 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Memorize and When to Stop: Gated Recurrent Memory for Long-Context Reasoning
Feb 11, 2026While reasoning over long context is crucial for various real-world applications, it remains challenging for large language models (LLMs) as they suffer from performance degradation as the context length grows. Recent work MemAgent has tried to tackle this by processing context chunk-by-chunk in an RNN-like loop and updating a textual memory for final answering. However, this naive recurrent memory update faces two crucial drawbacks: (i) memory can quickly explode because it can update indiscriminately, even on evidence-free chunks; and (ii) the loop lacks an exit mechanism, leading to unnecessary computation after even sufficient evidence is collected. To address these issues, we propose GRU-Mem, which incorporates two text-controlled gates for more stable and efficient long-context reasoning. Specifically, in GRU-Mem, the memory only updates when the update gate is open and the recurrent loop will exit immediately once the exit gate is open. To endow the model with such capabilities, we introduce two reward signals $r^{\text{update}}$ and $r^{\text{exit}}$ within end-to-end RL, rewarding the correct updating and exiting behaviors respectively. Experiments on various long-context reasoning tasks demonstrate the effectiveness and efficiency of GRU-Mem, which generally outperforms the vanilla MemAgent with up to 400\% times inference speed acceleration.
Reinforcing Chain-of-Thought Reasoning with Self-Evolving Rubrics
Feb 11, 2026Despite chain-of-thought (CoT) playing crucial roles in LLM reasoning, directly rewarding it is difficult: training a reward model demands heavy human labeling efforts, and static RMs struggle with evolving CoT distributions and reward hacking. These challenges motivate us to seek an autonomous CoT rewarding approach that requires no human annotation efforts and can evolve gradually. Inspired by recent self-evolving training methods, we propose \textbf{RLCER} (\textbf{R}einforcement \textbf{L}earning with \textbf{C}oT Supervision via Self-\textbf{E}volving \textbf{R}ubrics), which enhances the outcome-centric RLVR by rewarding CoTs with self-proposed and self-evolving rubrics. We show that self-proposed and self-evolving rubrics provide reliable CoT supervision signals even without outcome rewards, enabling RLCER to outperform outcome-centric RLVR. Moreover, when used as in-prompt hints, these self-proposed rubrics further improve inference-time performance.
General Debiasing for Graph-based Collaborative Filtering via Adversarial Graph Dropout
Feb 21, 2024Graph neural networks (GNNs) have shown impressive performance in recommender systems, particularly in collaborative filtering (CF). The key lies in aggregating neighborhood information on a user-item interaction graph to enhance user/item representations. However, we have discovered that this aggregation mechanism comes with a drawback, which amplifies biases present in the interaction graph. For instance, a user's interactions with items can be driven by both unbiased true interest and various biased factors like item popularity or exposure. However, the current aggregation approach combines all information, both biased and unbiased, leading to biased representation learning. Consequently, graph-based recommenders can learn distorted views of users/items, hindering the modeling of their true preferences and generalizations. To address this issue, we introduce a novel framework called Adversarial Graph Dropout (AdvDrop). It differentiates between unbiased and biased interactions, enabling unbiased representation learning. For each user/item, AdvDrop employs adversarial learning to split the neighborhood into two views: one with bias-mitigated interactions and the other with bias-aware interactions. After view-specific aggregation, AdvDrop ensures that the bias-mitigated and bias-aware representations remain invariant, shielding them from the influence of bias. We validate AdvDrop's effectiveness on five public datasets that cover both general and specific biases, demonstrating significant improvements. Furthermore, our method exhibits meaningful separation of subgraphs and achieves unbiased representations for graph-based CF models, as revealed by in-depth analysis. Our code is publicly available at https://github.com/Arthurma71/AdvDrop.
