 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond In-Distribution Success: Scaling Curves of CoT Granularity for Language Model Generalization
Feb 25, 2025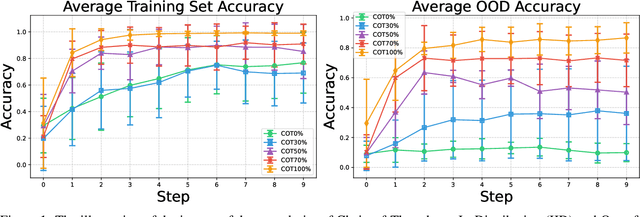
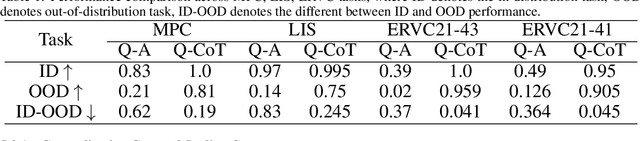
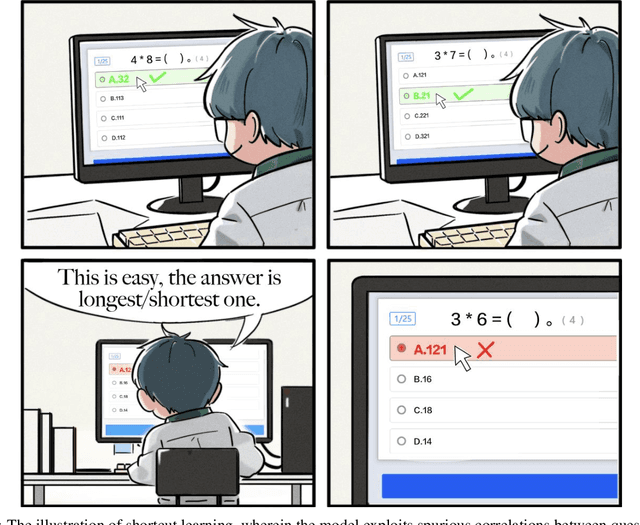

Generalization to novel compound tasks under distribution shift is important for deploying transformer-based language models (LMs). This work investigates Chain-of-Thought (CoT) reasoning as a means to enhance OOD generalization. Through controlled experiments across several compound tasks, we reveal three key insights: (1) While QA-trained models achieve near-perfect in-distribution accuracy, their OOD performance degrades catastrophically, even with 10000k+ training examples; (2) the granularity of CoT data strongly correlates with generalization performance; finer-grained CoT data leads to better generalization; (3) CoT exhibits remarkable sample efficiency, matching QA performance with much less (even 80%) data. Theoretically, we demonstrate that compound tasks inherently permit shortcuts in Q-A data that misalign with true reasoning principles, while CoT forces internalization of valid dependency structures, and thus can achieve better generalization. Further, we show that transformer positional embeddings can amplify generalization by emphasizing subtask condition recurrence in long CoT sequences. Our combined theoretical and empirical analysis provides compelling evidence for CoT reasoning as a crucial training paradigm for enabling LM generalization under real-world distributional shifts for compound tasks.
Generating Unseen Nonlinear Evolution in Sea Surface Temperature Using a Deep Learning-Based Latent Space Data Assimilation Framework
Dec 18, 2024



Advances in data assimilation (DA) methods have greatly improved the accuracy of Earth system predictions. To fuse multi-source data and reconstruct the nonlinear evolution missing from observations, geoscientists are developing future-oriented DA methods. In this paper, we redesign a purely data-driven latent space DA framework (DeepDA) that employs a generative artificial intelligence model to capture the nonlinear evolution in sea surface temperature. Under variational constraints, DeepDA embedded with nonlinear features can effectively fuse heterogeneous data. The results show that DeepDA remains highly stable in capturing and generating nonlinear evolutions even when a large amount of observational information is missing. It can be found that when only 10% of the observation information is available, the error increase of DeepDA does not exceed 40%. Furthermore, DeepDA has been shown to be robust in the fusion of real observations and ensemble simulations. In particular, this paper provides a mechanism analysis of the nonlinear evolution generated by DeepDA from the perspective of physical patterns, which reveals the inherent explainability of our DL model in capturing multi-scale ocean signals.
