 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
FactCG: Enhancing Fact Checkers with Graph-Based Multi-Hop Data
Jan 28, 2025Prior research on training grounded factuality classification models to detect hallucinations in large language models (LLMs) has relied on public natural language inference (NLI) data and synthetic data. However, conventional NLI datasets are not well-suited for document-level reasoning, which is critical for detecting LLM hallucinations. Recent approaches to document-level synthetic data generation involve iteratively removing sentences from documents and annotating factuality using LLM-based prompts. While effective, this method is computationally expensive for long documents and limited by the LLM's capabilities. In this work, we analyze the differences between existing synthetic training data used in state-of-the-art models and real LLM output claims. Based on our findings, we propose a novel approach for synthetic data generation, CG2C, that leverages multi-hop reasoning on context graphs extracted from documents. Our fact checker model, FactCG, demonstrates improved performance with more connected reasoning, using the same backbone models. Experiments show it even outperforms GPT-4-o on the LLM-Aggrefact benchmark with much smaller model size.
InvisMark: Invisible and Robust Watermarking for AI-generated Image Provenance
Nov 19, 2024



The proliferation of AI-generated images has intensified the need for robust content authentication methods. We present InvisMark, a novel watermarking technique designed for high-resolution AI-generated images. Our approach leverages advanced neural network architectures and training strategies to embed imperceptible yet highly robust watermarks. InvisMark achieves state-of-the-art performance in imperceptibility (PSNR$\sim$51, SSIM $\sim$ 0.998) while maintaining over 97\% bit accuracy across various image manipulations. Notably, we demonstrate the successful encoding of 256-bit watermarks, significantly expanding payload capacity while preserving image quality. This enables the embedding of UUIDs with error correction codes, achieving near-perfect decoding success rates even under challenging image distortions. We also address potential vulnerabilities against advanced attacks and propose mitigation strategies. By combining high imperceptibility, extended payload capacity, and resilience to manipulations, InvisMark provides a robust foundation for ensuring media provenance in an era of increasingly sophisticated AI-generated content. Source code of this paper is available at: https://github.com/microsoft/InvisMark.
SLM Meets LLM: Balancing Latency, Interpretability and Consistency in Hallucination Detection
Aug 22, 2024
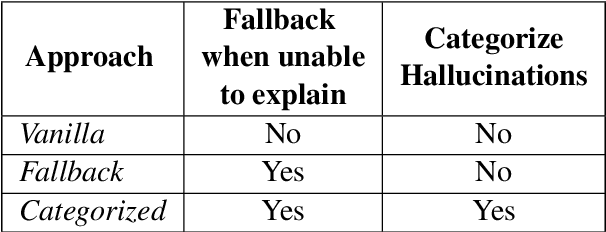


Large language models (LLMs) are highly capable but face latency challenges in real-time applications, such as conducting online hallucination detection. To overcome this issue, we propose a novel framework that leverages a small language model (SLM) classifier for initial detection, followed by a LLM as constrained reasoner to generate detailed explanations for detected hallucinated content. This study optimizes the real-time interpretable hallucination detection by introducing effective prompting techniques that align LLM-generated explanations with SLM decisions. Empirical experiment results demonstrate its effectiveness, thereby enhancing the overall user experience.
Chain of Natural Language Inference for Reducing Large Language Model Ungrounded Hallucinations
Oct 09, 2023Large language models (LLMs) can generate fluent natural language texts when given relevant documents as background context. This ability has attracted considerable interest in developing industry applications of LLMs. However, LLMs are prone to generate hallucinations that are not supported by the provided sources. In this paper, we propose a hierarchical framework to detect and mitigate such ungrounded hallucination. Our framework uses Chain of Natural Language Inference (CoNLI) for hallucination detection and hallucination reduction via post-editing. Our approach achieves state-of-the-art performance on hallucination detection and enhances text quality through rewrite, using LLMs without any fine-tuning or domain-specific prompt engineering. We show that this simple plug-and-play framework can serve as an effective choice for hallucination detection and reduction, achieving competitive performance across various contexts.
