 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperAlign: Hypernetwork for Efficient Test-Time Alignment of Diffusion Models
Jan 22, 2026Diffusion models achieve state-of-the-art performance but often fail to generate outputs that align with human preferences and intentions, resulting in images with poor aesthetic quality and semantic inconsistencies. Existing alignment methods present a difficult trade-off: fine-tuning approaches suffer from loss of diversity with reward over-optimization, while test-time scaling methods introduce significant computational overhead and tend to under-optimize. To address these limitations, we propose HyperAlign, a novel framework that trains a hypernetwork for efficient and effective test-time alignment. Instead of modifying latent states, HyperAlign dynamically generates low-rank adaptation weights to modulate the diffusion model's generation operators. This allows the denoising trajectory to be adaptively adjusted based on input latents, timesteps and prompts for reward-conditioned alignment. We introduce multiple variants of HyperAlign that differ in how frequently the hypernetwork is applied, balancing between performance and efficiency. Furthermore, we optimize the hypernetwork using a reward score objective regularized with preference data to reduce reward hacking. We evaluate HyperAlign on multiple extended generative paradigms, including Stable Diffusion and FLUX. It significantly outperforms existing fine-tuning and test-time scaling baselines in enhancing semantic consistency and visual appeal.
Spark Transformer: Reactivating Sparsity in FFN and Attention
Jun 07, 2025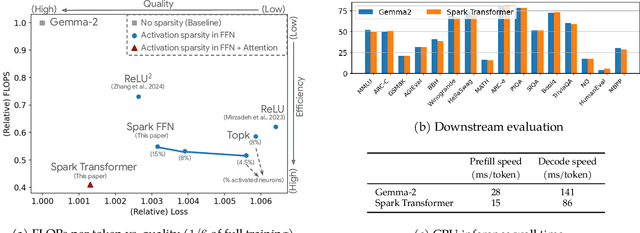
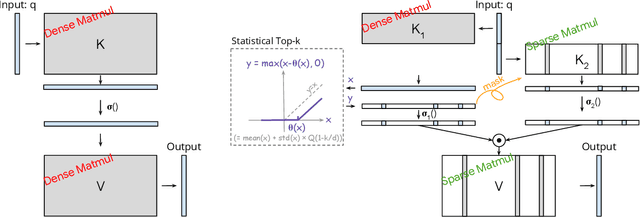
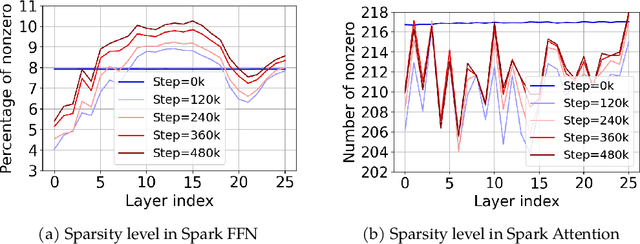
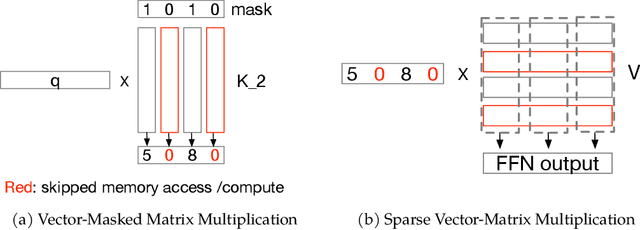
The discovery of the lazy neuron phenomenon in trained Transformers, where the vast majority of neurons in their feed-forward networks (FFN) are inactive for each token, has spurred tremendous interests in activation sparsity for enhancing large model efficiency. While notable progress has been made in translating such sparsity to wall-time benefits, modern Transformers have moved away from the ReLU activation function crucial to this phenomenon. Existing efforts on re-introducing activation sparsity often degrade model quality, increase parameter count, complicate or slow down training. Sparse attention, the application of sparse activation to the attention mechanism, often faces similar challenges. This paper introduces the Spark Transformer, a novel architecture that achieves a high level of activation sparsity in both FFN and the attention mechanism while maintaining model quality, parameter count, and standard training procedures. Our method realizes sparsity via top-k masking for explicit control over sparsity level. Crucially, we introduce statistical top-k, a hardware-accelerator-friendly, linear-time approximate algorithm that avoids costly sorting and mitigates significant training slowdown from standard top-$k$ operators. Furthermore, Spark Transformer reallocates existing FFN parameters and attention key embeddings to form a low-cost predictor for identifying activated entries. This design not only mitigates quality loss from enforced sparsity, but also enhances wall-time benefit. Pretrained with the Gemma-2 recipe, Spark Transformer demonstrates competitive performance on standard benchmarks while exhibiting significant sparsity: only 8% of FFN neurons are activated, and each token attends to a maximum of 256 tokens. This sparsity translates to a 2.5x reduction in FLOPs, leading to decoding wall-time speedups of up to 1.79x on CPU and 1.40x on GPU.
