 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Causal Perspective for Enhancing Jailbreak Attack and Defense
Jan 31, 2026Uncovering the mechanisms behind "jailbreaks" in large language models (LLMs) is crucial for enhancing their safety and reliability, yet these mechanisms remain poorly understood. Existing studies predominantly analyze jailbreak prompts by probing latent representations, often overlooking the causal relationships between interpretable prompt features and jailbreak occurrences. In this work, we propose Causal Analyst, a framework that integrates LLMs into data-driven causal discovery to identify the direct causes of jailbreaks and leverage them for both attack and defense. We introduce a comprehensive dataset comprising 35k jailbreak attempts across seven LLMs, systematically constructed from 100 attack templates and 50 harmful queries, annotated with 37 meticulously designed human-readable prompt features. By jointly training LLM-based prompt encoding and GNN-based causal graph learning, we reconstruct causal pathways linking prompt features to jailbreak responses. Our analysis reveals that specific features, such as "Positive Character" and "Number of Task Steps", act as direct causal drivers of jailbreaks. We demonstrate the practical utility of these insights through two applications: (1) a Jailbreaking Enhancer that targets identified causal features to significantly boost attack success rates on public benchmarks, and (2) a Guardrail Advisor that utilizes the learned causal graph to extract true malicious intent from obfuscated queries. Extensive experiments, including baseline comparisons and causal structure validation, confirm the robustness of our causal analysis and its superiority over non-causal approaches. Our results suggest that analyzing jailbreak features from a causal perspective is an effective and interpretable approach for improving LLM reliability. Our code is available at https://github.com/Master-PLC/Causal-Analyst.
Negatives-Dominant Contrastive Learning for Generalization in Imbalanced Domains
Jan 29, 2026Imbalanced Domain Generalization (IDG) focuses on mitigating both domain and label shifts, both of which fundamentally shape the model's decision boundaries, particularly under heterogeneous long-tailed distributions across domains. Despite its practical significance, it remains underexplored, primarily due to the technical complexity of handling their entanglement and the paucity of theoretical foundations. In this paper, we begin by theoretically establishing the generalization bound for IDG, highlighting the role of posterior discrepancy and decision margin. This bound motivates us to focus on directly steering decision boundaries, marking a clear departure from existing methods. Subsequently, we technically propose a novel Negative-Dominant Contrastive Learning (NDCL) for IDG to enhance discriminability while enforce posterior consistency across domains. Specifically, inter-class decision-boundary separation is enhanced by placing greater emphasis on negatives as the primary signal in our contrastive learning, naturally amplifying gradient signals for minority classes to avoid the decision boundary being biased toward majority classes. Meanwhile, intra-class compactness is encouraged through a re-weighted cross-entropy strategy, and posterior consistency across domains is enforced through a prediction-central alignment strategy. Finally, rigorous yet challenging experiments on benchmarks validate the effectiveness of our NDCL. The code is available at https://github.com/Alrash/NDCL.
Beyond Observations: Reconstruction Error-Guided Irregularly Sampled Time Series Representation Learning
Nov 15, 2025Irregularly sampled time series (ISTS), characterized by non-uniform time intervals with natural missingness, are prevalent in real-world applications. Existing approaches for ISTS modeling primarily rely on observed values to impute unobserved ones or infer latent dynamics. However, these methods overlook a critical source of learning signal: the reconstruction error inherently produced during model training. Such error implicitly reflects how well a model captures the underlying data structure and can serve as an informative proxy for unobserved values. To exploit this insight, we propose iTimER, a simple yet effective self-supervised pre-training framework for ISTS representation learning. iTimER models the distribution of reconstruction errors over observed values and generates pseudo-observations for unobserved timestamps through a mixup strategy between sampled errors and the last available observations. This transforms unobserved timestamps into noise-aware training targets, enabling meaningful reconstruction signals. A Wasserstein metric aligns reconstruction error distributions between observed and pseudo-observed regions, while a contrastive learning objective enhances the discriminability of learned representations. Extensive experiments on classification, interpolation, and forecasting tasks demonstrate that iTimER consistently outperforms state-of-the-art methods under the ISTS setting.
