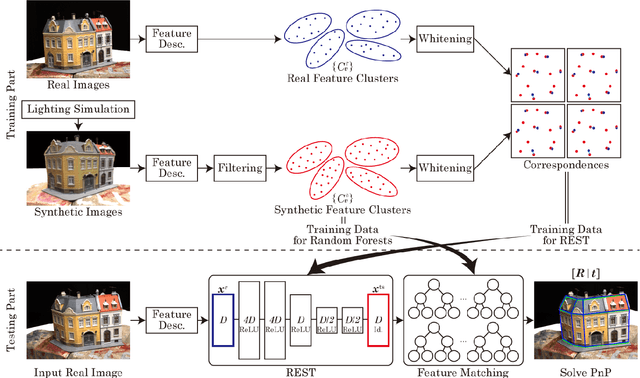
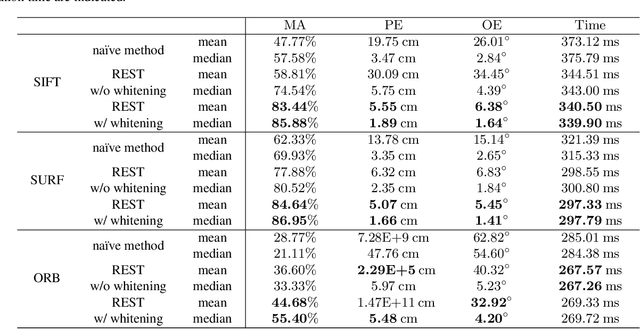
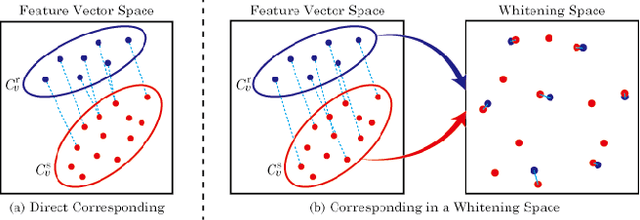

Accurate camera localization is an essential part of tracking systems. However, localization results are greatly affected by illumination. Including data collected under various lighting conditions can improve the robustness of the localization algorithm to lighting variation. However, this is very tedious and time consuming. By using synthesized images it is possible to easily accumulate a large variety of views under varying illumination and weather conditions. Despite continuously improving processing power and rendering algorithms, synthesized images do not perfectly match real images of the same scene, i.e. there exists a gap between real and synthesized images that also affects the accuracy of camera localization. To reduce the impact of this gap, we introduce "REal-to-Synthetic Transform (REST)." REST is an autoencoder-like network that converts real features to their synthetic counterpart. The converted features can then be matched against the accumulated database for robust camera localization. In our experiments REST improved feature matching accuracy under variable lighting conditions by approximately 30%. Moreover, our system outperforms state of the art CNN-based camera localization methods trained with synthetic images. We believe our method could be used to initialize local tracking and to simplify data accumulation for lighting robust localization.