 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChat-UniVi: Unified Visual Representation Empowers Large Language Models with Image and Video Understanding
Nov 14, 2023



Large language models have demonstrated impressive universal capabilities across a wide range of open-ended tasks and have extended their utility to encompass multimodal conversations. However, existing methods encounter challenges in effectively handling both image and video understanding, particularly with limited visual tokens. In this work, we introduce Chat-UniVi, a unified vision-language model capable of comprehending and engaging in conversations involving images and videos through a unified visual representation. Specifically, we employ a set of dynamic visual tokens to uniformly represent images and videos. This representation framework empowers the model to efficiently utilize a limited number of visual tokens to simultaneously capture the spatial details necessary for images and the comprehensive temporal relationship required for videos. Moreover, we leverage a multi-scale representation, enabling the model to perceive both high-level semantic concepts and low-level visual details. Notably, Chat-UniVi is trained on a mixed dataset containing both images and videos, allowing direct application to tasks involving both mediums without requiring any modifications. Extensive experimental results demonstrate that Chat-UniVi, as a unified model, consistently outperforms even existing methods exclusively designed for either images or videos.
Manual-Guided Dialogue for Flexible Conversational Agents
Aug 16, 2022
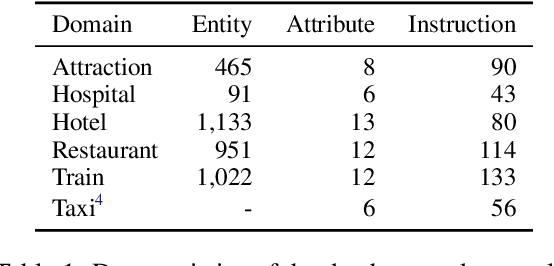


How to build and use dialogue data efficiently, and how to deploy models in different domains at scale can be two critical issues in building a task-oriented dialogue system. In this paper, we propose a novel manual-guided dialogue scheme to alleviate these problems, where the agent learns the tasks from both dialogue and manuals. The manual is an unstructured textual document that guides the agent in interacting with users and the database during the conversation. Our proposed scheme reduces the dependence of dialogue models on fine-grained domain ontology, and makes them more flexible to adapt to various domains. We then contribute a fully-annotated multi-domain dataset MagDial to support our scheme. It introduces three dialogue modeling subtasks: instruction matching, argument filling, and response generation. Modeling these subtasks is consistent with the human agent's behavior patterns. Experiments demonstrate that the manual-guided dialogue scheme improves data efficiency and domain scalability in building dialogue systems. The dataset and benchmark will be publicly available for promoting future research.
End-to-End Task-Oriented Dialog Modeling with Semi-Structured Knowledge Management
Jun 22, 2021
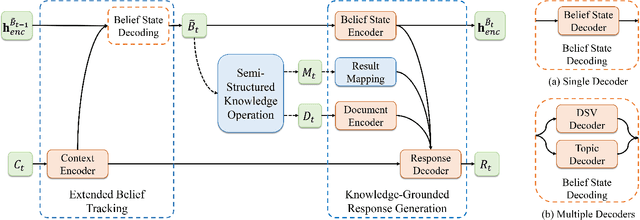
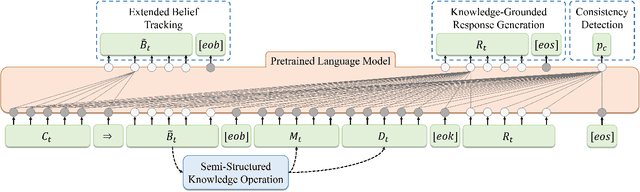