ColorizeDiffusion v2: Enhancing Reference-based Sketch Colorization Through Separating Utilities
Apr 09, 2025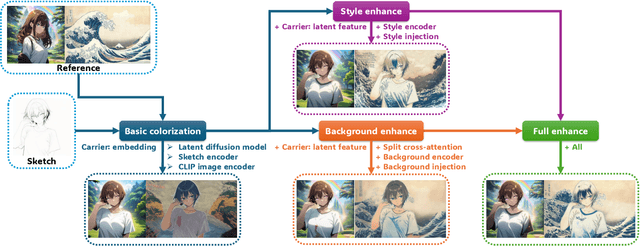


Reference-based sketch colorization methods have garnered significant attention due to their potential applications in the animation production industry. However, most existing methods are trained with image triplets of sketch, reference, and ground truth that are semantically and spatially well-aligned, while real-world references and sketches often exhibit substantial misalignment. This mismatch in data distribution between training and inference leads to overfitting, consequently resulting in spatial artifacts and significant degradation in overall colorization quality, limiting potential applications of current methods for general purposes. To address this limitation, we conduct an in-depth analysis of the \textbf{carrier}, defined as the latent representation facilitating information transfer from reference to sketch. Based on this analysis, we propose a novel workflow that dynamically adapts the carrier to optimize distinct aspects of colorization. Specifically, for spatially misaligned artifacts, we introduce a split cross-attention mechanism with spatial masks, enabling region-specific reference injection within the diffusion process. To mitigate semantic neglect of sketches, we employ dedicated background and style encoders to transfer detailed reference information in the latent feature space, achieving enhanced spatial control and richer detail synthesis. Furthermore, we propose character-mask merging and background bleaching as preprocessing steps to improve foreground-background integration and background generation. Extensive qualitative and quantitative evaluations, including a user study, demonstrate the superior performance of our proposed method compared to existing approaches. An ablation study further validates the efficacy of each proposed component.
Image Referenced Sketch Colorization Based on Animation Creation Workflow
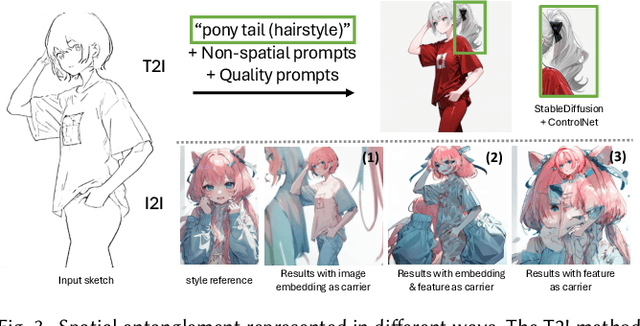
Feb 27, 2025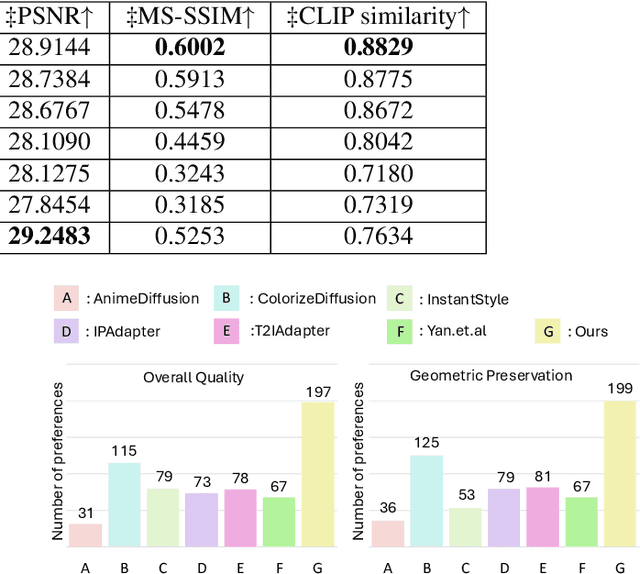
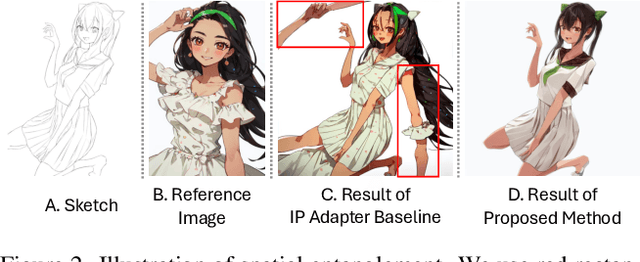

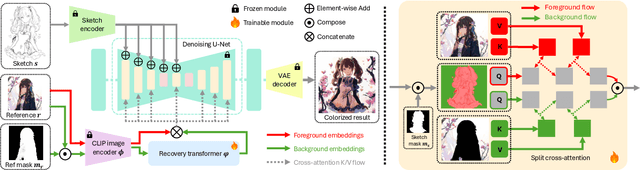
Sketch colorization plays an important role in animation and digital illustration production tasks. However, existing methods still meet problems in that text-guided methods fail to provide accurate color and style reference, hint-guided methods still involve manual operation, and image-referenced methods are prone to cause artifacts. To address these limitations, we propose a diffusion-based framework inspired by real-world animation production workflows. Our