 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrative Question Answering with Cutting-Edge Open-Domain QA Techniques: A Comprehensive Study
Jun 07, 2021



Recent advancements in open-domain question answering (ODQA), i.e., finding answers from large open-domain corpus like Wikipedia, have led to human-level performance on many datasets. However, progress in QA over book stories (Book QA) lags behind despite its similar task formulation to ODQA. This work provides a comprehensive and quantitative analysis about the difficulty of Book QA: (1) We benchmark the research on the NarrativeQA dataset with extensive experiments with cutting-edge ODQA techniques. This quantifies the challenges Book QA poses, as well as advances the published state-of-the-art with a $\sim$7\% absolute improvement on Rouge-L. (2) We further analyze the detailed challenges in Book QA through human studies.\footnote{\url{https://github.com/gorov/BookQA}.} Our findings indicate that the event-centric questions dominate this task, which exemplifies the inability of existing QA models to handle event-oriented scenarios.
Augmenting Policy Learning with Routines Discovered from a Demonstration
Dec 24, 2020
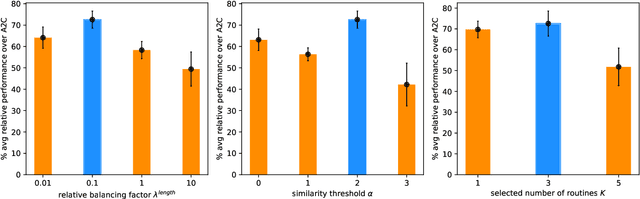
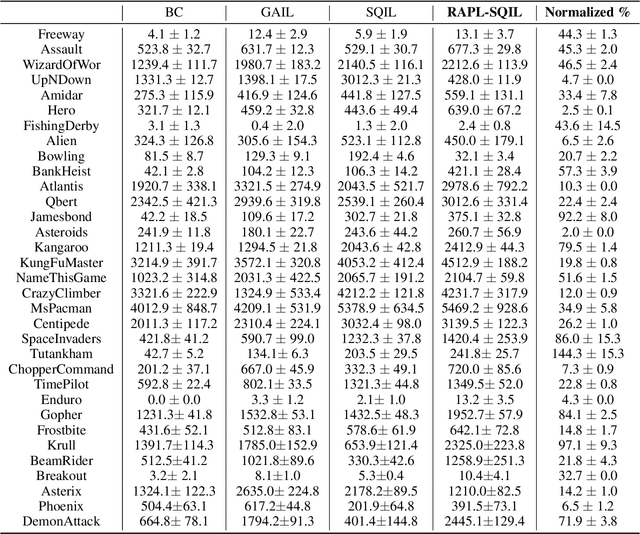
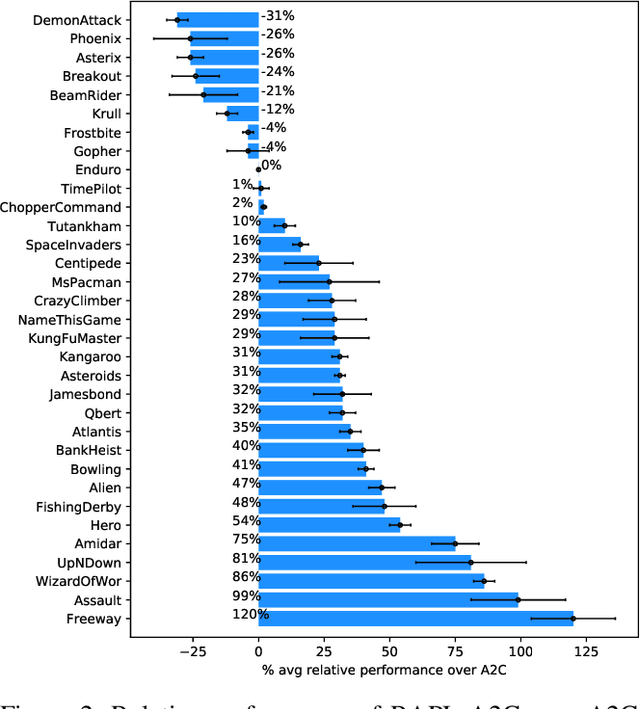
Humans can abstract prior knowledge from very little data and use it to boost skill learning. In this paper, we propose routine-augmented policy learning (RAPL), which discovers routines composed of primitive actions from a single demonstration and uses discovered routines to augment policy learning. To discover routines from the demonstration, we first abstract routine candidates by identifying grammar over the demonstrated action trajectory. Then, the best routines measured by length and frequency are selected to form a routine library. We propose to learn policy simultaneously at primitive-level and routine-level with discovered routines, leveraging the temporal structure of routines. Our approach enables imitating expert behavior at multiple temporal scales for imitation learning and promotes reinforcement learning exploration. Extensive experiments on Atari games demonstrate that RAPL improves the state-of-the-art imitation learning method SQIL and reinforcement learning method A2C. Further, we show that discovered routines can generalize to unseen levels and difficulties on the CoinRun benchmark.
Deriving Commonsense Inference Tasks from Interactive Fictions
Oct 19, 2020

