 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuspicion-Agent: Playing Imperfect Information Games with Theory of Mind Aware GPT-4
Oct 06, 2023Unlike perfect information games, where all elements are known to every player, imperfect information games emulate the real-world complexities of decision-making under uncertain or incomplete information. GPT-4, the recent breakthrough in large language models (LLMs) trained on massive passive data, is notable for its knowledge retrieval and reasoning abilities. This paper delves into the applicability of GPT-4's learned knowledge for imperfect information games. To achieve this, we introduce \textbf{Suspicion-Agent}, an innovative agent that leverages GPT-4's capabilities for performing in imperfect information games. With proper prompt engineering to achieve different functions, Suspicion-Agent based on GPT-4 demonstrates remarkable adaptability across a range of imperfect information card games. Importantly, GPT-4 displays a strong high-order theory of mind (ToM) capacity, meaning it can understand others and intentionally impact others' behavior. Leveraging this, we design a planning strategy that enables GPT-4 to competently play against different opponents, adapting its gameplay style as needed, while requiring only the game rules and descriptions of observations as input. In the experiments, we qualitatively showcase the capabilities of Suspicion-Agent across three different imperfect information games and then quantitatively evaluate it in Leduc Hold'em. The results show that Suspicion-Agent can potentially outperform traditional algorithms designed for imperfect information games, without any specialized training or examples. In order to encourage and foster deeper insights within the community, we make our game-related data publicly available.
GenDOM: Generalizable One-shot Deformable Object Manipulation with Parameter-Aware Policy
Sep 19, 2023Due to the inherent uncertainty in their deformability during motion, previous methods in deformable object manipulation, such as rope and cloth, often required hundreds of real-world demonstrations to train a manipulation policy for each object, which hinders their applications in our ever-changing world. To address this issue, we introduce GenDOM, a framework that allows the manipulation policy to handle different deformable objects with only a single real-world demonstration. To achieve this, we augment the policy by conditioning it on deformable object parameters and training it with a diverse range of simulated deformable objects so that the policy can adjust actions based on different object parameters. At the time of inference, given a new object, GenDOM can estimate the deformable object parameters with only a single real-world demonstration by minimizing the disparity between the grid density of point clouds of real-world demonstrations and simulations in a differentiable physics simulator. Empirical validations on both simulated and real-world object manipulation setups clearly show that our method can manipulate different objects with a single demonstration and significantly outperforms the baseline in both environments (a 62% improvement for in-domain ropes and a 15% improvement for out-of-distribution ropes in simulation, as well as a 26% improvement for ropes and a 50% improvement for cloths in the real world), demonstrating the effectiveness of our approach in one-shot deformable object manipulation.
GenORM: Generalizable One-shot Rope Manipulation with Parameter-Aware Policy
Jun 20, 2023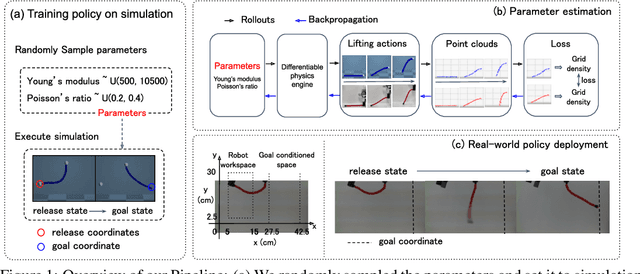
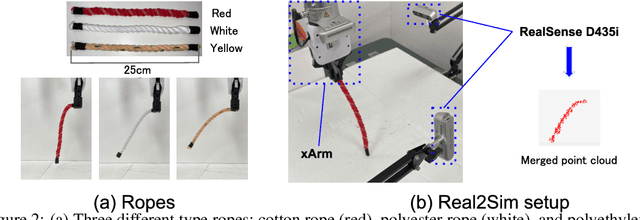
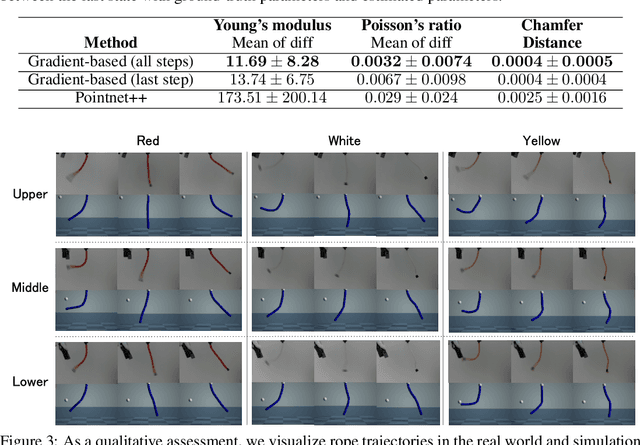
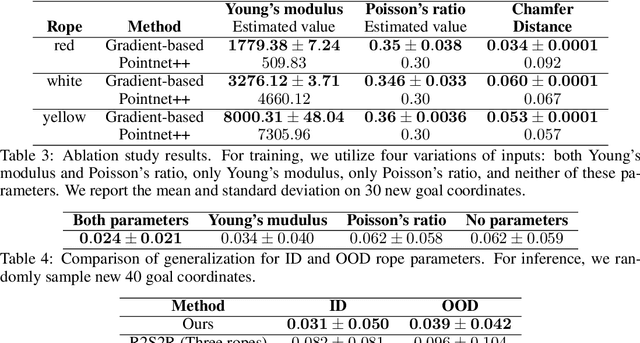
Due to the inherent uncertainty in their deformability during motion, previous methods in rope manipulation often require hundreds of real-world demonstrations to train a manipulation policy for each rope, even for simple tasks such as rope goal reaching, which hinder their applications in our ever-changing world. To address this issue, we introduce GenORM, a framework that allows the manipulation policy to handle different deformable ropes with a single real-world demonstration. To achieve this, we augment the policy by conditioning it on deformable rope parameters and training it with a diverse range of simulated deformable ropes so that the policy can adjust actions based on different rope parameters. At the time of inference, given a new rope, GenORM estimates the deformable rope parameters by minimizing the disparity between the grid density of point clouds of real-world demonstrations and simulations. With the help of a differentiable physics simulator, we require only a single real-world demonstration. Empirical validations on both simulated and real-world rope manipulation setups clearly show that our method can manipulate different ropes with a single demonstration and significantly outperforms the baseline in both environments (62% improvement in in-domain ropes, and 15% improvement in out-of-distribution ropes in simulation, 26% improvement in real-world), demonstrating the effectiveness of our approach in one-shot rope manipulation.
