 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Continual Learning with Dynamic Label Hierarchies
May 12, 2026Online Continual Learning (OCL) aims to learn from endless non\text{-}stationary data streams, yet most existing methods assume a flat label space and overlook the hierarchical organization of real\text{-}world concepts that evolves both horizontally (sibling classes) and vertically (coarse or fine categories). To better reflect this context, we introduce a new problem setting, DHOCL (Online Continual Learning from Dynamic Hierarchies), where taxonomies evolve across granularities and each sample provides supervision at a single hierarchical level. In this setting, we find two fundamental issues: (i) partial supervision under mixed granularities provides only point-wise signals over an evolving path-wise hierarchy, which constrains plasticity and undermines cross-level semantic consistency, and (ii) the dynamically evolving hierarchies induce granularity-dependent interference, destabilizing popular replay and regularization mechanisms and thereby exacerbating catastrophic forgetting. To tackle these issues, we propose HALO (Hierarchical Adaptive Learning with Organized Prototypes), which adaptively combines complementary classification heads, regularized by organized learnable hierarchical prototypes, enabling rapid adaptation, hierarchical consistency, and structured knowledge consolidation as the taxonomy evolves. Extensive experiments on multiple benchmarks demonstrate that HALO consistently outperforms existing methods across hierarchical accuracy, mistake severity, and continual performance.
EmbodiSkill: Skill-Aware Reflection for Self-Evolving Embodied Agents
May 11, 2026Embodied agents can benefit from skills that guide object search, action execution, and state changes across diverse environments. Since embodied environments vary across layouts, object states, and other execution factors, these skills must self-evolve from trajectories generated during task execution. However, existing skill self-evolution methods are mainly developed in digital environments and often convert trajectories into coarse skill updates. Directly applying this paradigm to embodied settings is problematic, because a failed task execution may reflect not only incorrect skill content, but also an execution lapse in which the agent fails to follow valid guidance. We propose EmbodiSkill, a training-free framework for embodied skill self-evolution through skill-aware reflection and targeted revision. EmbodiSkill interprets each trajectory with respect to the current skill, uses skill-changing evidence to update the skill body, and uses execution-lapse evidence to preserve and emphasize valid guidance. Experiments on ALFWorld and EmbodiedBench show that EmbodiSkill consistently improves embodied task success. On ALFWorld, EmbodiSkill enables a frozen Qwen3.5-27B executor to reach 93.28% task success, outperforming GPT-5.2 used as a direct agent without skills by 31.58%. These results show that skill-aware self-evolution helps embodied agents accumulate reusable procedural knowledge from their own trajectories.
Global Pre-fixing, Local Adjusting: A Simple yet Effective Contrastive Strategy for Continual Learning
Sep 18, 2025Continual learning (CL) involves acquiring and accumulating knowledge from evolving tasks while alleviating catastrophic forgetting. Recently, leveraging contrastive loss to construct more transferable and less forgetful representations has been a promising direction in CL. Despite advancements, their performance is still limited due to confusion arising from both inter-task and intra-task features. To address the problem, we propose a simple yet effective contrastive strategy named \textbf{G}lobal \textbf{P}re-fixing, \textbf{L}ocal \textbf{A}djusting for \textbf{S}upervised \textbf{C}ontrastive learning (GPLASC). Specifically, to avoid task-level confusion, we divide the entire unit hypersphere of representations into non-overlapping regions, with the centers of the regions forming an inter-task pre-fixed \textbf{E}quiangular \textbf{T}ight \textbf{F}rame (ETF). Meanwhile, for individual tasks, our method helps regulate the feature structure and form intra-task adjustable ETFs within their respective allocated regions. As a result, our method \textit{simultaneously} ensures discriminative feature structures both between tasks and within tasks and can be seamlessly integrated into any existing contrastive continual learning framework. Extensive experiments validate its effectiveness.