Current task-oriented dialog (TOD) systems mostly manage structured knowledge (e.g. databases and tables) to guide the goal-oriented conversations. However, they fall short of handling dialogs which also involve unstructured knowledge (e.g. reviews and documents). In this paper, we formulate a task of modeling TOD grounded on a fusion of structured and unstructured knowledge. To address this task, we propose a TOD system with semi-structured knowledge management, SeKnow, which extends the belief state to manage knowledge with both structured and unstructured contents. Furthermore, we introduce two implementations of SeKnow based on a non-pretrained sequence-to-sequence model and a pretrained language model, respectively. Both implementations use the end-to-end manner to jointly optimize dialog modeling grounded on structured and unstructured knowledge. We conduct experiments on the modified version of MultiWOZ 2.1 dataset, where dialogs are processed to involve semi-structured knowledge. Experimental results show that SeKnow has strong performances in both end-to-end dialog and intermediate knowledge management, compared to existing TOD systems and their extensions with pipeline knowledge management schemes.
HyKnow: End-to-End Task-Oriented Dialog Modeling with Hybrid Knowledge Management
Jun 02, 2021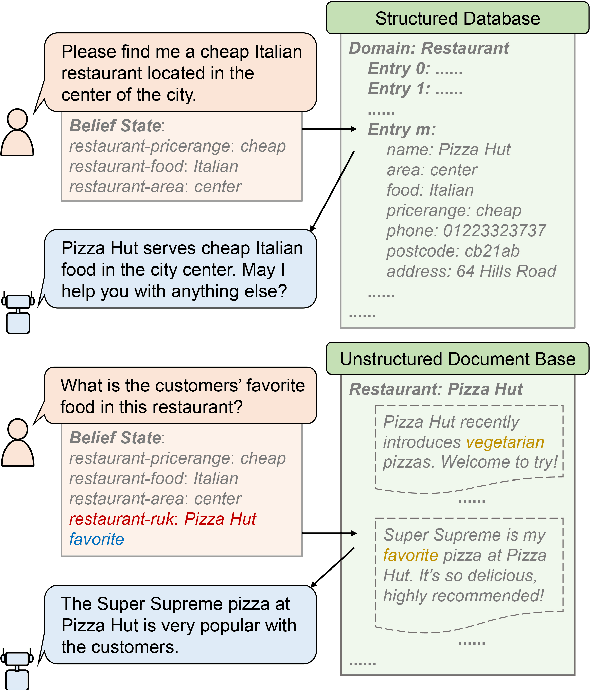
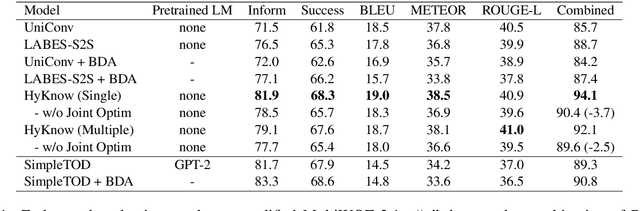


Task-oriented dialog (TOD) systems typically manage structured knowledge (e.g. ontologies and databases) to guide the goal-oriented conversations. However, they fall short of handling dialog turns grounded on unstructured knowledge (e.g. reviews and documents). In this paper, we formulate a task of modeling TOD grounded on both structured and unstructured knowledge. To address this task, we propose a TOD system with hybrid knowledge management, HyKnow. It extends the belief state to manage both structured and unstructured knowledge, and is the first end-to-end model that jointly optimizes dialog modeling grounded on these two kinds of knowledge. We conduct experiments on the modified version of MultiWOZ 2.1 dataset, where dialogs are grounded on hybrid knowledge. Experimental results show that HyKnow has strong end-to-end performance compared to existing TOD systems. It also outperforms the pipeline knowledge management schemes, with higher unstructured knowledge retrieval accuracy.
Robustness Testing of Language Understanding in Dialog Systems
Dec 30, 2020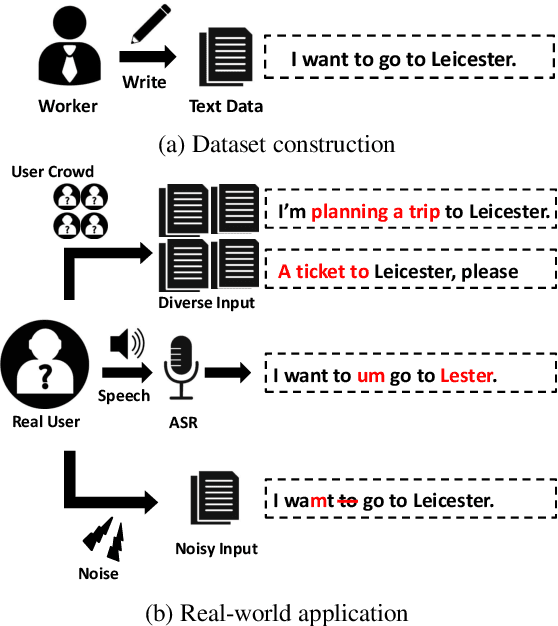