DreamSparse: Escaping from Plato's Cave with 2D Frozen Diffusion Model Given Sparse Views
Jun 16, 2023



Synthesizing novel view images from a few views is a challenging but practical problem. Existing methods often struggle with producing high-quality results or necessitate per-object optimization in such few-view settings due to the insufficient information provided. In this work, we explore leveraging the strong 2D priors in pre-trained diffusion models for synthesizing novel view images. 2D diffusion models, nevertheless, lack 3D awareness, leading to distorted image synthesis and compromising the identity. To address these problems, we propose DreamSparse, a framework that enables the frozen pre-trained diffusion model to generate geometry and identity-consistent novel view image. Specifically, DreamSparse incorporates a geometry module designed to capture 3D features from sparse views as a 3D prior. Subsequently, a spatial guidance model is introduced to convert these 3D feature maps into spatial information for the generative process. This information is then used to guide the pre-trained diffusion model, enabling it to generate geometrically consistent images without tuning it. Leveraging the strong image priors in the pre-trained diffusion models, DreamSparse is capable of synthesizing high-quality novel views for both object and scene-level images and generalising to open-set images. Experimental results demonstrate that our framework can effectively synthesize novel view images from sparse views and outperforms baselines in both trained and open-set category images. More results can be found on our project page: https://sites.google.com/view/dreamsparse-webpage.
Paste, Inpaint and Harmonize via Denoising: Subject-Driven Image Editing with Pre-Trained Diffusion Model
Jun 13, 2023Text-to-image generative models have attracted rising attention for flexible image editing via user-specified descriptions. However, text descriptions alone are not enough to elaborate the details of subjects, often compromising the subjects' identity or requiring additional per-subject fine-tuning. We introduce a new framework called \textit{Paste, Inpaint and Harmonize via Denoising} (PhD), which leverages an exemplar image in addition to text descriptions to specify user intentions. In the pasting step, an off-the-shelf segmentation model is employed to identify a user-specified subject within an exemplar image which is subsequently inserted into a background image to serve as an initialization capturing both scene context and subject identity in one. To guarantee the visual coherence of the generated or edited image, we introduce an inpainting and harmonizing module to guide the pre-trained diffusion model to seamlessly blend the inserted subject into the scene naturally. As we keep the pre-trained diffusion model frozen, we preserve its strong image synthesis ability and text-driven ability, thus achieving high-quality results and flexible editing with diverse texts. In our experiments, we apply PhD to both subject-driven image editing tasks and explore text-driven scene generation given a reference subject. Both quantitative and qualitative comparisons with baseline methods demonstrate that our approach achieves state-of-the-art performance in both tasks. More qualitative results can be found at \url{https://sites.google.com/view/phd-demo-page}.
Time-Travel Rephotography
Dec 22, 2020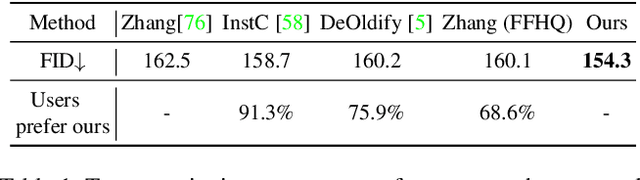
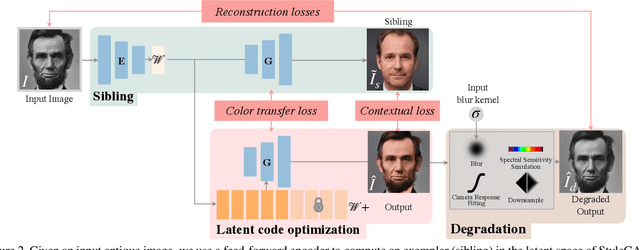


Many historical people are captured only in old, faded, black and white photos, that have been distorted by the limitations of early cameras and the passage of time. This paper simulates traveling back in time with a modern camera to rephotograph famous subjects. Unlike conventional image restoration filters which apply independent operations like denoising, colorization, and superresolution, we leverage the StyleGAN2 framework to project old photos into the space of modern high-resolution photos, achieving all of these effects in a unified framework. A unique challenge with this approach is capturing the identity and pose of the photo's subject and not the many artifacts in low-quality antique photos. Our comparisons to current state-of-the-art restoration filters show significant improvements and compelling results for a variety of important historical people.