Extract, Denoise, and Enforce: Evaluating and Predicting Lexical Constraints for Conditional Text Generation
Apr 18, 2021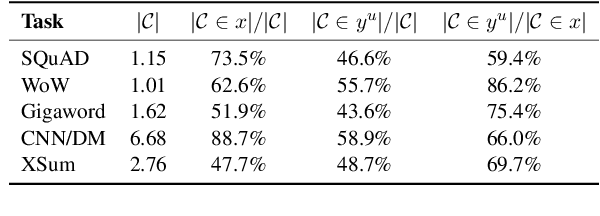
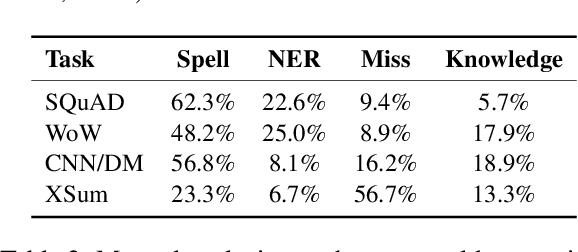
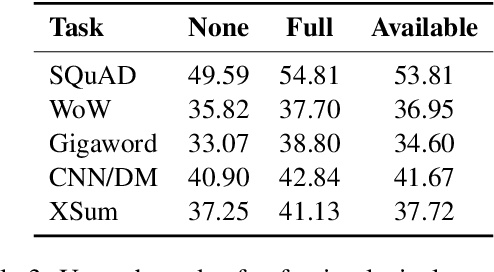
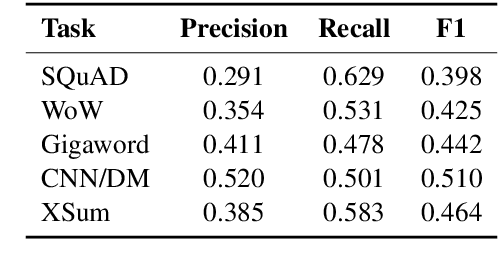
Recently, pre-trained language models (PLMs) have dominated conditional text generation tasks. Given the impressive performance and prevalence of the PLMs, it is seemingly natural to assume that they could figure out what to attend to in the input and what to include in the output via seq2seq learning without more guidance than the training input/output pairs. However, a rigorous study regarding the above assumption is still lacking. In this paper, we present a systematic analysis of conditional generation to study whether current PLMs are good enough for preserving important concepts in the input and to what extent explicitly guiding generation with lexical constraints is beneficial. We conduct extensive analytical experiments on a range of conditional generation tasks and try to answer in what scenarios guiding generation with lexical constraints works well and why. We then propose a framework for automatic constraint extraction, denoising, and enforcement that is shown to perform comparably or better than unconstrained generation. We hope that our findings could serve as a reference when determining whether it is appropriate and worthwhile to use explicit constraints for a specific task or dataset.\footnote{Our code is available at \url{https://github.com/morningmoni/LCGen-eval}.}
Learning to Reason in Round-based Games: Multi-task Sequence Generation for Purchasing Decision Making in First-person Shooters
Aug 12, 2020
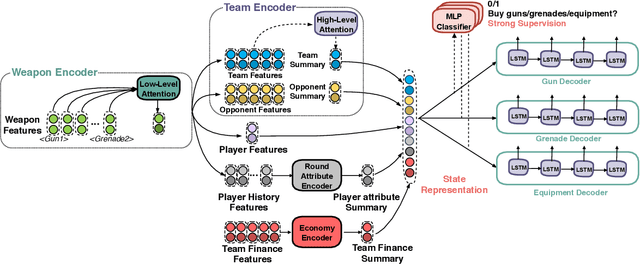

Sequential reasoning is a complex human ability, with extensive previous research focusing on gaming AI in a single continuous game, round-based decision makings extending to a sequence of games remain less explored. Counter-Strike: Global Offensive (CS:GO), as a round-based game with abundant expert demonstrations, provides an excellent environment for multi-player round-based sequential reasoning. In this work, we propose a Sequence Reasoner with Round Attribute Encoder and Multi-Task Decoder to interpret the strategies behind the round-based purchasing decisions. We adopt few-shot learning to sample multiple rounds in a match, and modified model agnostic meta-learning algorithm Reptile for the meta-learning loop. We formulate each round as a multi-task sequence generation problem. Our state representations combine action encoder, team encoder, player features, round attribute encoder, and economy encoders to help our agent learn to reason under this specific multi-player round-based scenario. A complete ablation study and comparison with the greedy approach certify the effectiveness of our model. Our research will open doors for interpretable AI for understanding episodic and long-term purchasing strategies beyond the gaming community.