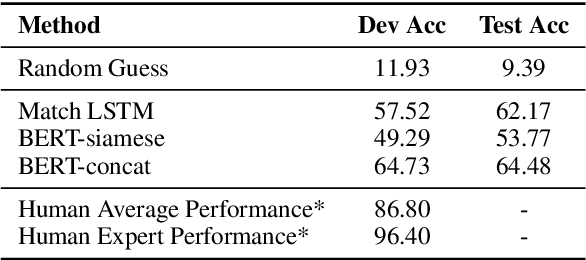
Commonsense reasoning simulates the human ability to make presumptions about our physical world, and it is an indispensable cornerstone in building general AI systems. We propose a new commonsense reasoning dataset based on human's interactive fiction game playings as human players demonstrate plentiful and diverse commonsense reasoning. The new dataset mitigates several limitations of the prior art. Experiments show that our task is solvable to human experts with sufficient commonsense knowledge but poses challenges to existing machine reading models, with a big performance gap of more than 30%.
Interactive Fiction Game Playing as Multi-Paragraph Reading Comprehension with Reinforcement Learning
Oct 05, 2020
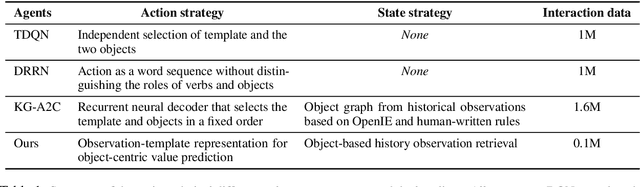
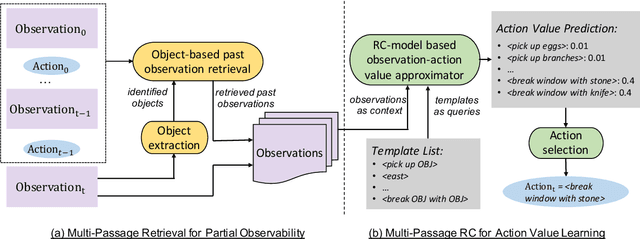
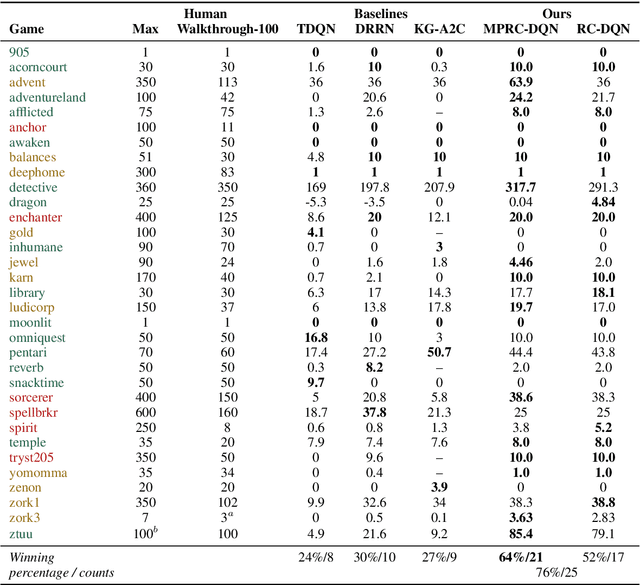
Interactive Fiction (IF) games with real human-written natural language texts provide a new natural evaluation for language understanding techniques. In contrast to previous text games with mostly synthetic texts, IF games pose language understanding challenges on the human-written textual descriptions of diverse and sophisticated game worlds and language generation challenges on the action command generation from less restricted combinatorial space. We take a novel perspective of IF game solving and re-formulate it as Multi-Passage Reading Comprehension (MPRC) tasks. Our approaches utilize the context-query attention mechanisms and the structured prediction in MPRC to efficiently generate and evaluate action outputs and apply an object-centric historical observation retrieval strategy to mitigate the partial observability of the textual observations. Extensive experiments on the recent IF benchmark (Jericho) demonstrate clear advantages of our approaches achieving high winning rates and low data requirements compared to all previous approaches. Our source code is available at: https://github.com/XiaoxiaoGuo/rcdqn.
Frustratingly Hard Evidence Retrieval for QA Over Books
Jul 20, 2020