approach leverages the sketch as the spatial guidance and an RGB image as the color reference, and separately extracts foreground and background from the reference image with spatial masks. Particularly, we introduce a split cross-attention mechanism with LoRA (Low-Rank Adaptation) modules. They are trained separately with foreground and background regions to control the corresponding embeddings for keys and values in cross-attention. This design allows the diffusion model to integrate information from foreground and background independently, preventing interference and eliminating the spatial artifacts. During inference, we design switchable inference modes for diverse use scenarios by changing modules activated in the framework. Extensive qualitative and quantitative experiments, along with user studies, demonstrate our advantages over existing methods in generating high-qualigy artifact-free results with geometric mismatched references. Ablation studies further confirm the effectiveness of each component. Codes are available at https://github.com/ tellurion-kanata/colorizeDiffusion.
Beyond In-Distribution Success: Scaling Curves of CoT Granularity for Language Model Generalization
Feb 25, 2025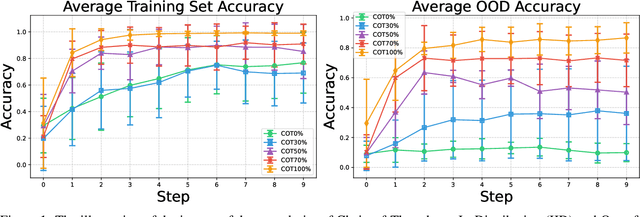
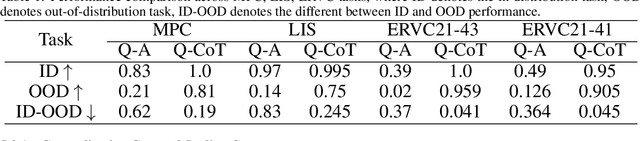
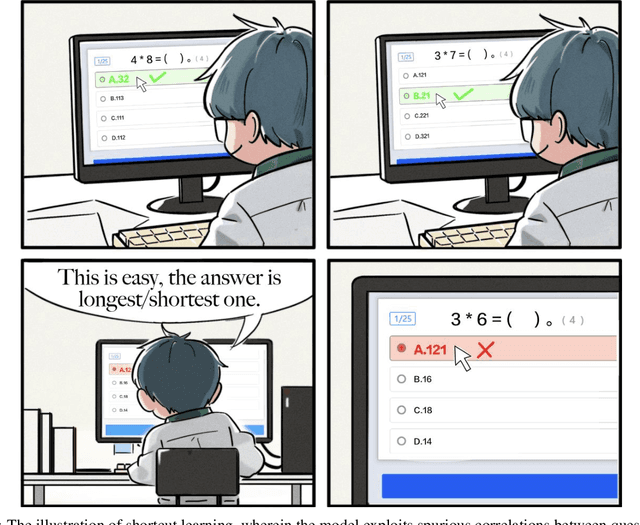

Generalization to novel compound tasks under distribution shift is important for deploying transformer-based language models (LMs). This work investigates Chain-of-Thought (CoT) reasoning as a means to enhance OOD generalization. Through controlled experiments across several compound tasks, we reveal three key insights: (1) While QA-trained models achieve near-perfect in-distribution accuracy, their OOD performance degrades catastrophically, even with 10000k+ training examples; (2) the granularity of CoT data strongly correlates with generalization performance; finer-grained CoT data leads to better generalization; (3) CoT exhibits remarkable sample efficiency, matching QA performance with much less (even 80%) data. Theoretically, we demonstrate that compound tasks inherently permit shortcuts in Q-A data that misalign with true reasoning principles, while CoT forces internalization of valid dependency structures, and thus can achieve better generalization. Further, we show that transformer positional embeddings can amplify generalization by emphasizing subtask condition recurrence in long CoT sequences. Our combined theoretical and empirical analysis provides compelling evidence for CoT reasoning as a crucial training paradigm for enabling LM generalization under real-world distributional shifts for compound tasks.