Learning Collaborative Agents with Rule Guidance for Knowledge Graph Reasoning
May 01, 2020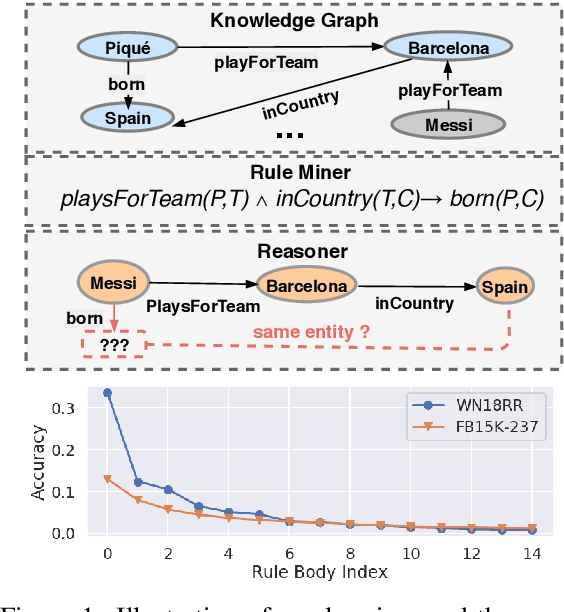
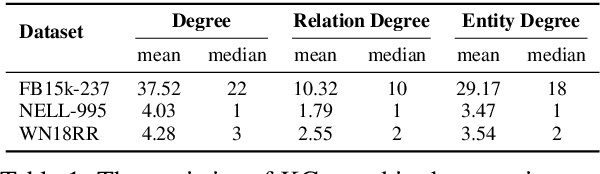
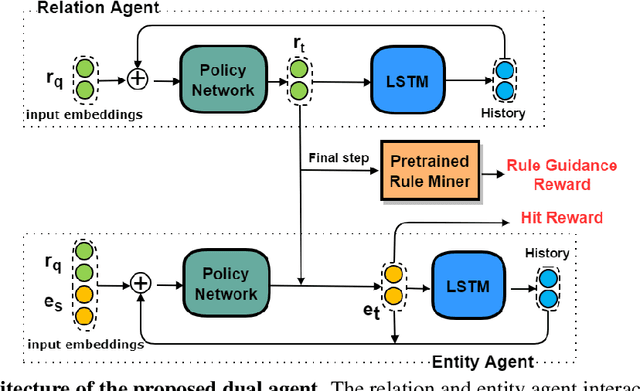
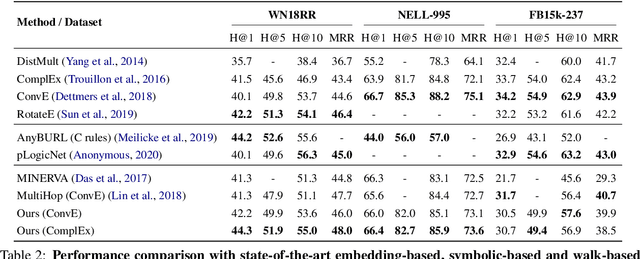
Walk-based models have shown their unique advantages in knowledge graph (KG) reasoning by achieving state-of-the-art performance while allowing for explicit visualization of the decision sequence. However, the sparse reward signals offered by the KG during a traversal are often insufficient to guide a sophisticated reinforcement learning (RL) model. An alternate approach to KG reasoning is using traditional symbolic methods (e.g., rule induction), which achieve high precision without learning but are hard to generalize due to the limitation of symbolic representation. In this paper, we propose to fuse these two paradigms to get the best of both worlds. Our method leverages high-quality rules generated by symbolic-based methods to provide reward supervision for walk-based agents. Due to the structure of symbolic rules with their entity variables, we can separate our walk-based agent into two sub-agents thus allowing for additional efficiency. Experiments on public datasets demonstrate that walk-based models can benefit from rule guidance significantly.