Cut out and Replay: A Simple yet Versatile Strategy for Multi-Label Online Continual Learning
May 26, 2025Multi-Label Online Continual Learning (MOCL) requires models to learn continuously from endless multi-label data streams, facing complex challenges including persistent catastrophic forgetting, potential missing labels, and uncontrollable imbalanced class distributions. While existing MOCL methods attempt to address these challenges through various techniques, \textit{they all overlook label-specific region identifying and feature learning} - a fundamental solution rooted in multi-label learning but challenging to achieve in the online setting with incremental and partial supervision. To this end, we first leverage the inherent structural information of input data to evaluate and verify the innate localization capability of different pre-trained models. Then, we propose CUTER (CUT-out-and-Experience-Replay), a simple yet versatile strategy that provides fine-grained supervision signals by further identifying, strengthening and cutting out label-specific regions for efficient experience replay. It not only enables models to simultaneously address catastrophic forgetting, missing labels, and class imbalance challenges, but also serves as an orthogonal solution that seamlessly integrates with existing approaches. Extensive experiments on multiple multi-label image benchmarks demonstrate the superiority of our proposed method. The code is available at \href{https://github.com/wxr99/Cut-Replay}{https://github.com/wxr99/Cut-Replay}
LoD: Loss-difference OOD Detection by Intentionally Label-Noisifying Unlabeled Wild Data
May 19, 2025Using unlabeled wild data containing both in-distribution (ID) and out-of-distribution (OOD) data to improve the safety and reliability of models has recently received increasing attention. Existing methods either design customized losses for labeled ID and unlabeled wild data then perform joint optimization, or first filter out OOD data from the latter then learn an OOD detector. While achieving varying degrees of success, two potential issues remain: (i) Labeled ID data typically dominates the learning of models, inevitably making models tend to fit OOD data as IDs; (ii) The selection of thresholds for identifying OOD data in unlabeled wild data usually faces dilemma due to the unavailability of pure OOD samples. To address these issues, we propose a novel loss-difference OOD detection framework (LoD) by \textit{intentionally label-noisifying} unlabeled wild data. Such operations not only enable labeled ID data and OOD data in unlabeled wild data to jointly dominate the models' learning but also ensure the distinguishability of the losses between ID and OOD samples in unlabeled wild data, allowing the classic clustering technique (e.g., K-means) to filter these OOD samples without requiring thresholds any longer. We also provide theoretical foundation for LoD's viability, and extensive experiments verify its superiority.
Knowledge capture, adaptation and composition (KCAC): A framework for cross-task curriculum learning in robotic manipulation
May 15, 2025Reinforcement learning (RL) has demonstrated remarkable potential in robotic manipulation but faces challenges in sample inefficiency and lack of interpretability, limiting its applicability in real world scenarios. Enabling the agent to gain a deeper understanding and adapt more efficiently to diverse working scenarios is crucial, and strategic knowledge utilization is a key factor in this process. This paper proposes a Knowledge Capture, Adaptation, and Composition (KCAC) framework to systematically integrate knowledge transfer into RL through cross-task curriculum learning. KCAC is evaluated using a two block stacking task in the CausalWorld benchmark, a complex robotic manipulation environment. To our knowledge, existing RL approaches fail to solve this task effectively, reflecting deficiencies in knowledge capture. In this work, we redesign the benchmark reward function by removing rigid constraints and strict ordering, allowing the agent to maximize total rewards concurrently and enabling flexible task completion. Furthermore, we define two self-designed sub-tasks and implement a structured cross-task curriculum to facilitate efficient learning. As a result, our KCAC approach achieves a 40 percent reduction in training time while improving task success rates by 10 percent compared to traditional RL methods. Through extensive evaluation, we identify key curriculum design parameters subtask selection, transition timing, and learning rate that optimize learning efficiency and provide conceptual guidance for curriculum based RL frameworks. This work offers valuable insights into curriculum design in RL and robotic learning.