Robust Collaborative Filtering to Popularity Distribution Shift
Oct 16, 2023



In leading collaborative filtering (CF) models, representations of users and items are prone to learn popularity bias in the training data as shortcuts. The popularity shortcut tricks are good for in-distribution (ID) performance but poorly generalized to out-of-distribution (OOD) data, i.e., when popularity distribution of test data shifts w.r.t. the training one. To close the gap, debiasing strategies try to assess the shortcut degrees and mitigate them from the representations. However, there exist two deficiencies: (1) when measuring the shortcut degrees, most strategies only use statistical metrics on a single aspect (i.e., item frequency on item and user frequency on user aspect), failing to accommodate the compositional degree of a user-item pair; (2) when mitigating shortcuts, many strategies assume that the test distribution is known in advance. This results in low-quality debiased representations. Worse still, these strategies achieve OOD generalizability with a sacrifice on ID performance. In this work, we present a simple yet effective debiasing strategy, PopGo, which quantifies and reduces the interaction-wise popularity shortcut without any assumptions on the test data. It first learns a shortcut model, which yields a shortcut degree of a user-item pair based on their popularity representations. Then, it trains the CF model by adjusting the predictions with the interaction-wise shortcut degrees. By taking both causal- and information-theoretical looks at PopGo, we can justify why it encourages the CF model to capture the critical popularity-agnostic features while leaving the spurious popularity-relevant patterns out. We use PopGo to debias two high-performing CF models (MF, LightGCN) on four benchmark datasets. On both ID and OOD test sets, PopGo achieves significant gains over the state-of-the-art debiasing strategies (e.g., DICE, MACR).
Discovering Dynamic Causal Space for DAG Structure Learning
Jun 05, 2023
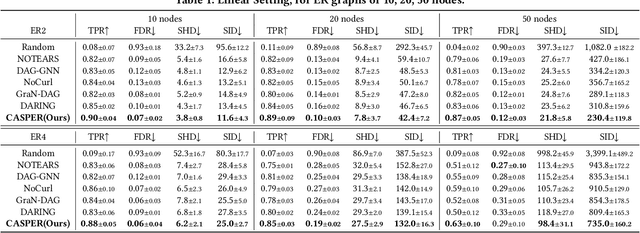

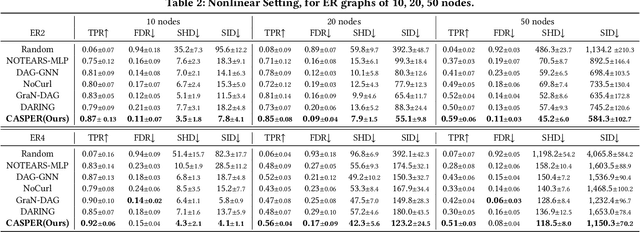
Discovering causal structure from purely observational data (i.e., causal discovery), aiming to identify causal relationships among variables, is a fundamental task in machine learning. The recent invention of differentiable score-based DAG learners is a crucial enabler, which reframes the combinatorial optimization problem into a differentiable optimization with a DAG constraint over directed graph space. Despite their great success, these cutting-edge DAG learners incorporate DAG-ness independent score functions to evaluate the directed graph candidates, lacking in considering graph structure. As a result, measuring the data fitness alone regardless of DAG-ness inevitably leads to discovering suboptimal DAGs and model vulnerabilities. Towards this end, we propose a dynamic causal space for DAG structure learning, coined CASPER, that integrates the graph structure into the score function as a new measure in the causal space to faithfully reflect the causal distance between estimated and ground truth DAG. CASPER revises the learning process as well as enhances the DAG structure learning via adaptive attention to DAG-ness. Grounded by empirical visualization, CASPER, as a space, satisfies a series of desired properties, such as structure awareness and noise robustness. Extensive experiments on both synthetic and real-world datasets clearly validate the superiority of our CASPER over the state-of-the-art causal discovery methods in terms of accuracy and robustness.