Large Language Models as Theory of Mind Aware Generative Agents with Counterfactual Reflection
Jan 26, 2025



Recent studies have increasingly demonstrated that large language models (LLMs) possess significant theory of mind (ToM) capabilities, showing the potential for simulating the tracking of mental states in generative agents. In this study, we propose a novel paradigm called ToM-agent, designed to empower LLMs-based generative agents to simulate ToM in open-domain conversational interactions. ToM-agent disentangles the confidence from mental states, facilitating the emulation of an agent's perception of its counterpart's mental states, such as beliefs, desires, and intentions (BDIs). Using past conversation history and verbal reflections, ToM-Agent can dynamically adjust counterparts' inferred BDIs, along with related confidence levels. We further put forth a counterfactual intervention method that reflects on the gap between the predicted responses of counterparts and their real utterances, thereby enhancing the efficiency of reflection. Leveraging empathetic and persuasion dialogue datasets, we assess the advantages of implementing the ToM-agent with downstream tasks, as well as its performance in both the first-order and the \textit{second-order} ToM. Our findings indicate that the ToM-agent can grasp the underlying reasons for their counterpart's behaviors beyond mere semantic-emotional supporting or decision-making based on common sense, providing new insights for studying large-scale LLMs-based simulation of human social behaviors.
DynamicKV: Task-Aware Adaptive KV Cache Compression for Long Context LLMs
Dec 19, 2024Efficient KV cache management in LLMs is crucial for long-context tasks like RAG and summarization. Existing KV cache compression methods enforce a fixed pattern, neglecting task-specific characteristics and reducing the retention of essential information. However, we observe distinct activation patterns across layers in various tasks, highlighting the need for adaptive strategies tailored to each task's unique demands. Based on this insight, we propose DynamicKV, a method that dynamically optimizes token retention by adjusting the number of tokens retained at each layer to adapt to the specific task. DynamicKV establishes global and per-layer maximum KV cache budgets, temporarily retaining the maximum budget for the current layer, and periodically updating the KV cache sizes of all preceding layers during inference. Our method retains only 1.7% of the KV cache size while achieving ~85% of the Full KV cache performance on LongBench. Notably, even under extreme compression (0.9%), DynamicKV surpasses state-of-the-art (SOTA) methods by 11% in the Needle-in-a-Haystack test using Mistral-7B-Instruct-v0.2. The code will be released.
Real-World Robot Applications of Foundation Models: A Review
Feb 08, 2024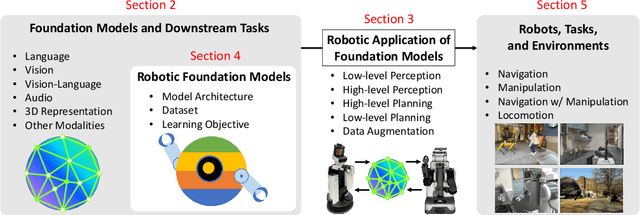
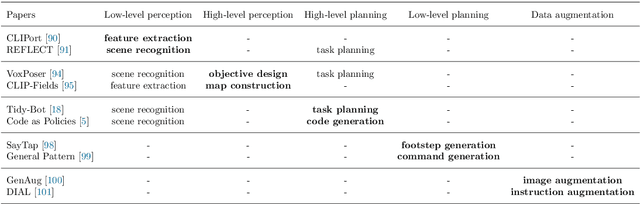
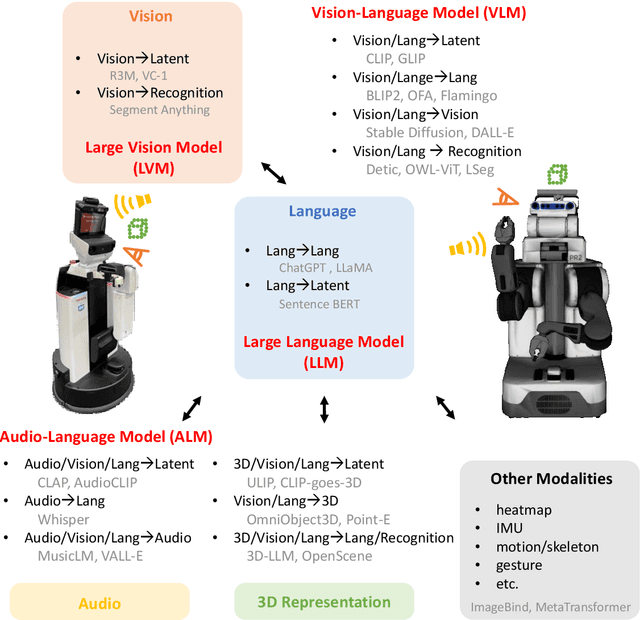
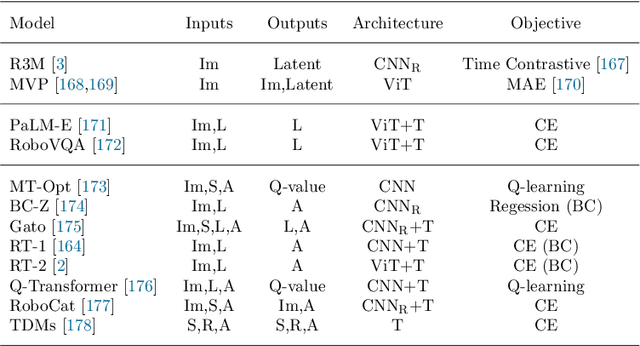
Recent developments in foundation models, like Large Language Models (LLMs) and Vision-Language Models (VLMs), trained on extensive data, facilitate flexible application across different tasks and modalities. Their impact spans various fields, including healthcare, education, and robotics. This paper provides an overview of the practical application of foundation models in real-world robotics, with a primary emphasis on the replacement of specific components within existing robot systems. The summary encompasses the perspective of input-output relationships in foundation models, as well as their role in perception, motion planning, and control within the field of robotics. This paper concludes with a discussion of future challenges and implications for practical robot applications.