Mirage in the Eyes: Hallucination Attack on Multi-modal Large Language Models with Only Attention Sink
Jan 25, 2025



Fusing visual understanding into language generation, Multi-modal Large Language Models (MLLMs) are revolutionizing visual-language applications. Yet, these models are often plagued by the hallucination problem, which involves generating inaccurate objects, attributes, and relationships that do not match the visual content. In this work, we delve into the internal attention mechanisms of MLLMs to reveal the underlying causes of hallucination, exposing the inherent vulnerabilities in the instruction-tuning process. We propose a novel hallucination attack against MLLMs that exploits attention sink behaviors to trigger hallucinated content with minimal image-text relevance, posing a significant threat to critical downstream applications. Distinguished from previous adversarial methods that rely on fixed patterns, our approach generates dynamic, effective, and highly transferable visual adversarial inputs, without sacrificing the quality of model responses. Comprehensive experiments on 6 prominent MLLMs demonstrate the efficacy of our attack in compromising black-box MLLMs even with extensive mitigating mechanisms, as well as the promising results against cutting-edge commercial APIs, such as GPT-4o and Gemini 1.5. Our code is available at https://huggingface.co/RachelHGF/Mirage-in-the-Eyes.
TimeCHEAT: A Channel Harmony Strategy for Irregularly Sampled Multivariate Time Series Analysis
Dec 17, 2024Irregularly sampled multivariate time series (ISMTS) are prevalent in reality. Due to their non-uniform intervals between successive observations and varying sampling rates among series, the channel-independent (CI) strategy, which has been demonstrated more desirable for complete multivariate time series forecasting in recent studies, has failed. This failure can be further attributed to the sampling sparsity, which provides insufficient information for effective CI learning, thereby reducing its capacity. When we resort to the channel-dependent (CD) strategy, even higher capacity cannot mitigate the potential loss of diversity in learning similar embedding patterns across different channels. We find that existing work considers CI and CD strategies to be mutually exclusive, primarily because they apply these strategies to the global channel. However, we hold the view that channel strategies do not necessarily have to be used globally. Instead, by appropriately applying them locally and globally, we can create an opportunity to take full advantage of both strategies. This leads us to introduce the Channel Harmony ISMTS Transformer (TimeCHEAT), which utilizes the CD locally and the CI globally. Specifically, we segment the ISMTS into sub-series level patches. Locally, the CD strategy aggregates information within each patch for time embedding learning, maximizing the use of relevant observations while reducing long-range irrelevant interference. Here, we enhance generality by transforming embedding learning into an edge weight prediction task using bipartite graphs, eliminating the need for special prior knowledge. Globally, the CI strategy is applied across patches, allowing the Transformer to learn individualized attention patterns for each channel. Experimental results indicate our proposed TimeCHEAT demonstrates competitive SOTA performance across three mainstream tasks.
MuSiCNet: A Gradual Coarse-to-Fine Framework for Irregularly Sampled Multivariate Time Series Analysis
Dec 02, 2024



Irregularly sampled multivariate time series (ISMTS) are prevalent in reality. Most existing methods treat ISMTS as synchronized regularly sampled time series with missing values, neglecting that the irregularities are primarily attributed to variations in sampling rates. In this paper, we introduce a novel perspective that irregularity is essentially relative in some senses. With sampling rates artificially determined from low to high, an irregularly sampled time series can be transformed into a hierarchical set of relatively regular time series from coarse to fine. We observe that additional coarse-grained relatively regular series not only mitigate the irregularly sampled challenges to some extent but also incorporate broad-view temporal information, thereby serving as a valuable asset for representation learning. Therefore, following the philosophy of learning that Seeing the big picture first, then delving into the details, we present the Multi-Scale and Multi-Correlation Attention Network (MuSiCNet) combining multiple scales to iteratively refine the ISMTS representation. Specifically, within each scale, we explore time attention and frequency correlation matrices to aggregate intra- and inter-series information, naturally enhancing the representation quality with richer and more intrinsic details. While across adjacent scales, we employ a representation rectification method containing contrastive learning and reconstruction results adjustment to further improve representation consistency. MuSiCNet is an ISMTS analysis framework that competitive with SOTA in three mainstream tasks consistently, including classification, interpolation, and forecasting.