Boosting Differentiable Causal Discovery via Adaptive Sample Reweighting
Mar 06, 2023



Under stringent model type and variable distribution assumptions, differentiable score-based causal discovery methods learn a directed acyclic graph (DAG) from observational data by evaluating candidate graphs over an average score function. Despite great success in low-dimensional linear systems, it has been observed that these approaches overly exploit easier-to-fit samples, thus inevitably learning spurious edges. Worse still, inherent mostly in these methods the common homogeneity assumption can be easily violated, due to the widespread existence of heterogeneous data in the real world, resulting in performance vulnerability when noise distributions vary. We propose a simple yet effective model-agnostic framework to boost causal discovery performance by dynamically learning the adaptive weights for the Reweighted Score function, ReScore for short, where the weights tailor quantitatively to the importance degree of each sample. Intuitively, we leverage the bilevel optimization scheme to \wx{alternately train a standard DAG learner and reweight samples -- that is, upweight the samples the learner fails to fit and downweight the samples that the learner easily extracts the spurious information from. Extensive experiments on both synthetic and real-world datasets are carried out to validate the effectiveness of ReScore. We observe consistent and significant boosts in structure learning performance. Furthermore, we visualize that ReScore concurrently mitigates the influence of spurious edges and generalizes to heterogeneous data. Finally, we perform the theoretical analysis to guarantee the structure identifiability and the weight adaptive properties of ReScore in linear systems. Our codes are available at https://github.com/anzhang314/ReScore.
Extract, Denoise, and Enforce: Evaluating and Predicting Lexical Constraints for Conditional Text Generation
Apr 18, 2021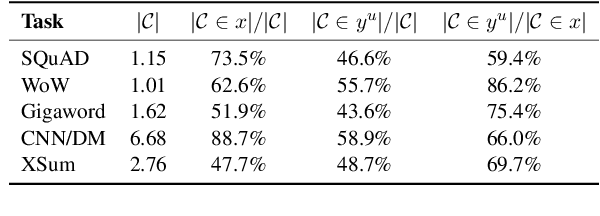
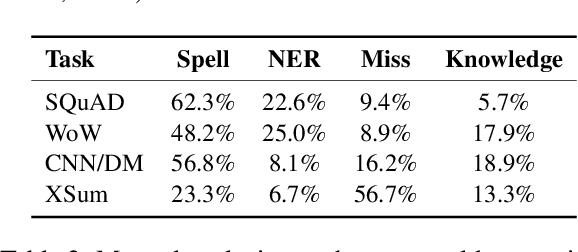
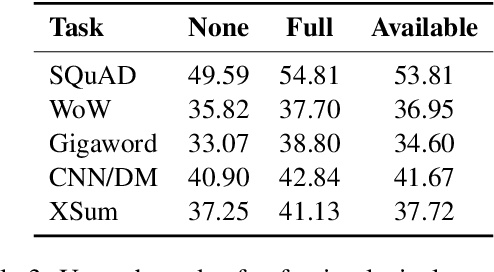
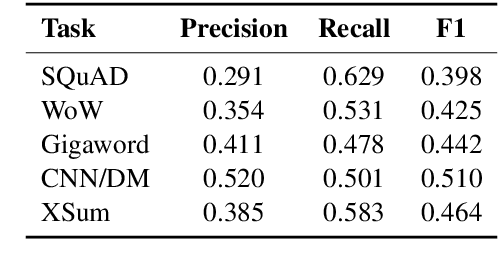
Recently, pre-trained language models (PLMs) have dominated conditional text generation tasks. Given the impressive performance and prevalence of the PLMs, it is seemingly natural to assume that they could figure out what to attend to in the input and what to include in the output via seq2seq learning without more guidance than the training input/output pairs. However, a rigorous study regarding the above assumption is