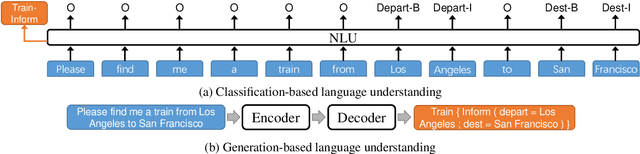
Most language understanding models in dialog systems are trained on a small amount of annotated training data, and evaluated in a small set from the same distribution. However, these models can lead to system failure or undesirable outputs when being exposed to natural perturbation in practice. In this paper, we conduct comprehensive evaluation and analysis with respect to the robustness of natural language understanding models, and introduce three important aspects related to language understanding in real-world dialog systems, namely, language variety, speech characteristics, and noise perturbation. We propose a model-agnostic toolkit LAUG to approximate natural perturbation for testing the robustness issues in dialog systems. Four data augmentation approaches covering the three aspects are assembled in LAUG, which reveals critical robustness issues in state-of-the-art models. The augmented dataset through LAUG can be used to facilitate future research on the robustness testing of language understanding in dialog systems.
ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning
Dec 30, 2020
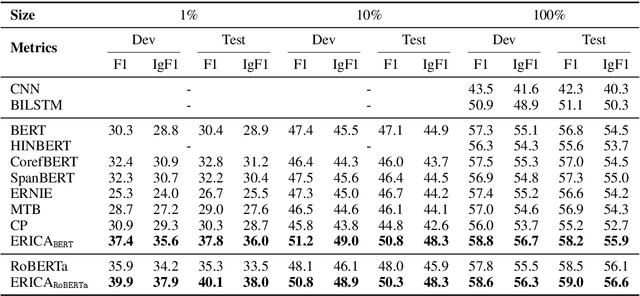
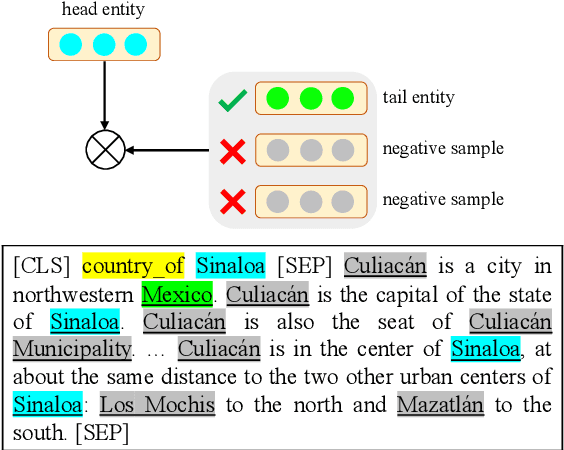
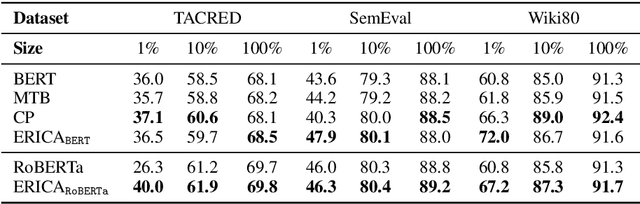
Pre-trained Language Models (PLMs) have shown strong performance in various downstream Natural Language Processing (NLP) tasks. However, PLMs still cannot well capture the factual knowledge in the text, which is crucial for understanding the whole text, especially for document-level language understanding tasks. To address this issue, we propose a novel contrastive learning framework named ERICA in pre-training phase to obtain a deeper understanding of the entities and their relations in text. Specifically, (1) to better understand entities, we propose an entity discrimination task that distinguishes which tail entity can be inferred by the given head entity and relation. (2) Besides, to better understand relations, we employ a relation discrimination task which distinguishes whether two entity pairs are close or not in relational semantics. Experimental results demonstrate that our proposed ERICA framework achieves consistent improvements on several document-level language understanding tasks, including relation extraction and reading comprehension, especially under low resource setting. Meanwhile, ERICA achieves comparable or better performance on sentence-level tasks. We will release the datasets, source codes and pre-trained language models for further research explorations.
Bridging the Gap between Conversational Reasoning and Interactive Recommendation
Oct 20, 2020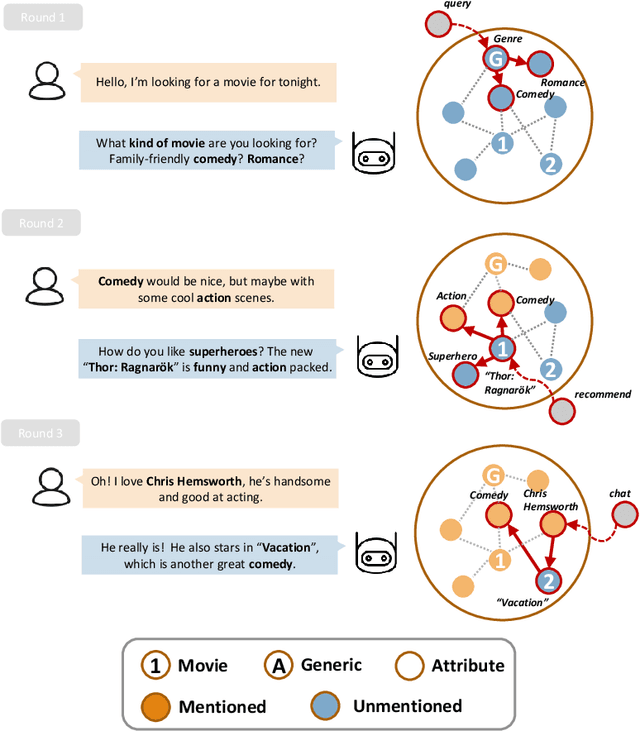

