 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoptic-based Object Style-Align for Image-to-Image Translation
Dec 03, 2021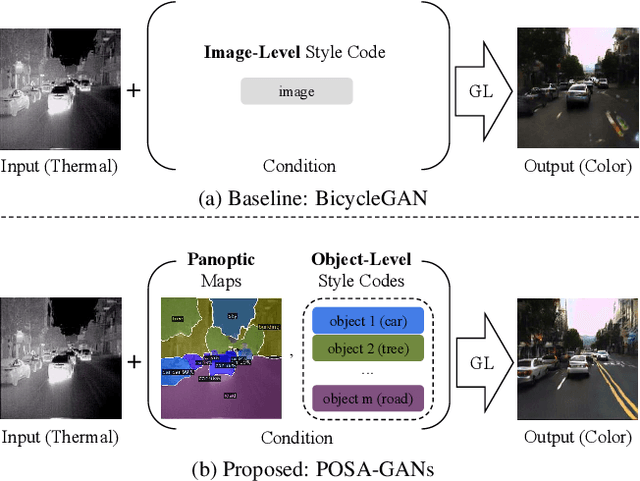

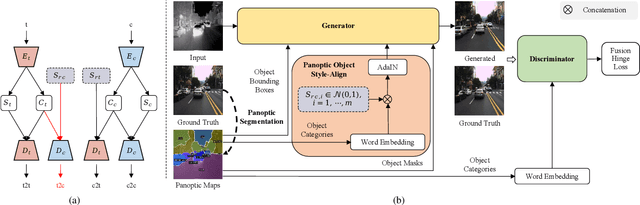
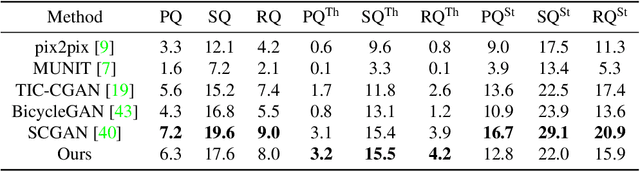
Despite remarkable recent progress in image translation, the complex scene with multiple discrepant objects remains a challenging problem. Because the translated images have low fidelity and tiny objects in fewer details and obtain unsatisfactory performance in object recognition. Without the thorough object perception (i.e., bounding boxes, categories, and masks) of the image as prior knowledge, the style transformation of each object will be difficult to track in the image translation process. We propose panoptic-based object style-align generative adversarial networks (POSA-GANs) for image-to-image translation together with a compact panoptic segmentation dataset. The panoptic segmentation model is utilized to extract panoptic-level perception (i.e., overlap-removed foreground object instances and background semantic regions in the image). This is utilized to guide the alignment between the object content codes of the input domain image and object style codes sampled from the style space of the target domain. The style-aligned object representations are further transformed to obtain precise boundaries layout for higher fidelity object generation. The proposed method was systematically compared with different competing methods and obtained significant improvement on both image quality and object recognition performance for translated images.