Deep Reinforcement Learning with Distributional Semantic Rewards for Abstractive Summarization
Sep 10, 2019
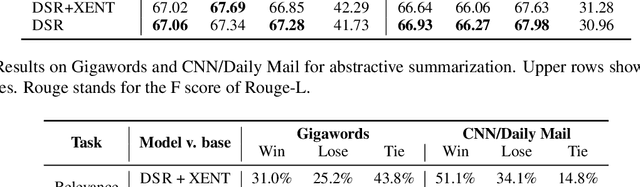
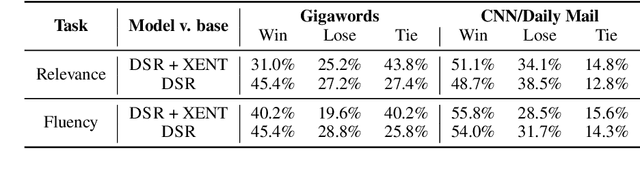
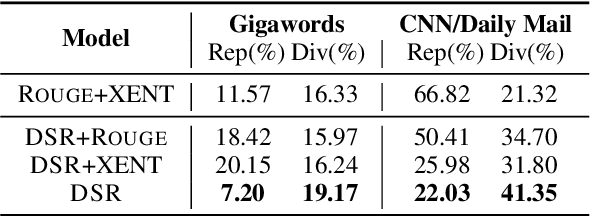
Deep reinforcement learning (RL) has been a commonly-used strategy for the abstractive summarization task to address both the exposure bias and non-differentiable task issues. However, the conventional reward Rouge-L simply looks for exact n-grams matches between candidates and annotated references, which inevitably makes the generated sentences repetitive and incoherent. In this paper, instead of Rouge-L, we explore the practicability of utilizing the distributional semantics to measure the matching degrees. With distributional semantics, sentence-level evaluation can be obtained, and semantically-correct phrases can also be generated without being limited to the surface form of the reference sentences. Human judgments on Gigaword and CNN/Daily Mail datasets show that our proposed distributional semantics reward (DSR) has distinct superiority in capturing the lexical and compositional diversity of natural language.
Imposing Label-Relational Inductive Bias for Extremely Fine-Grained Entity Typing
Mar 06, 2019
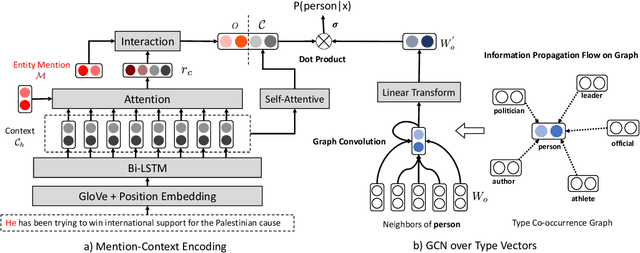
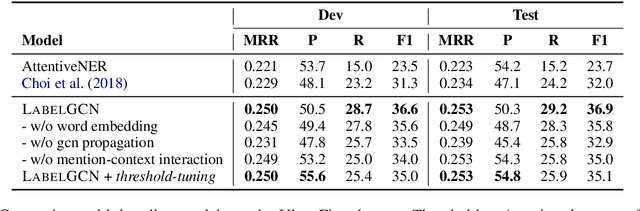
Existing entity typing systems usually exploit the type hierarchy provided by knowledge base (KB) schema to model label correlations and thus improve the overall performance. Such techniques, however, are not directly applicable to more open and practical scenarios where the type set is not restricted by KB schema and includes a vast number of free-form types. To model the underly-ing label correlations without access to manually annotated label structures, we introduce a novel label-relational inductive bias, represented by a graph propagation layer that effectively encodes both global label co-occurrence statistics and word-level similarities.On a large dataset with over 10,000 free-form types, the graph-enhanced model equipped with an attention-based matching module is able to achieve a much higher recall score while maintaining a high-level precision. Specifically, it achieves a 15.3% relative F1 improvement and also less inconsistency in the outputs. We further show that a simple modification of our proposed graph layer can also improve the performance on a conventional and widely-tested dataset that only includes KB-schema types.