ColorizeDiffusion v2: Enhancing Reference-based Sketch Colorization Through Separating Utilities
Apr 09, 2025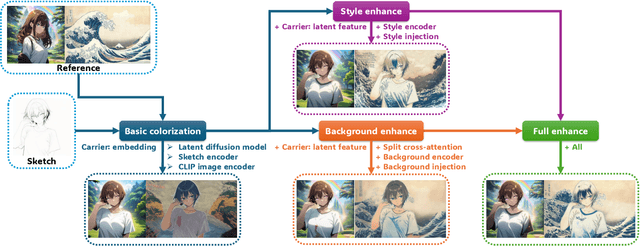


Reference-based sketch colorization methods have garnered significant attention due to their potential applications in the animation production industry. However, most existing methods are trained with image triplets of sketch, reference, and ground truth that are semantically and spatially well-aligned, while real-world references and sketches often exhibit substantial misalignment. This mismatch in data distribution between training and inference leads to overfitting, consequently resulting in spatial artifacts and significant degradation in overall colorization quality, limiting potential applications of current methods for general purposes. To address this limitation, we conduct an in-depth analysis of the \textbf{carrier}, defined as the latent representation facilitating information transfer from reference to sketch. Based on this analysis, we propose a novel workflow that dynamically adapts the carrier to optimize distinct aspects of colorization. Specifically, for spatially misaligned artifacts, we introduce a split cross-attention mechanism with spatial masks, enabling region-specific reference injection within the diffusion process. To mitigate semantic neglect of sketches, we employ dedicated background and style encoders to transfer detailed reference information in the latent feature space, achieving enhanced spatial control and richer detail synthesis. Furthermore, we propose character-mask merging and background bleaching as preprocessing steps to improve foreground-background integration and background generation. Extensive qualitative and quantitative evaluations, including a user study, demonstrate the superior performance of our proposed method compared to existing approaches. An ablation study further validates the efficacy of each proposed component.
Image Referenced Sketch Colorization Based on Animation Creation Workflow
Feb 27, 2025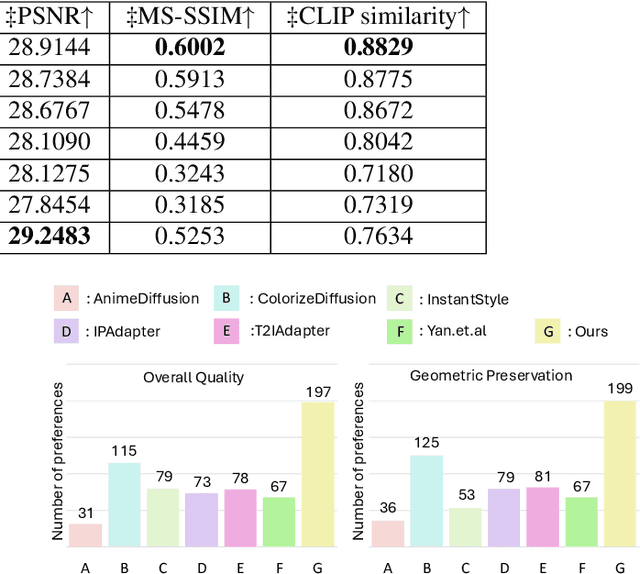
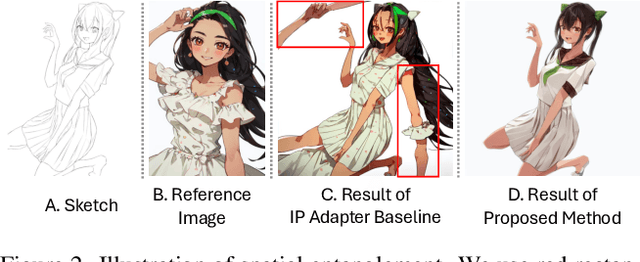

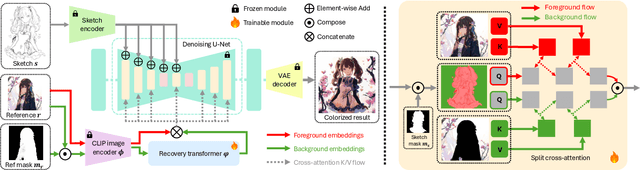
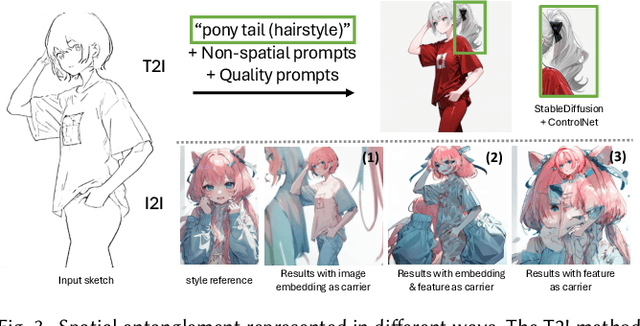
Sketch colorization plays an important role in animation and digital illustration production tasks. However, existing methods still meet problems in that text-guided methods fail to provide accurate color and style reference, hint-guided methods still involve manual operation, and image-referenced methods are prone to cause artifacts. To address these limitations, we propose a diffusion-based framework inspired by real-world animation production workflows. Our approach leverages the sketch as the spatial guidance and an RGB image as the color reference, and separately extracts foreground and background from the reference image with spatial masks. Particularly, we introduce a split cross-attention mechanism with LoRA (Low-Rank Adaptation) modules. They are trained separately with foreground and background regions to control the corresponding embeddings for keys and values in cross-attention. This design allows the diffusion model to integrate information from foreground and background independently, preventing interference and eliminating the spatial artifacts. During inference, we design switchable inference modes for diverse use scenarios by changing modules activated in the framework. Extensive qualitative and quantitative experiments, along with user studies, demonstrate our advantages over existing methods in generating high-qualigy artifact-free results with geometric mismatched references. Ablation studies further confirm the effectiveness of each component. Codes are available at https://github.com/ tellurion-kanata/colorizeDiffusion.