Peer attention enhances student learning
Dec 04, 2023Human visual attention is susceptible to social influences. In education, peer effects impact student learning, but their precise role in modulating attention remains unclear. Our experiment (N=311) demonstrates that displaying peer visual attention regions when students watch online course videos enhances their focus and engagement. However, students retain adaptability in following peer attention cues. Overall, guided peer attention improves learning experiences and outcomes. These findings elucidate how peer visual attention shapes students' gaze patterns, deepening understanding of peer influence on learning. They also offer insights into designing adaptive online learning interventions leveraging peer attention modelling to optimize student attentiveness and success.
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021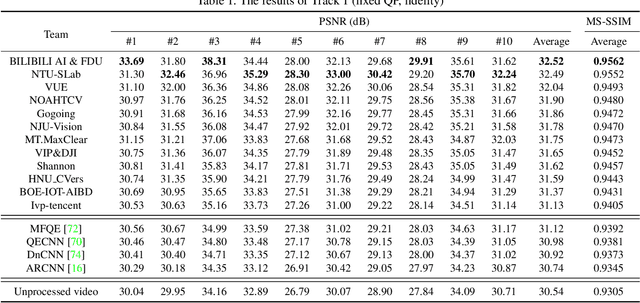
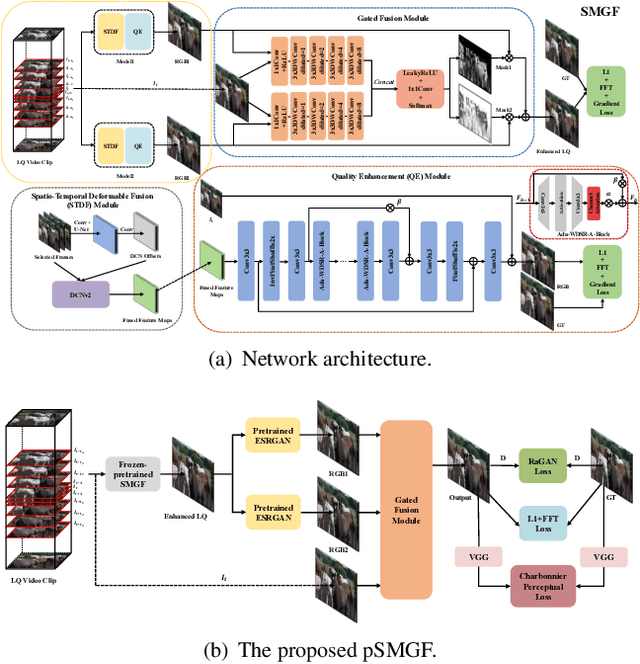
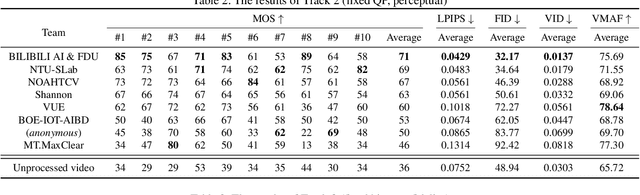
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh
Learning Not to Learn in the Presence of Noisy Labels
Feb 16, 2020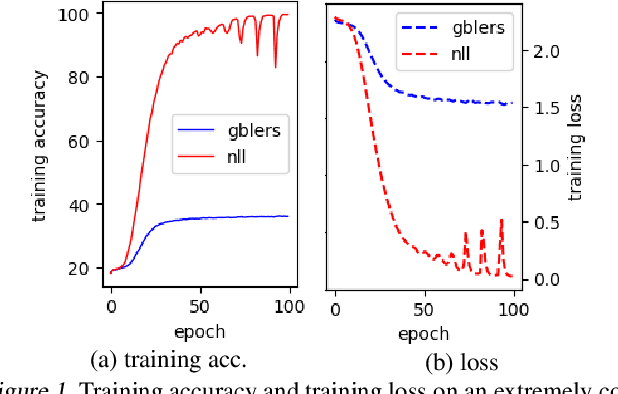

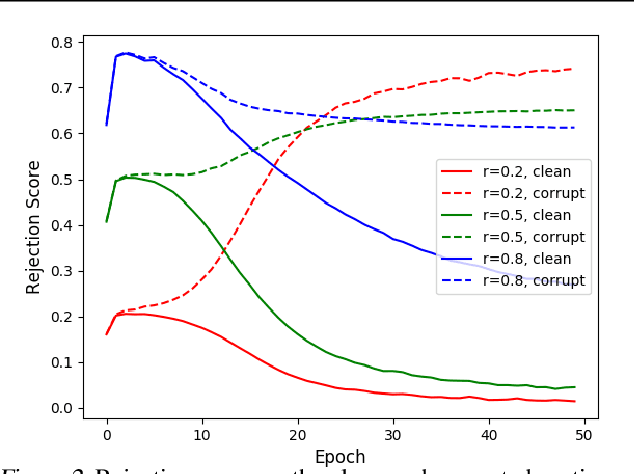
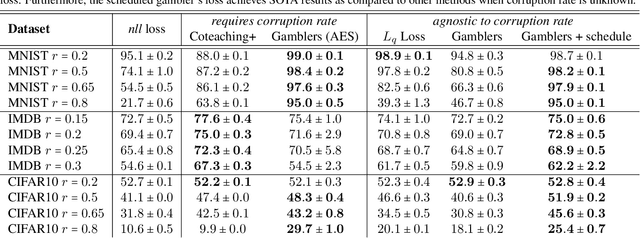
Learning in the presence of label noise is a challenging yet important task: it is crucial to design models that are robust in the presence of mislabeled datasets. In this paper, we discover that a new class of loss functions called the gambler's loss provides strong robustness to label noise across various levels of corruption. We show that