still lacking. In this paper, we present a systematic analysis of conditional generation to study whether current PLMs are good enough for preserving important concepts in the input and to what extent explicitly guiding generation with lexical constraints is beneficial. We conduct extensive analytical experiments on a range of conditional generation tasks and try to answer in what scenarios guiding generation with lexical constraints works well and why. We then propose a framework for automatic constraint extraction, denoising, and enforcement that is shown to perform comparably or better than unconstrained generation. We hope that our findings could serve as a reference when determining whether it is appropriate and worthwhile to use explicit constraints for a specific task or dataset.\footnote{Our code is available at \url{https://github.com/morningmoni/LCGen-eval}.}
Bridging the Gap between Conversational Reasoning and Interactive Recommendation
Oct 20, 2020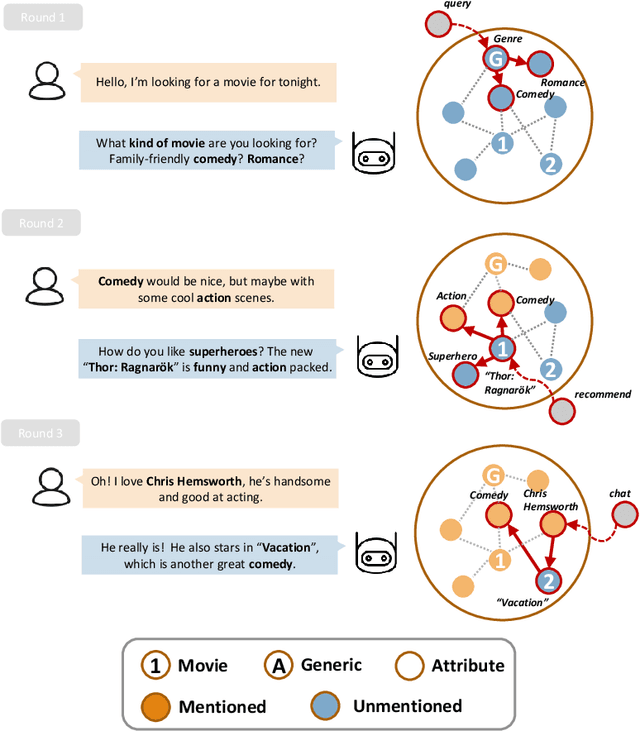

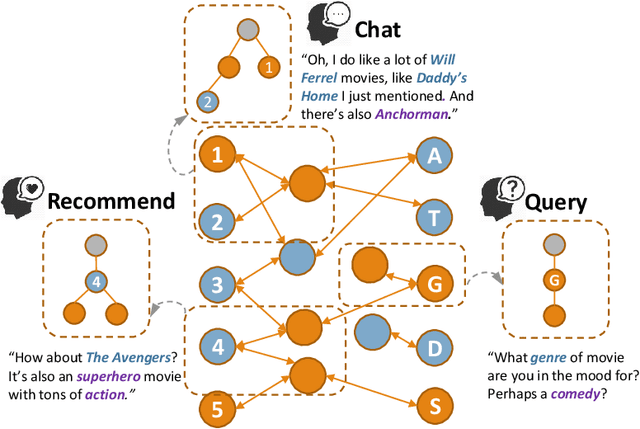
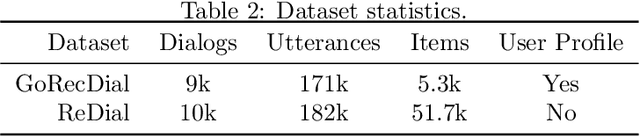
There have been growing interests in building a conversational recommender system, where the system simultaneously interacts with the user and explores the user's preference throughout conversational interactions. Recommendation and conversation were usually treated as two separate modules with limited information exchange in existing works, which hinders the capability of both systems: (1) dialog merely incorporated recommendation entities without being guided by an explicit recommendation-oriented policy; (2) recommendation utilized dialog only as a form of interaction instead of improving recommendation effectively. To address the above issues, we propose a novel recommender dialog model: CR-Walker. In order to view the two separate systems within a unified framework, we seek high-level mapping between hierarchical dialog acts and multi-hop knowledge graph reasoning. The model walks on a large-scale knowledge graph to form a reasoning tree at each turn, then mapped to dialog acts to guide response generation. With such a mapping mechanism as a bridge between recommendation and conversation, our framework maximizes the mutual benefit between two systems: dialog as an enhancement to recommendation quality and explainability, recommendation as a goal and enrichment to dialog semantics. Quantitative evaluation shows that our model excels in conversation informativeness and recommendation effectiveness, at the same time explainable on the policy level.