Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Random Dropout
Paper and Code
May 23, 2018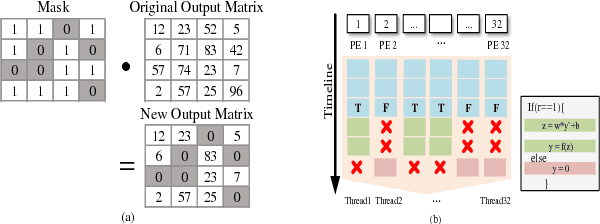
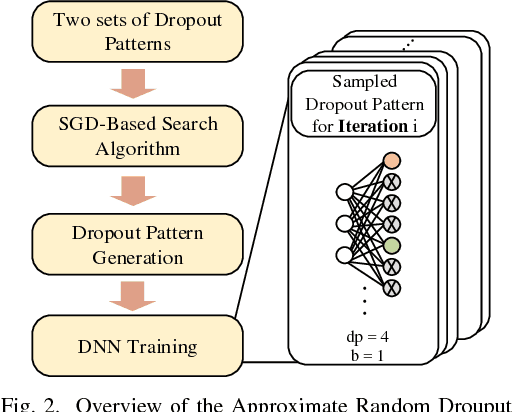
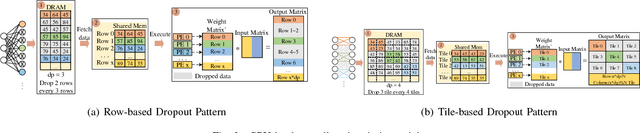
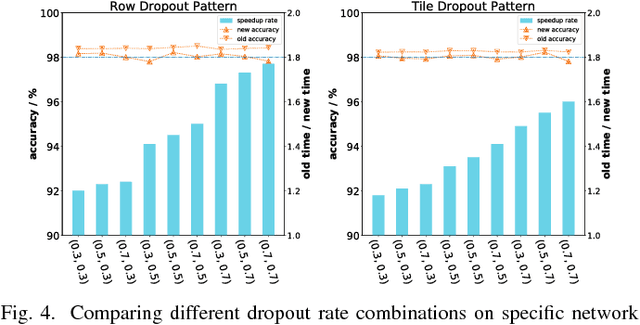
The training phases of Deep neural network (DNN) consume enormous processing time and energy. Compression techniques for inference acceleration leveraging the sparsity of DNNs, however, can be hardly used in the training phase. Because the training involves dense matrix-multiplication using GPGPU, which endorse regular and structural data layout. In this paper, we exploit the sparsity of DNN resulting from the random dropout technique to eliminate the unnecessary computation and data access for those dropped neurons or synapses in the training phase. Experiments results on MLP and LSTM on standard benchmarks show that the proposed Approximate Random Dropout can reduce the training time by half on average with ignorable accuracy loss.
* 10 pages, 6 figures, conference
View paper on