Filter, Obstruct and Dilute: Defending Against Backdoor Attacks on Semi-Supervised Learning
Feb 09, 2025Recent studies have verified that semi-supervised learning (SSL) is vulnerable to data poisoning backdoor attacks. Even a tiny fraction of contaminated training data is sufficient for adversaries to manipulate up to 90\% of the test outputs in existing SSL methods. Given the emerging threat of backdoor attacks designed for SSL, this work aims to protect SSL against such risks, marking it as one of the few known efforts in this area. Specifically, we begin by identifying that the spurious correlations between the backdoor triggers and the target class implanted by adversaries are the primary cause of manipulated model predictions during the test phase. To disrupt these correlations, we utilize three key techniques: Gaussian Filter, complementary learning and trigger mix-up, which collectively filter, obstruct and dilute the influence of backdoor attacks in both data pre-processing and feature learning. Experimental results demonstrate that our proposed method, Backdoor Invalidator (BI), significantly reduces the average attack success rate from 84.7\% to 1.8\% across different state-of-the-art backdoor attacks. It is also worth mentioning that BI does not sacrifice accuracy on clean data and is supported by a theoretical guarantee of its generalization capability.
Forgetting, Ignorance or Myopia: Revisiting Key Challenges in Online Continual Learning
Sep 28, 2024Online continual learning requires the models to learn from constant, endless streams of data. While significant efforts have been made in this field, most were focused on mitigating the catastrophic forgetting issue to achieve better classification ability, at the cost of a much heavier training workload. They overlooked that in real-world scenarios, e.g., in high-speed data stream environments, data do not pause to accommodate slow models. In this paper, we emphasize that model throughput -- defined as the maximum number of training samples that a model can process within a unit of time -- is equally important. It directly limits how much data a model can utilize and presents a challenging dilemma for current methods. With this understanding, we revisit key challenges in OCL from both empirical and theoretical perspectives, highlighting two critical issues beyond the well-documented catastrophic forgetting: Model's ignorance: the single-pass nature of OCL challenges models to learn effective features within constrained training time and storage capacity, leading to a trade-off between effective learning and model throughput; Model's myopia: the local learning nature of OCL on the current task leads the model to adopt overly simplified, task-specific features and excessively sparse classifier, resulting in the gap between the optimal solution for the current task and the global objective. To tackle these issues, we propose the Non-sparse Classifier Evolution framework (NsCE) to facilitate effective global discriminative feature learning with minimal time cost. NsCE integrates non-sparse maximum separation regularization and targeted experience replay techniques with the help of pre-trained models, enabling rapid acquisition of new globally discriminative features.