 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness Testing of Language Understanding in Dialog Systems
Paper and Code
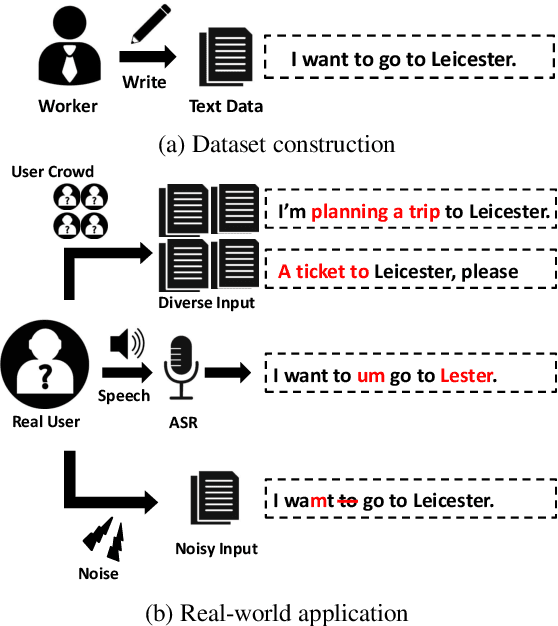


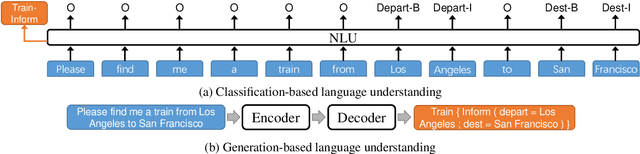
Most language understanding models in dialog systems are trained on a small amount of annotated training data, and evaluated in a small set from the same distribution. However, these models can lead to system failure or undesirable outputs when being exposed to natural perturbation in practice. In this paper, we conduct comprehensive evaluation and analysis with respect to the robustness of natural language understanding models, and introduce three important aspects related to language understanding in real-world dialog systems, namely, language variety, speech characteristics, and noise perturbation. We propose a model-agnostic toolkit LAUG to approximate natural perturbation for testing the robustness issues in dialog systems. Four data augmentation approaches covering the three aspects are assembled in LAUG, which reveals critical robustness issues in state-of-the-art models. The augmented dataset through LAUG can be used to facilitate future research on the robustness testing of language understanding in dialog systems.