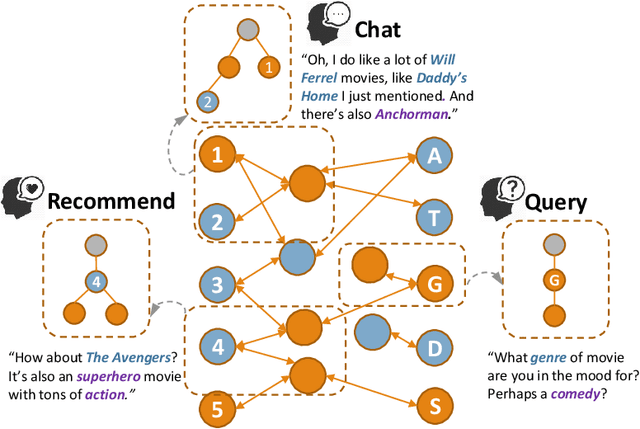
There have been growing interests in building a conversational recommender system, where the system simultaneously interacts with the user and explores the user's preference throughout conversational interactions. Recommendation and conversation were usually treated as two separate modules with limited information exchange in existing works, which hinders the capability of both systems: (1) dialog merely incorporated recommendation entities without being guided by an explicit recommendation-oriented policy; (2) recommendation utilized dialog only as a form of interaction instead of improving recommendation effectively. To address the above issues, we propose a novel recommender dialog model: CR-Walker. In order to view the two separate systems within a unified framework, we seek high-level mapping between hierarchical dialog acts and multi-hop knowledge graph reasoning. The model walks on a large-scale knowledge graph to form a reasoning tree at each turn, then mapped to dialog acts to guide response generation. With such a mapping mechanism as a bridge between recommendation and conversation, our framework maximizes the mutual benefit between two systems: dialog as an enhancement to recommendation quality and explainability, recommendation as a goal and enrichment to dialog semantics. Quantitative evaluation shows that our model excels in conversation informativeness and recommendation effectiveness, at the same time explainable on the policy level.
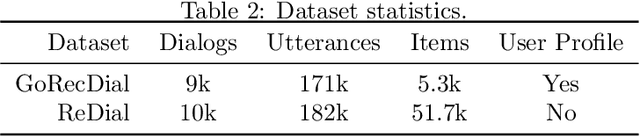
MultiWOZ 2.3: A multi-domain task-oriented dataset enhanced with annotation corrections and co-reference annotation
Oct 12, 2020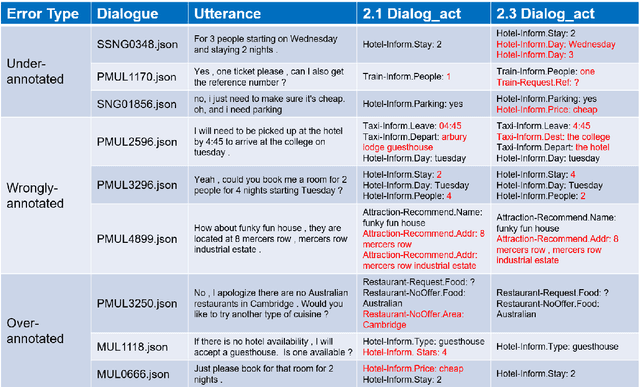
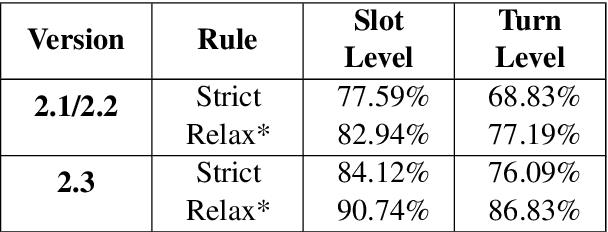