A Survey on Incomplete Multi-label Learning: Recent Advances and Future Trends
Jun 10, 2024
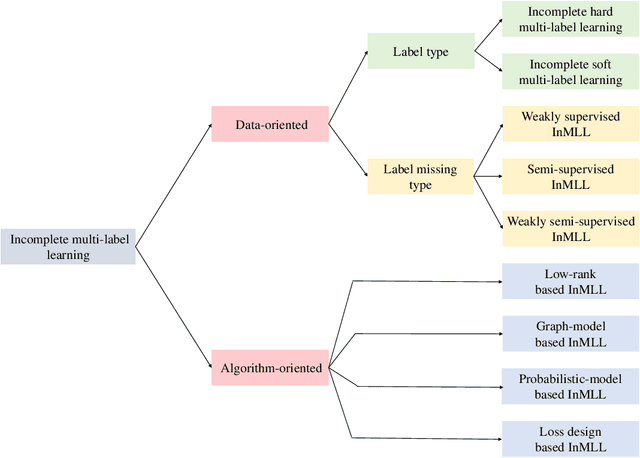
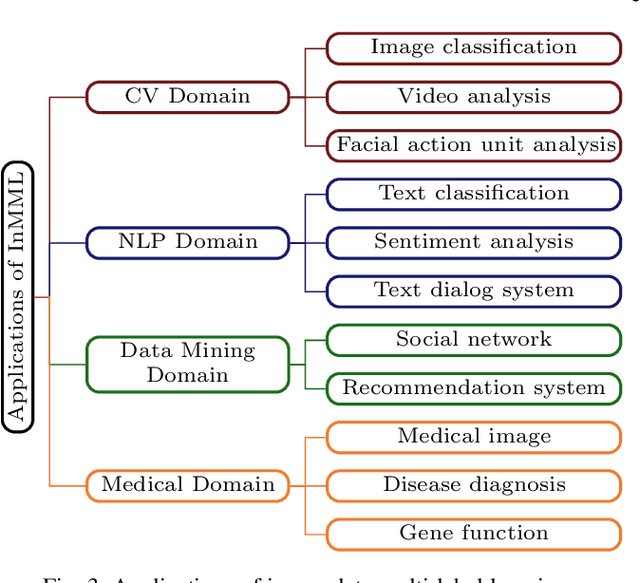
In reality, data often exhibit associations with multiple labels, making multi-label learning (MLL) become a prominent research topic. The last two decades have witnessed the success of MLL, which is indispensable from complete and accurate supervised information. However, obtaining such information in practice is always laborious and sometimes even impossible. To circumvent this dilemma, incomplete multi-label learning (InMLL) has emerged, aiming to learn from incomplete labeled data. To date, enormous InMLL works have been proposed to narrow the performance gap with complete MLL, whereas a systematic review for InMLL is still absent. In this paper, we not only attempt to fill the lacuna but also strive to pave the way for innovative research. Specifically, we retrospect the origin of InMLL, analyze the challenges of InMLL, and make a taxonomy of InMLL from the data-oriented and algorithm-oriented perspectives, respectively. Besides, we also present real applications of InMLL in various domains. More importantly, we highlight several potential future trends, including four open problems that are more in line with practice and three under-explored/unexplored techniques in addressing the challenges of InMLL, which may shed new light on developing novel research directions in the field of InMLL.
TimesURL: Self-supervised Contrastive Learning for Universal Time Series Representation Learning
Dec 25, 2023



Learning universal time series representations applicable to various types of downstream tasks is challenging but valuable in real applications. Recently, researchers have attempted to leverage the success of self-supervised contrastive learning (SSCL) in Computer Vision(CV) and Natural Language Processing(NLP) to tackle time series representation. Nevertheless, due to the special temporal characteristics, relying solely on empirical guidance from other domains may be ineffective for time series and difficult to adapt to multiple downstream tasks. To this end, we review three parts involved in SSCL including 1) designing augmentation methods for positive pairs, 2) constructing (hard) negative pairs, and 3) designing SSCL loss. For 1) and 2), we find that unsuitable positive and negative pair construction may introduce inappropriate inductive biases, which neither preserve temporal properties nor provide sufficient discriminative features. For 3), just exploring segment- or instance-level semantics information is not enough for learning universal representation. To remedy the above issues, we propose a novel self-supervised framework named TimesURL. Specifically, we first introduce a frequency-temporal-based augmentation to keep the temporal property unchanged. And then, we construct double Universums as a special kind of hard negative to guide better contrastive learning. Additionally, we introduce time reconstruction as a joint optimization objective with contrastive learning to capture both segment-level and instance-level information. As a result, TimesURL can learn high-quality universal representations and achieve state-of-the-art performance in 6 different downstream tasks, including short- and long-term forecasting, imputation, classification, anomaly detection and transfer learning.