training with this loss function encourages the model to "abstain" from learning on the data points with noisy labels, resulting in a simple and effective method to improve robustness and generalization. In addition, we propose two practical extensions of the method: 1) an analytical early stopping criterion to approximately stop training before the memorization of noisy labels, as well as 2) a heuristic for setting hyperparameters which do not require knowledge of the noise corruption rate. We demonstrate the effectiveness of our method by achieving strong results across three image and text classification tasks as compared to existing baselines.
Approximate Random Dropout
May 23, 2018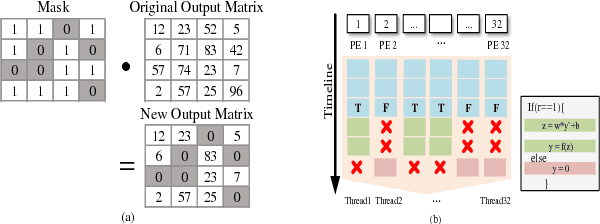
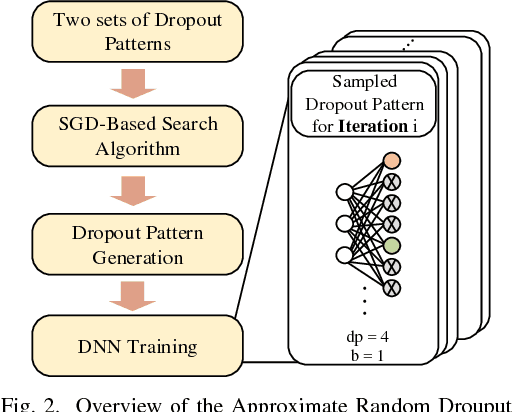
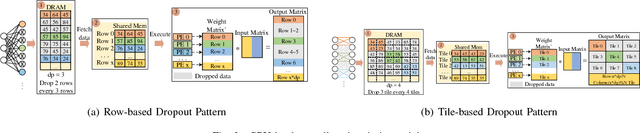
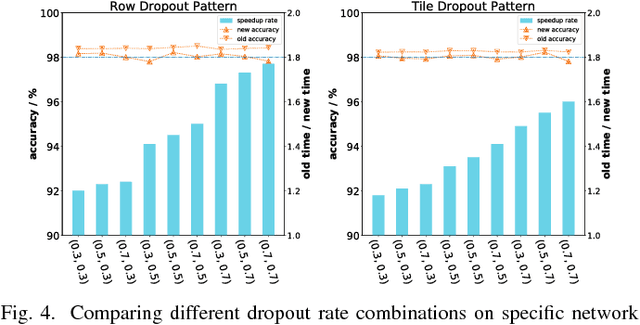
The training phases of Deep neural network (DNN) consume enormous processing time and energy. Compression techniques for inference acceleration leveraging the sparsity of DNNs, however, can be hardly used in the training phase. Because the training involves dense matrix-multiplication using GPGPU, which endorse regular and structural data layout. In this paper, we exploit the sparsity of DNN resulting from the random dropout technique to eliminate the unnecessary computation and data access for those dropped neurons or synapses in the training phase. Experiments results on MLP and LSTM on standard benchmarks show that the proposed Approximate Random Dropout can reduce the training time by half on average with ignorable accuracy loss.