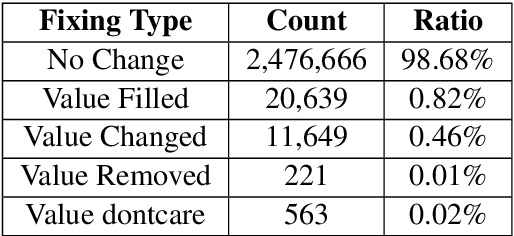
Task-oriented dialogue systems have made unprecedented progress with multiple state-of-the-art (SOTA) models underpinned by a number of publicly available MultiWOZ datasets. Dialogue state annotations are error-prone, leading to sub-optimal performance. Various efforts have been put in rectifying the annotation errors presented in the original MultiWOZ dataset. In this paper, we introduce MultiWOZ 2.3, in which we differentiate incorrect annotations in dialogue acts from dialogue states, identifying a lack of co-reference when publishing the updated dataset. To ensure consistency between dialogue acts and dialogue states, we implement co-reference features and unify annotations of dialogue acts and dialogue states. We update the state of the art performance of natural language understanding and dialog state tracking on MultiWOZ 2.3, where the results show significant improvements than on previous versions of MultiWOZ datasets (2.0-2.2).
Is Your Goal-Oriented Dialog Model Performing Really Well? Empirical Analysis of System-wise Evaluation
May 15, 2020



There is a growing interest in developing goal-oriented dialog systems which serve users in accomplishing complex tasks through multi-turn conversations. Although many methods are devised to evaluate and improve the performance of individual dialog components, there is a lack of comprehensive empirical study on how different components contribute to the overall performance of a dialog system. In this paper, we perform a system-wise evaluation and present an empirical analysis on different types of dialog systems which are composed of different modules in different settings. Our results show that (1) a pipeline dialog system trained using fine-grained supervision signals at different component levels often obtains better performance than the systems that use joint or end-to-end models trained on coarse-grained labels, (2) component-wise, single-turn evaluation results are not always consistent with the overall performance of a dialog system, and (3) despite the discrepancy between simulators and human users, simulated evaluation is still a valid alternative to the costly human evaluation especially in the early stage of development.
Multi-Agent Task-Oriented Dialog Policy Learning with Role-Aware Reward Decomposition
Apr 23, 2020

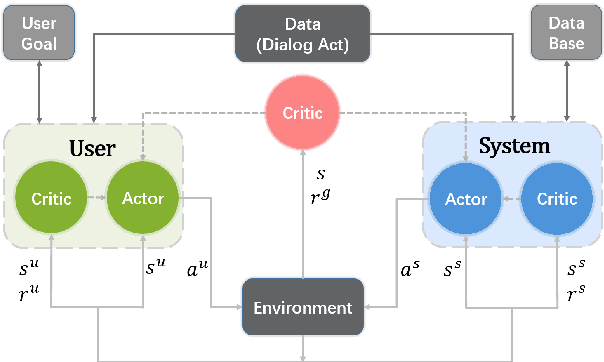
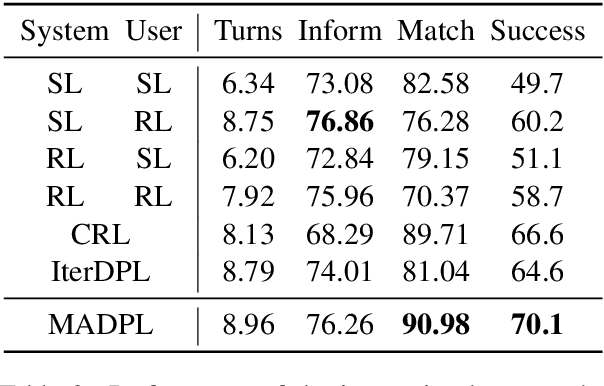
Many studies have applied reinforcement learning to train a dialog policy and show great promise these years. One common approach is to employ a user simulator to obtain a large number of simulated user experiences for reinforcement learning algorithms. However, modeling a realistic user simulator is challenging. A rule-based simulator requires heavy domain expertise for complex tasks, and a data-driven simulator requires considerable data and it is even unclear how to evaluate a simulator. To avoid explicitly building a user simulator beforehand, we propose Multi-Agent Dialog Policy Learning, which regards both the system and the user as the dialog agents. Two agents interact with each other and are jointly learned simultaneously. The method uses the actor-critic framework to facilitate pretraining and improve scalability. We also propose Hybrid Value Network for the role-aware reward decomposition to integrate role-specific domain knowledge of each agent in the task-oriented dialog. Results show that our method can successfully build a system policy and a user policy simultaneously, and two agents can achieve a high task success rate through conversational interaction.