 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Incomplete Multi-label Learning: Recent Advances and Future Trends
Paper and Code
Jun 10, 2024
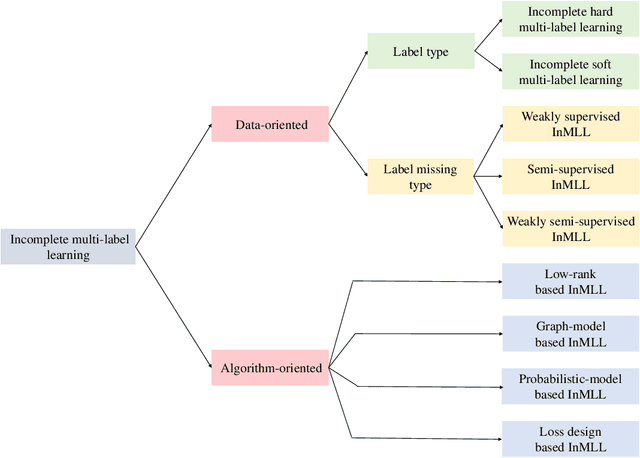
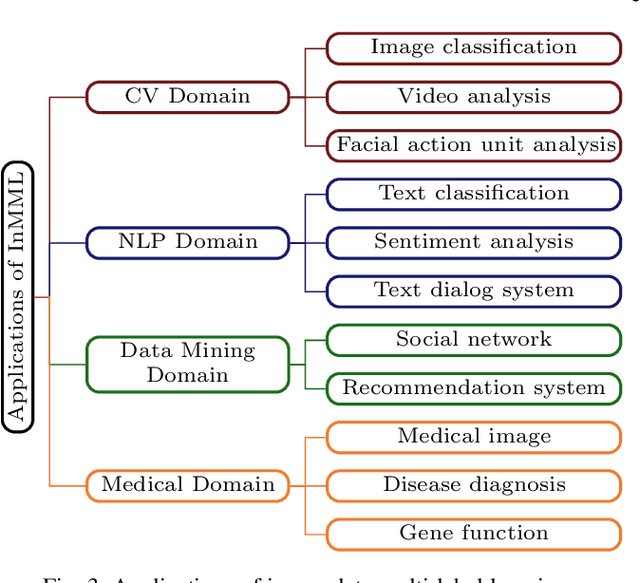
In reality, data often exhibit associations with multiple labels, making multi-label learning (MLL) become a prominent research topic. The last two decades have witnessed the success of MLL, which is indispensable from complete and accurate supervised information. However, obtaining such information in practice is always laborious and sometimes even impossible. To circumvent this dilemma, incomplete multi-label learning (InMLL) has emerged, aiming to learn from incomplete labeled data. To date, enormous InMLL works have been proposed to narrow the performance gap with complete MLL, whereas a systematic review for InMLL is still absent. In this paper, we not only attempt to fill the lacuna but also strive to pave the way for innovative research. Specifically, we retrospect the origin of InMLL, analyze the challenges of InMLL, and make a taxonomy of InMLL from the data-oriented and algorithm-oriented perspectives, respectively. Besides, we also present real applications of InMLL in various domains. More importantly, we highlight several potential future trends, including four open problems that are more in line with practice and three under-explored/unexplored techniques in addressing the challenges of InMLL, which may shed new light on developing novel research directions in the field of InMLL.