A lot of progress has been made to improve question answering (QA) in recent years, but the special problem of QA over narrative book stories has not been explored in-depth. We formulate BookQA as an open-domain QA task given its similar dependency on evidence retrieval. We further investigate how state-of-the-art open-domain QA approaches can help BookQA. Besides achieving state-of-the-art on the NarrativeQA benchmark, our study also reveals the difficulty of evidence retrieval in books with a wealth of experiments and analysis - which necessitates future effort on novel solutions for evidence retrieval in BookQA.
Learning to Recover Reasoning Chains for Multi-Hop Question Answering via Cooperative Games
Apr 06, 2020
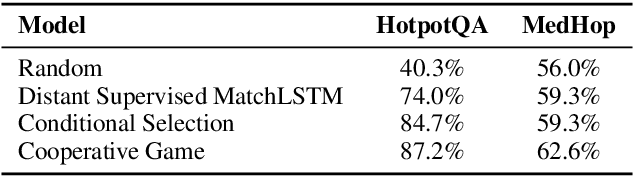


We propose the new problem of learning to recover reasoning chains from weakly supervised signals, i.e., the question-answer pairs. We propose a cooperative game approach to deal with this problem, in which how the evidence passages are selected and how the selected passages are connected are handled by two models that cooperate to select the most confident chains from a large set of candidates (from distant supervision). For evaluation, we created benchmarks based on two multi-hop QA datasets, HotpotQA and MedHop; and hand-labeled reasoning chains for the latter. The experimental results demonstrate the effectiveness of our proposed approach.
Drill-down: Interactive Retrieval of Complex Scenes using Natural Language Queries
Nov 10, 2019

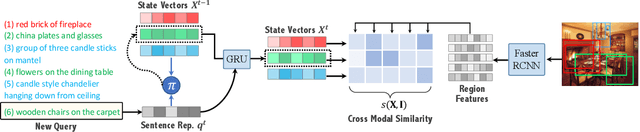
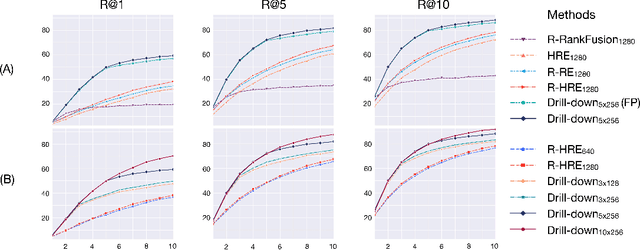
This paper explores the task of interactive image retrieval using natural language queries, where a user progressively provides input queries to refine a set of retrieval results. Moreover, our work explores this problem in the context of complex image scenes containing multiple objects. We propose Drill-down, an effective framework for encoding multiple queries with an efficient compact state representation that significantly extends current methods for single-round image retrieval. We show that using multiple rounds of natural language queries as input can be surprisingly effective to find arbitrarily specific images of complex scenes. Furthermore, we find that existing image datasets with textual captions can provide a surprisingly effective form of weak supervision for this task. We compare our method with existing sequential encoding and embedding networks, demonstrating superior performance on two proposed benchmarks: automatic image retrieval on a simulated scenario that uses region captions as queries, and interactive image retrieval using real queries from human evaluators.
Do Multi-hop Readers Dream of Reasoning Chains?
Oct 31, 2019