Suspicion-Agent: Playing Imperfect Information Games with Theory of Mind Aware GPT-4
Oct 06, 2023Unlike perfect information games, where all elements are known to every player, imperfect information games emulate the real-world complexities of decision-making under uncertain or incomplete information. GPT-4, the recent breakthrough in large language models (LLMs) trained on massive passive data, is notable for its knowledge retrieval and reasoning abilities. This paper delves into the applicability of GPT-4's learned knowledge for imperfect information games. To achieve this, we introduce \textbf{Suspicion-Agent}, an innovative agent that leverages GPT-4's capabilities for performing in imperfect information games. With proper prompt engineering to achieve different functions, Suspicion-Agent based on GPT-4 demonstrates remarkable adaptability across a range of imperfect information card games. Importantly, GPT-4 displays a strong high-order theory of mind (ToM) capacity, meaning it can understand others and intentionally impact others' behavior. Leveraging this, we design a planning strategy that enables GPT-4 to competently play against different opponents, adapting its gameplay style as needed, while requiring only the game rules and descriptions of observations as input. In the experiments, we qualitatively showcase the capabilities of Suspicion-Agent across three different imperfect information games and then quantitatively evaluate it in Leduc Hold'em. The results show that Suspicion-Agent can potentially outperform traditional algorithms designed for imperfect information games, without any specialized training or examples. In order to encourage and foster deeper insights within the community, we make our game-related data publicly available.
GenDOM: Generalizable One-shot Deformable Object Manipulation with Parameter-Aware Policy
Sep 19, 2023Due to the inherent uncertainty in their deformability during motion, previous methods in deformable object manipulation, such as rope and cloth, often required hundreds of real-world demonstrations to train a manipulation policy for each object, which hinders their applications in our ever-changing world. To address this issue, we introduce GenDOM, a framework that allows the manipulation policy to handle different deformable objects with only a single real-world demonstration. To achieve this, we augment the policy by conditioning it on deformable object parameters and training it with a diverse range of simulated deformable objects so that the policy can adjust actions based on different object parameters. At the time of inference, given a new object, GenDOM can estimate the deformable object parameters with only a single real-world demonstration by minimizing the disparity between the grid density of point clouds of real-world demonstrations and simulations in a differentiable physics simulator. Empirical validations on both simulated and real-world object manipulation setups clearly show that our method can manipulate different objects with a single demonstration and significantly outperforms the baseline in both environments (a 62% improvement for in-domain ropes and a 15% improvement for out-of-distribution ropes in simulation, as well as a 26% improvement for ropes and a 50% improvement for cloths in the real world), demonstrating the effectiveness of our approach in one-shot deformable object manipulation.