Robustness Testing of Language Understanding in Dialog Systems
Dec 30, 2020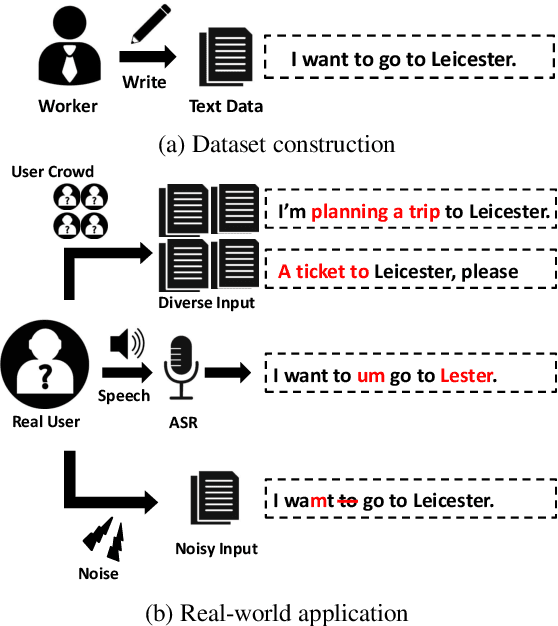


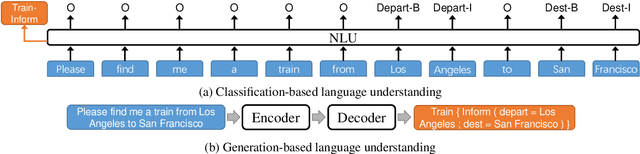
Most language understanding models in dialog systems are trained on a small amount of annotated training data, and evaluated in a small set from the same distribution. However, these models can lead to system failure or undesirable outputs when being exposed to natural perturbation in practice. In this paper, we conduct comprehensive evaluation and analysis with respect to the robustness of natural language understanding models, and introduce three important aspects related to language understanding in real-world dialog systems, namely, language variety, speech characteristics, and noise perturbation. We propose a model-agnostic toolkit LAUG to approximate natural perturbation for testing the robustness issues in dialog systems. Four data augmentation approaches covering the three aspects are assembled in LAUG, which reveals critical robustness issues in state-of-the-art models. The augmented dataset through LAUG can be used to facilitate future research on the robustness testing of language understanding in dialog systems.
A Hierarchical Framework for Relation Extraction with Reinforcement Learning
Nov 09, 2018

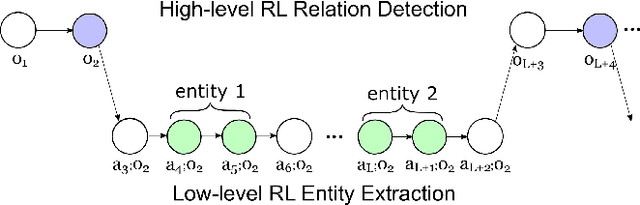

Most existing methods determine relation types only after all the entities have been recognized, thus the interaction between relation types and entity mentions is not fully modeled. This paper presents a novel paradigm to deal with relation extraction by regarding the related entities as the arguments of a relation. We apply a hierarchical reinforcement learning (HRL) framework in this paradigm to enhance the interaction between entity mentions and relation types. The whole extraction process is decomposed into a hierarchy of two-level RL policies for relation detection and entity extraction respectively, so that it is more feasible and natural to deal with overlapping relations. Our model was evaluated on public datasets collected via distant supervision, and results show that it gains better performance than existing methods and is more powerful for extracting overlapping relations.