General Question Answering (QA) systems over texts require the multi-hop reasoning capability, i.e. the ability to reason with information collected from multiple passages to derive the answer. In this paper we conduct a systematic analysis to assess such an ability of various existing models proposed for multi-hop QA tasks. Specifically, our analysis investigates that whether providing the full reasoning chain of multiple passages, instead of just one final passage where the answer appears, could improve the performance of the existing QA models. Surprisingly, when using the additional evidence passages, the improvements of all the existing multi-hop reading approaches are rather limited, with the highest error reduction of 5.8% on F1 (corresponding to 1.3% absolute improvement) from the BERT model. To better understand whether the reasoning chains could indeed help find correct answers, we further develop a co-matching-based method that leads to 13.1% error reduction with passage chains when applied to two of our base readers (including BERT). Our results demonstrate the existence of the potential improvement using explicit multi-hop reasoning and the necessity to develop models with better reasoning abilities.
Multi-step Entity-centric Information Retrieval for Multi-Hop Question Answering
Sep 17, 2019
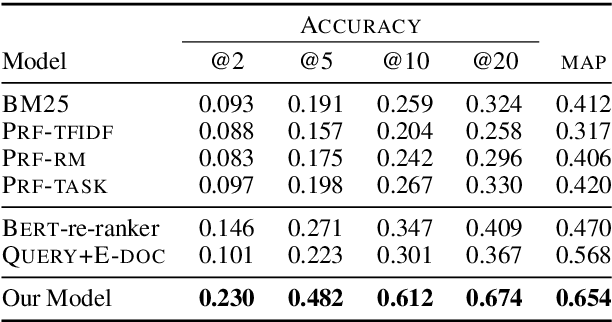
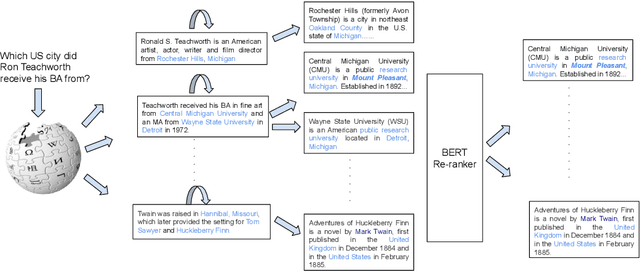
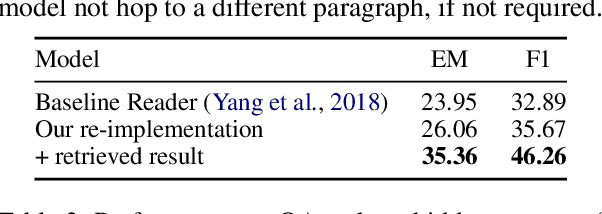
Multi-hop question answering (QA) requires an information retrieval (IR) system that can find \emph{multiple} supporting evidence needed to answer the question, making the retrieval process very challenging. This paper introduces an IR technique that uses information of entities present in the initially retrieved evidence to learn to `\emph{hop}' to other relevant evidence. In a setting, with more than \textbf{5 million} Wikipedia paragraphs, our approach leads to significant boost in retrieval performance. The retrieved evidence also increased the performance of an existing QA model (without any training) on the \hotpot benchmark by \textbf{10.59} F1.
Simple yet Effective Bridge Reasoning for Open-Domain Multi-Hop Question Answering
Sep 17, 2019



A key challenge of multi-hop question answering (QA) in the open-domain setting is to accurately retrieve the supporting passages from a large corpus. Existing work on open-domain QA typically relies on off-the-shelf information retrieval (IR) techniques to retrieve \textbf{answer passages}, i.e., the passages containing the groundtruth answers. However, IR-based approaches are insufficient for multi-hop questions, as the topic of the second or further hops is not explicitly covered by the question. To resolve this issue, we introduce a new sub-problem of open-domain multi-hop QA, which aims to recognize the bridge (\emph{i.e.}, the anchor that links to the answer passage) from the context of a set of start passages with a reading comprehension model. This model, the \textbf{bridge reasoner}, is trained with a weakly supervised signal and produces the candidate answer passages for the \textbf{passage reader} to extract the answer. On the full-wiki HotpotQA benchmark, we significantly improve the baseline method by 14 point F1. Without using any memory-inefficient contextual embeddings, our result is also competitive with the state-of-the-art that applies BERT in multiple modules.