 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDRel: A New Dataset for Interpersonal Relation Classification in Dyadic Dialogues
Dec 04, 2020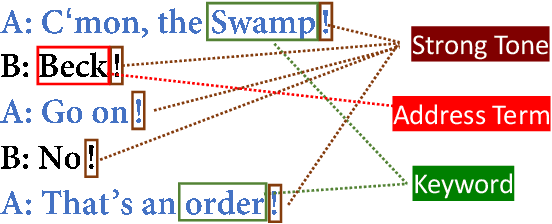
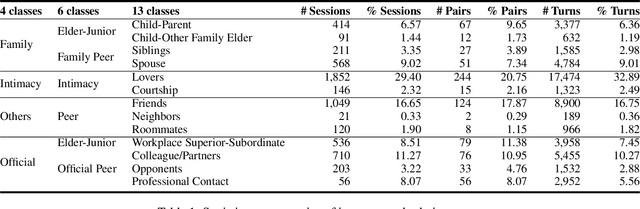

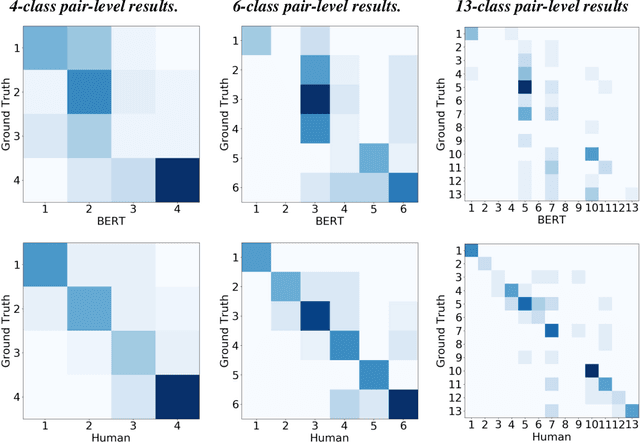
Interpersonal language style shifting in dialogues is an interesting and almost instinctive ability of human. Understanding interpersonal relationship from language content is also a crucial step toward further understanding dialogues. Previous work mainly focuses on relation extraction between named entities in texts. In this paper, we propose the task of relation classification of interlocutors based on their dialogues. We crawled movie scripts from IMSDb, and annotated the relation labels for each session according to 13 pre-defined relationships. The annotated dataset DDRel consists of 6300 dyadic dialogue sessions between 694 pair of speakers with 53,126 utterances in total. We also construct session-level and pair-level relation classification tasks with widely-accepted baselines. The experimental results show that this task is challenging for existing models and the dataset will be useful for future research.
Approximate Random Dropout
May 23, 2018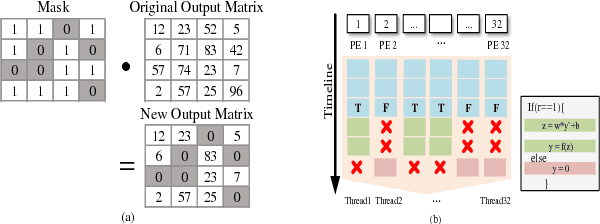
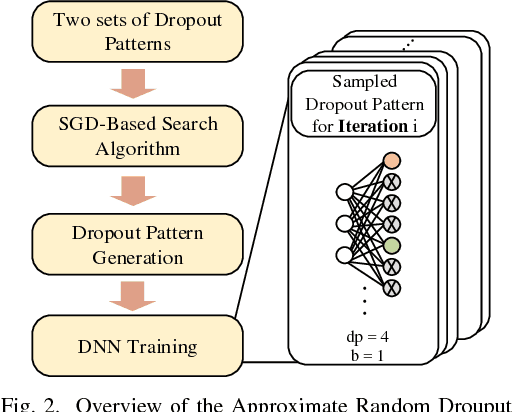
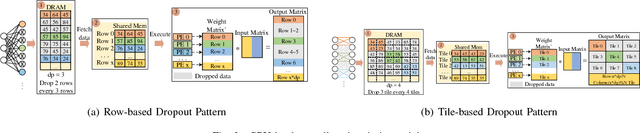
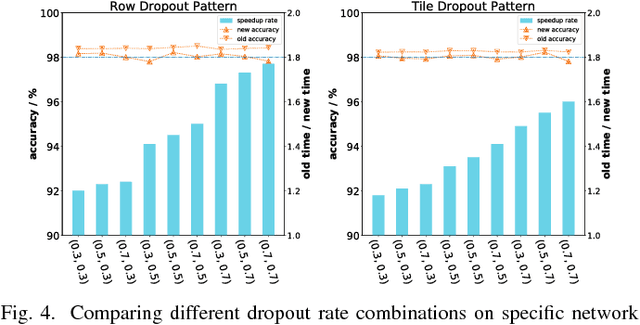
The training phases of Deep neural network (DNN) consume enormous processing time and energy. Compression techniques for inference acceleration leveraging the sparsity of DNNs, however, can be hardly used in the training phase. Because the training involves dense matrix-multiplication using GPGPU, which endorse regular and structural data layout. In this paper, we exploit the sparsity of DNN resulting from the random dropout technique to eliminate the unnecessary computation and data access for those dropped neurons or synapses in the training phase. Experiments results on MLP and LSTM on standard benchmarks show that the proposed Approximate Random Dropout can reduce the training time by half on average with ignorable accuracy loss.