Learning directed acyclic graphs via bootstrap aggregating
Jun 09, 2014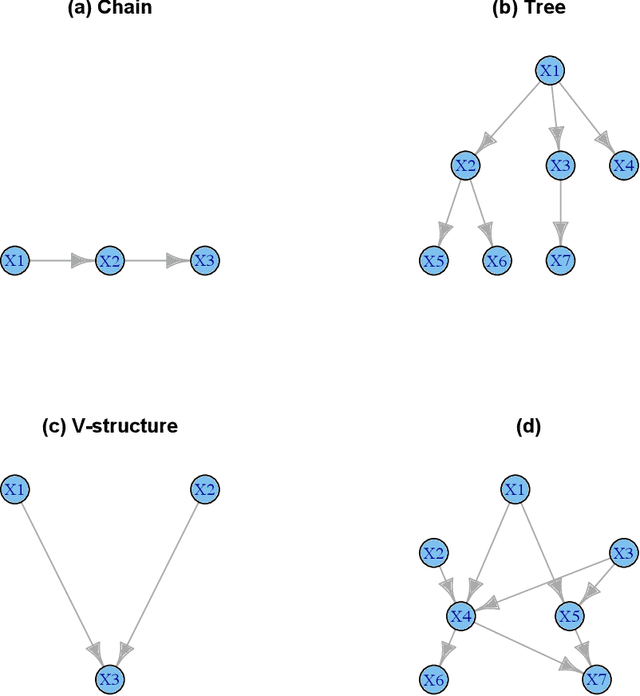
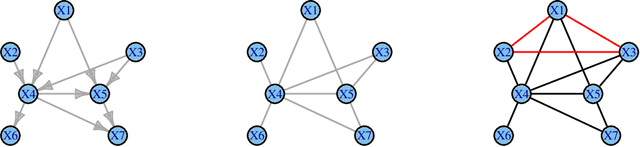


Probabilistic graphical models are graphical representations of probability distributions. Graphical models have applications in many fields including biology, social sciences, linguistic, neuroscience. In this paper, we propose directed acyclic graphs (DAGs) learning via bootstrap aggregating. The proposed procedure is named as DAGBag. Specifically, an ensemble of DAGs is first learned based on bootstrap resamples of the data and then an aggregated DAG is derived by minimizing the overall distance to the entire ensemble. A family of metrics based on the structural hamming distance is defined for the space of DAGs (of a given node set) and is used for aggregation. Under the high-dimensional-low-sample size setting, the graph learned on one data set often has excessive number of false positive edges due to over-fitting of the noise. Aggregation overcomes over-fitting through variance reduction and thus greatly reduces false positives. We also develop an efficient implementation of the hill climbing search algorithm of DAG learning which makes the proposed method computationally competitive for the high-dimensional regime. The DAGBag procedure is implemented in the R package dagbag.